







加载数据集
import torch
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='data/TUDataset', name='MUTAG')
print()
print(f'Dataset: {dataset}:')
print('====================')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
data = dataset[0] # Get the first graph object.
print()
print(data)
print('=============================================================')
# Gather some statistics about the first graph.
print(f'Number of nodes: {data.num_nodes}')
print(f'Number of edges: {data.num_edges}')
print(f'Average node degree: {data.num_edges / data.num_nodes:.2f}')
print(f'Has isolated nodes: {data.has_isolated_nodes()}')
print(f'Has self-loops: {data.has_self_loops()}')
print(f'Is undirected: {data.is_undirected()}')该数据集共有188张图片,共分为两类。
第一张图片为:Data(edge_index=[2, 38], x=[17, 7], edge_attr=[38, 4], y=[1]):第一张图片有17个节点,38条边,标签为1,第一张图片的边也具有属性特征
划分训练集和测试集
torch.manual_seed(12345)
dataset = dataset.shuffle()
train_dataset = dataset[:150]
test_dataset = dataset[150:]
print(f'Number of training graphs: {len(train_dataset)}')
print(f'Number of test graphs: {len(test_dataset)}')将数据集中的图片先打乱顺序,shuffle()-->洗牌,然后划分训练集和测试集,将前150张图片划分为训练集,后38张图片划分为测试集
打包成mini-batch
from torch_geometric.loader import DataLoader
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
for step, data in enumerate(train_loader):
#enumerate的作用就是对可迭代的数据进行标号并将其里面的数据和标号一并打印出来。
print(f'Step {step + 1}:')
print('=======')
print(f'Number of graphs in the current batch: {data.num_graphs}')
print(data)
print()打包的原理:
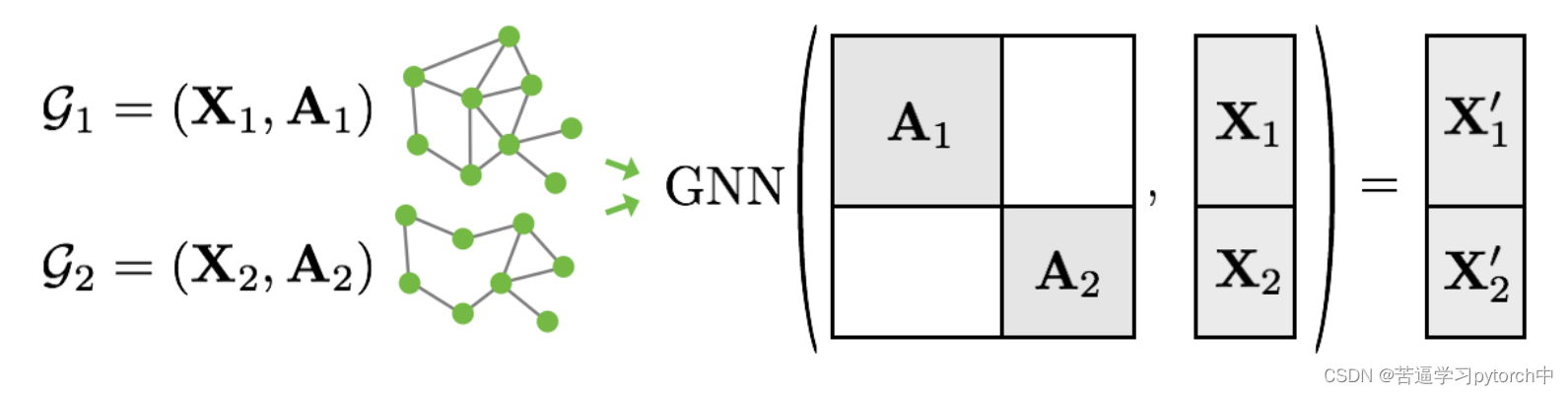
关于batch vector的理解:

例如:当打包好的data如下:
DataBatch(edge_index=[2, 932], x=[417, 7], edge_attr=[932, 4], y=[22], batch=[417], ptr=[23])
batch vector为一个417维的向量,因为该databatch中有417个点,一张图上的所有点编号相同。
例如,batch如下:

搭建模型框架
from torch.nn import Linear
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.nn import global_mean_pool
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super(GCN, self).__init__()
torch.manual_seed(12345)
self.conv1 = GCNConv(dataset.num_node_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, hidden_channels)
self.conv3 = GCNConv(hidden_channels, hidden_channels)
self.lin = Linear(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index, batch):
# 1. Obtain node embeddings
x = self.conv1(x, edge_index)
x = x.relu()
x = self.conv2(x, edge_index)
x = x.relu()
x = self.conv3(x, edge_index)
# 2. Readout layer
x = global_mean_pool(x, batch) # [batch_size, hidden_channels]
# 3. Apply a final classifier
x = F.dropout(x, p=0.5, training=self.training)
x = self.lin(x)
return x
model = GCN(hidden_channels=64)
print(model)global_mean_pool:全局平局池化,输出一张图的特征向量,
global_mean_pool(x: Tensor, batch: Optional[Tensor], size: Optional[int] = None)→ Tensor[
原理:
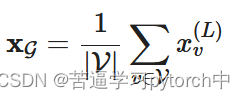
训练
from IPython.display import Javascript
display(Javascript('''google.colab.output.setIframeHeight(0, true, {maxHeight: 300})'''))
model = GCN(hidden_channels=64)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
for data in train_loader: # Iterate in batches over the training dataset.
out = model(data.x, data.edge_index, data.batch) # Perform a single forward pass.
loss = criterion(out, data.y) # Compute the loss.
loss.backward() # Derive gradients.
optimizer.step() # Update parameters based on gradients.
optimizer.zero_grad() # Clear gradients.
def test():
model.eval()
total_num_acc = 0
for data in test_loader:
output = model(data.x, data.edge_index, data.batch)
num_acc = (output.argmax(dim=1)==data.y).sum()
total_num_acc = total_num_acc + num_acc
acc=total_num_acc/len(test_data)
return acc
writer=SummaryWriter('./logs')
step=0
for epoch in range(200):
train()
loss=train()
test_acc=test()
writer.add_scalar('train-loss', loss, step)
writer.add_scalar('test_acc', test_acc, step)
if epoch%10==0:
print('Loss:{}, test_acc:{}'.format(loss, test_acc))
step=step+1
writer.close()
1.在运行程序的时候发现,当torch.manual_seed(12345)括号中数字不同时,测试集上的准确率相差很大,原因是什么呢?
2.什么时候用torch.manual_seed(12345)呢?















 2194
2194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









