







系列文章目录
本系列主要针对李宏毅老师2022年的《机器学习与深度学习》的课程做笔记,如果您上完对应章节的课,可以看看我的笔记以作回顾,由于水平有限,如有不对处,还望指教!
系列文章:
【笔记】李宏毅《机器学习基本概念简介(上)》笔记分享
【笔记】李宏毅《机器学习基本概念简介(下)》笔记分享
【笔记】李宏毅《反向传播(选修)》笔记分享
【笔记】李宏毅《预测神奇宝贝CP》笔记分享
【笔记】李宏毅《神奇宝贝分类 案列讲解入门》笔记分享
前言
这节课承接:神奇宝贝分类
通过这门课,学会了逻辑回归的基础知识、逻辑回归不用均方误差的原因、生成式模型与判别式模型的区别、将二分类问题延伸到了多分类问题、逻辑回归的限制性等知识。
1.sigmoid函数
承接上节课的那个先验概率公式,我们把先验公式进行一番转化,如下:
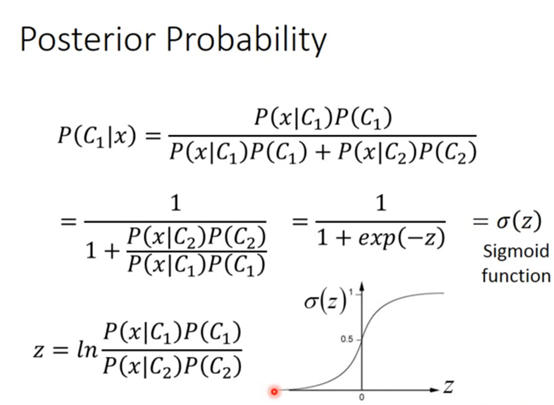
即引入之前课上讲的sigmoid函数
那这个z长什么样子呢?
经过一番复杂的数学运算(如下图):

可以得到z=wT+b
于是我们发现 能不能不舍近求远 直接把w和b给求出来 这就是这一节课 逻辑回归要讲的东西。
2.逻辑回归的三步走
什么是Logistic Regression?
同样是“三步走”,我们每一步与前面教的线性回归进行对比:
第一步,建立函数——

这里的σ就是很早之前讲过的sigmoid函数:
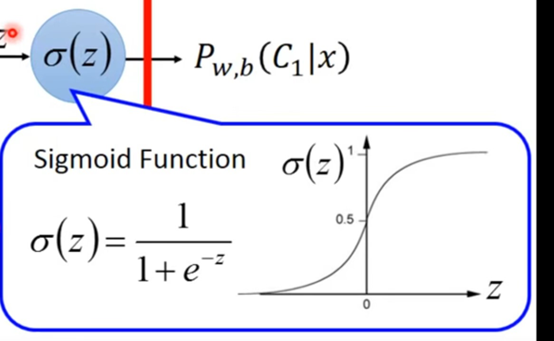
第二步 设计评估函数好坏
在逻辑回归中我们用的是交叉熵(注意与线性回归进行对比):

在这个神奇宝贝的分类中我们是两个贝努力分布的交叉熵
标签y要么是0(Class=1)要么是1(Class=2)
而f(x)是你模型去估计的结果 用交叉熵来评估function的好坏
这个公式的推导过程(又是复杂的数学计算,时间紧迫就没必要看,知道有这么个公式就行hhh):

把求最大值变为求最小值

第三步 找到最好的函数
接下里又是无聊但是复杂的数学计算:对我们的评估函数(是这么叫的么)对w求偏导:

这个式子也是符合常识的
y和f差距越大 梯度越大 那么更新幅度就越大
第三步逻辑回归与线性回归对比:
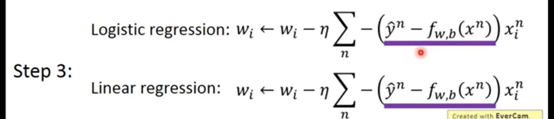
两个式子是一样的 唯一不同的就是逻辑回归的y非0即是1 线性的y可以是任何值
3.为什么逻辑回归损失不用均方误差(square error)而用交叉熵?
我们假设逻辑回归用均方误差:

