









[2022]李宏毅深度学习与机器学习第一讲(选修)听课笔记
做笔记的目的
1、监督自己把50多个小时的视频看下去,所以每看一部分内容做一下笔记,我认为这是比较有意义的一件事情。
2、路漫漫其修远兮,学习是不断重复和积累的过程。怕自己看完视频不及时做笔记,学习效果不好,因此想着做笔记,提高学习效果。
3、因为刚刚入门深度学习,听课的过程中,理解难免有偏差,也希望各位大佬指正。
深度学习介绍
发展趋势

Deep Learning的三个步骤

在第一步中,我们要自己决定结构

涉及的问题:
- 要多少个layer,每个layer要多少个neurons: 需要根据经验和不断自己尝试,所以DL让问题从抽取特征变为定义结构。之前很多工作都是关注在如何抽取特征,有DL之后主要是如何构造网络结构。
- 为什么DL在NLP上的效果并不是很好? 老师给的猜想是,人对于文本提取特征能力很强,人设计的规则可能就能达到一个比较不错的效果。但是长久而言,DL在NLP里面的应用还是很广阔的。
反向传播
首先是要记住什么是链式法则大概张这样。
计算的第一步从这里开始

考虑如何计算红框内的公式。

公式可以分为Forward pass和Backward pass
Forward pass 非常直观解释
x
1
x_1
x1,所以现在主要是算Backward pass。Backward pass的计算公式推导如下:

我们看输出层

输出层的梯度可以很快算出来,但是隐藏层是比较难算的。

所以,我们使用反向传播

先算输出层,然后往前算,这样就可以减少计算量了。所以整个计算梯度的过程是先前向传播,然后反向传播,两个相乘就出来了。

预测神奇宝贝CP,线性回归
第一步确定模型,这里是线性回归模型。

第二部,定义损失函数

第三步,找到比较好的
W
,
b
W,b
W,b

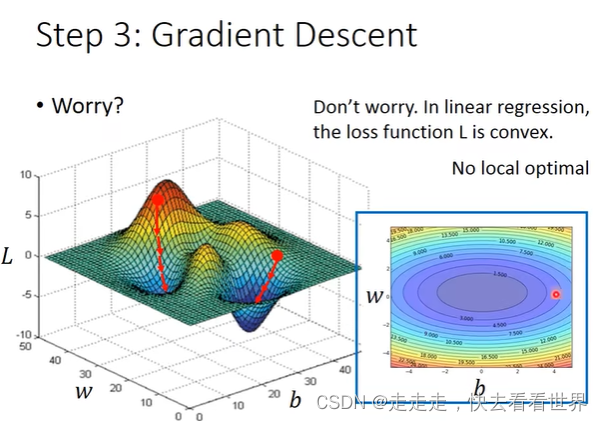
这里涉及到如何找,就是用梯度下降去更新。梯度下降有可能找到局部最优解,但是因为线性回归是类似与等高线,并不存在局部最优解,如图:
模型改进

改进方法是在第一步定义模型时,把模型弄得更加复杂就可以,但是模型太过于复杂有可能过拟合,如下图:

所以这里可以用到正则化技术,正则化技术就改变损失函数,改变后的损失函数会让模型变得更加平滑,那么为什么平滑的模型更好那?
因为平滑的输出并不非常依赖输入,可以提高扛噪音能力

这里涉及到一个问题,为什么这里正则化没有加上b,因为我们加入正则化是要让函数变平滑,但是这里加上b,只是上下移动,所以没有必要加上去。加入正则化之后的结果

从上图可以看出,我们喜欢平滑的Function,但是并不能太平滑,不然就成一条直线了。
神奇宝贝的分类
Generative Model

Generative model 需要提前人为设定,数据服从什么分布,这里给的是服从高斯分布。图中四个框里面的先验概率是非常容易算出来的。主要计算的是后验概率。我们假设服从高斯分布:

用最大似然估计去计算高斯分布的概率。

计算公式是可以推导出来,然后计算出来的。但是如果出现了过拟合。

改进方法,这个方法也是一般方法:让两个分布的
∑
\sum
∑一样,如下图:

改进之后变成了linear model

后面经过了一系列推导,把Generative Model与逻辑斯蒂回归联系起来了,推导过程如下图:



Discriminative Model
第一步简历Function

第二步定义损失函数,损失函数用的伯努利分布之间的交叉熵

逻辑斯蒂回归和线性归回对比

这里有一个问题,为什么逻辑斯蒂回归不用Square Error。

上面一段数学推导+举例子说明了,如果用Square Error那么离目标进的时候损失小这很OK,但是离目标远的时候损失也小。

在梯度下降的时候,当loss小的时候你并不知道是离目标远还是非常接近目标,很难去找到最优解。
Discriminative Vs Generative

两个模型都是算W和b,但是两个模型找到的W和b并不一样,一般而言判别式模型要比生成式模型好。但是也不一定。
这里老师总结了一下生成式模型的优点

- 提前知道符合什么分布同时训练数据少时,效果好
- 因为提前知道符合什么分布,所以鲁棒性好
- 先验概率和后验概率可以来源不同
Multi-class Classification
之间上做法

Softmax强化大的值,让大值更大,小值更小。
但是逻辑斯蒂回归做不到异或的任务,因为只是一条直线。

这里可以用Feature Transformation,但是Feature Transformation的设计是人为设计的,并不好想。

这里可以用一层layer来作feature Transformation

最好就变成了神经网络,多堆叠几个layer就成了深度神经网络。

11点开始写,写了两个小时终于写完了,下班,睡觉!















 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