可以看到,如果模型结果太接近或者太远离目标值,就会导致梯度极小(甚至为0),影响损失计算。
直观地,将交叉熵与均方误差在逻辑回归中的表现绘制如图:
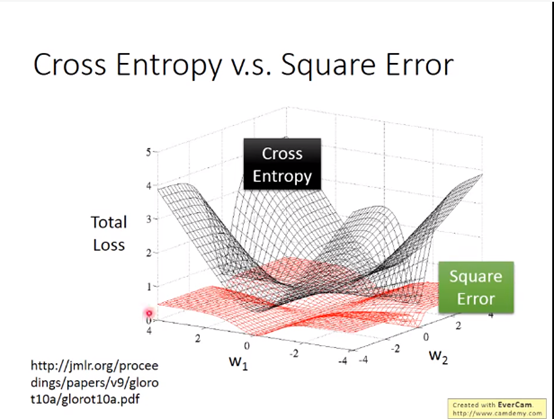
均方误差的话,如果离目标远的话,微分是很小的,你移动的速度是非常慢,优化速度很慢,而距离目标很近的时候移动也很慢,所以不好判断以调整learning rate,从而不容易得到好结果。
结论:均方误差适用于预测,而交叉熵适用于分类。
3.生成式模型vs判别式模型
这一部分内容参考了李宏毅机器学习自用笔记------逻辑回归
将两者进行对比:

上图展现了判别式和生成式的区别
对判别式来说我们需要优化的参数就是线性回归方程的w和b,而对生成式模型来说,我们需要通过训练的样本来找到μ和σ。
不过,巧合的是,如果我们用同一个Σ的话,正如上面所说,最后可以化简为一个线性回归的模型,其中w和b的表达式如上。
那么问题来了,这样算出来的w和b,与判别式优化出来的w和b相同吗?
答案显然是大概率不同。因为生成式我们做了一个假设,那就是假设概率模型为高斯分布,然后估计出μ,而生成式是用极大似然来得到的最好的w和b。
由于生成式模型对概率分布模型做了假设,所以一般情况下其效果没有判别式好。
但判别式模型受数据量影响较大,需要训练足够多模型才能准确,因此当训练数据较少时,生成式模型有一个类型预判,可能分类效果反而较好。且当label有噪声时,生成式模型预判的模型可以将噪声过滤掉,影响较小。
4.将二分类问题延伸到了多分类问题
这里李老师只讲了过程没讲原理:
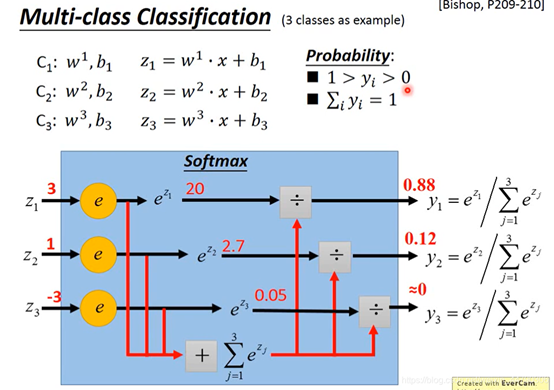
多分类使用的损失函数依然是交叉熵,3个类别的目标分别用one-hot向量(一个one-hot向量是一个二进制向量,其中只有一个元素为1,其他元素都为0)表示,防止用1,2,3表示相差太远。
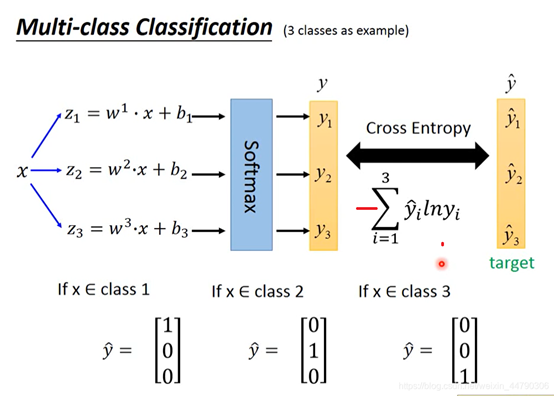
5.逻辑回归的限制性
逻辑回归其实有非常强的限制。什么样的限制呢?
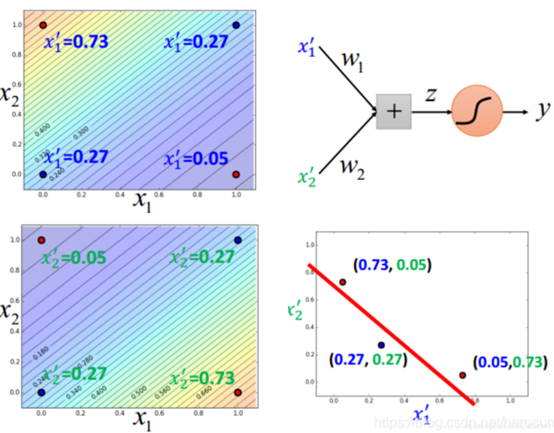
假设这样一种情况:有4个data,每个data有两个feature,这四个data分别属于两个class,如下图所示,这样的分类问题并不可以用逻辑回归实现。因为逻辑回归的分界线始终是一条直线,一条直线始终无法把红色的点和蓝色的点分成两个类别。
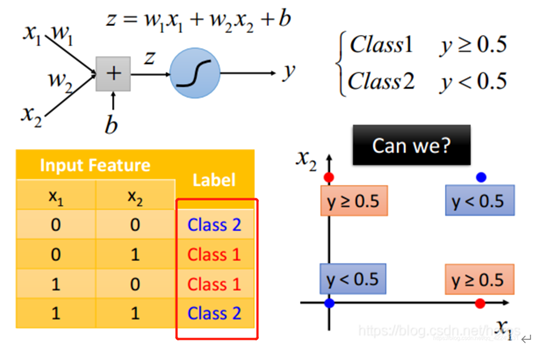
看, logistic regression就这样卡翻了
怎么办呢?
有一招叫Feature Transfomation,顾名思义就是把逻辑回归解决不了的多个feature问题,转化为一个其它形式的feature,
比如,上面的四个data,我们就可以用两个向量分别描述其到点(0,0)与(1,1)的距离:
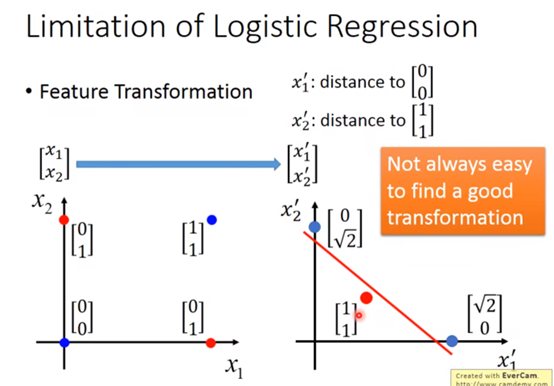
这样就可以创造出“一条线”,将蓝色的点和红色的点给分开
那么对于不同的问题,肯定是要进行不同的feature transformation,而这并不总是容易的,怎么办呢?
让机器学习啊!!!
我们考虑把很多个逻辑回归串联起来。如图所示,前两个逻辑回归进行特征转换的功能,最后一个逻辑回归进行分类功能。
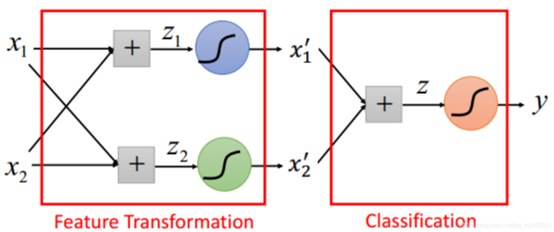
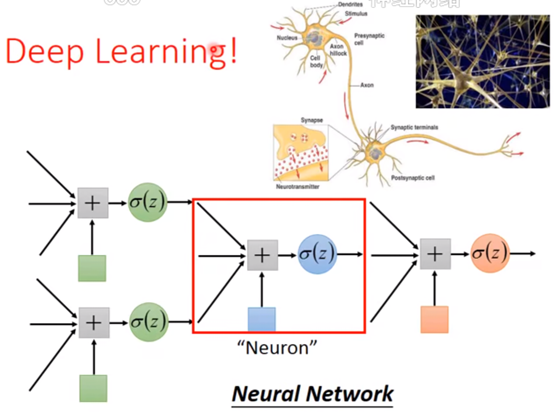
我们把一个逻辑回归叫做一个神经元,这些神经元形成的网络称为类神经网络。然后就又进入了deep learing.















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









