






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Hdfs的命令
在集群上运行,即操作master:50070上的文件,包括上传、下载、复制
以hadoop fs 开头,只要start-all.sh,在根目录下输命令就行
常用命令实操
(0)启动Hadoop集群(方便后续的测试)
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
(1)-help:输出这个命令参数
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -help rm
(2)-ls: 显示目录信息
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -ls /
(3)-mkdir:在HDFS上创建目录
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mkdir -p /sanguo/shuguo
(4)-moveFromLocal:从本地剪切粘贴到HDFS
[atguigu@hadoop102 hadoop-2.7.2]$ touch kongming.txt
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
(5)-appendToFile:追加一个文件到已经存在的文件末尾
[atguigu@hadoop102 hadoop-2.7.2]$ touch liubei.txt
[atguigu@hadoop102 hadoop-2.7.2]$ vi liubei.txt
输入
san gu mao lu
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
(6)-cat:显示文件内容
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cat /sanguo/shuguo/kongming.txt
(7)-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo/kongming.txt
(8)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
这里和下面的-cp不一样,-cp是在集群内的操作,这里是从本地上传到集群
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -copyFromLocal README.txt /
(9)-copyToLocal:从HDFS拷贝到本地
hadoop fs -copyToLocal 本地路径 集群路径
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./
(10)-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt
(11)-mv:在HDFS目录中移动文件
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mv /zhuge.txt /sanguo/shuguo/
(12)-get:等同于copyToLocal,就是从HDFS下载文件到本地
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -get /sanguo/shuguo/kongming.txt ./
(13)-getmerge:合并下载多个文件,比如HDFS的目录 /user/atguigu/test下有多个文件:log.1, log.2,log.3,…
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -getmerge /user/atguigu/test/* ./zaiyiqi.txt
(14)-put:等同于copyFromLocal
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -put ./zaiyiqi.txt /user/atguigu/test/
(15)-tail:显示一个文件的末尾
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -tail /sanguo/shuguo/kongming.txt
(16)-rm:删除文件或文件夹(文件夹是-rmr)
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -rm /user/atguigu/test/jinlian2.txt
(17)-rmdir:删除空目录
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -mkdir /test
[atguigu@hadoop102 hadoop-2.7.2]$ hadoop fs -rmdir /test
HDFS还有api操作需要增加和注意的地方看安装过程
MapReduce
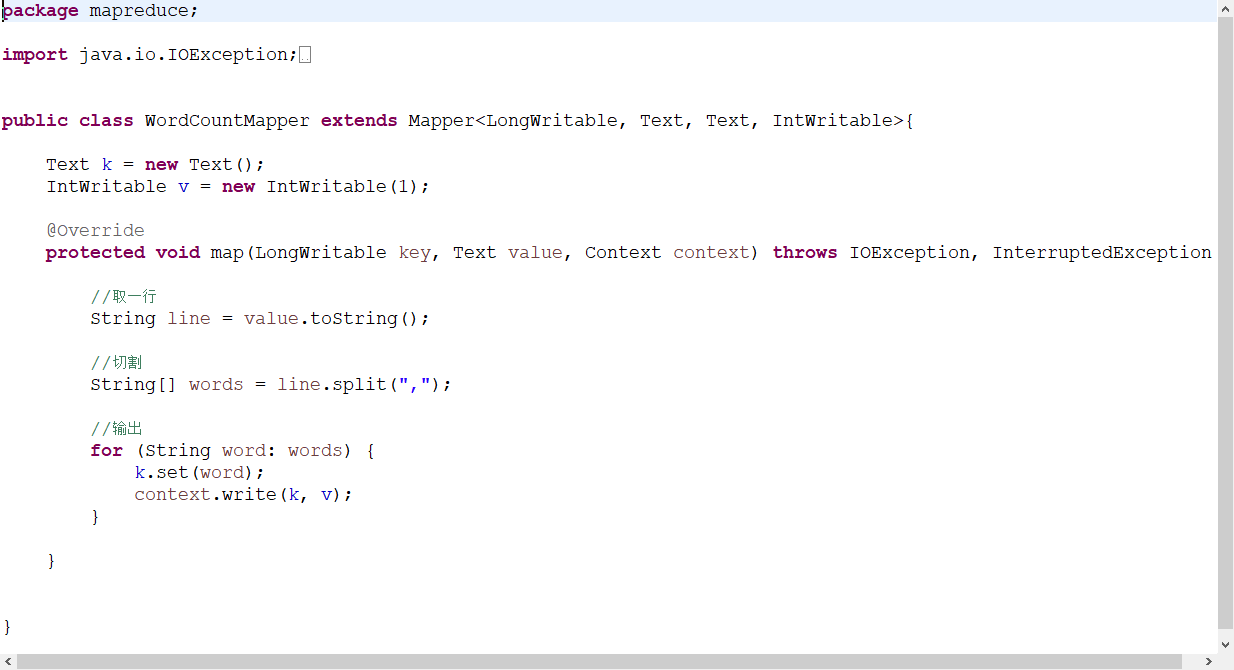
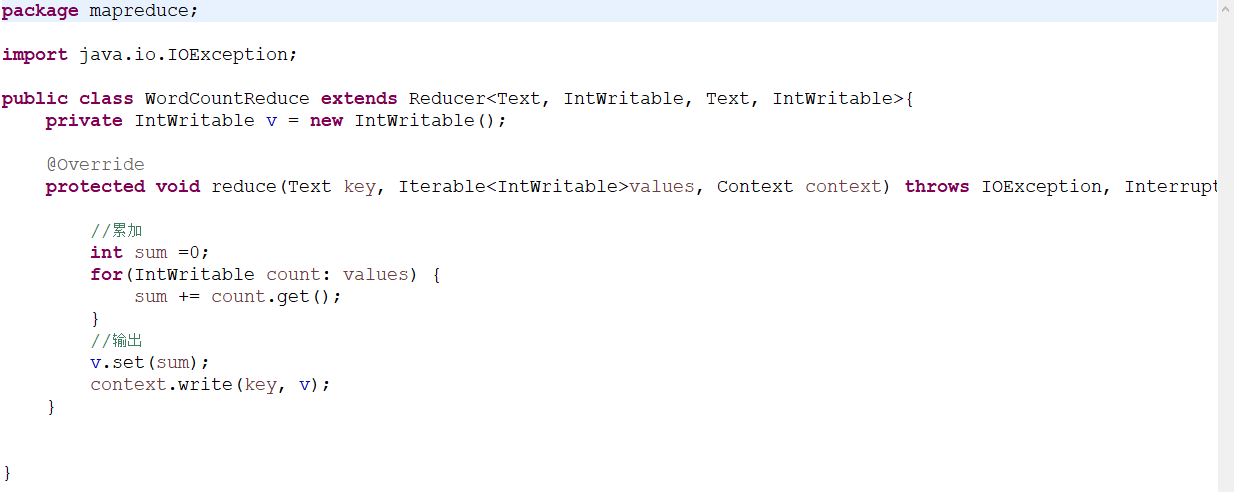
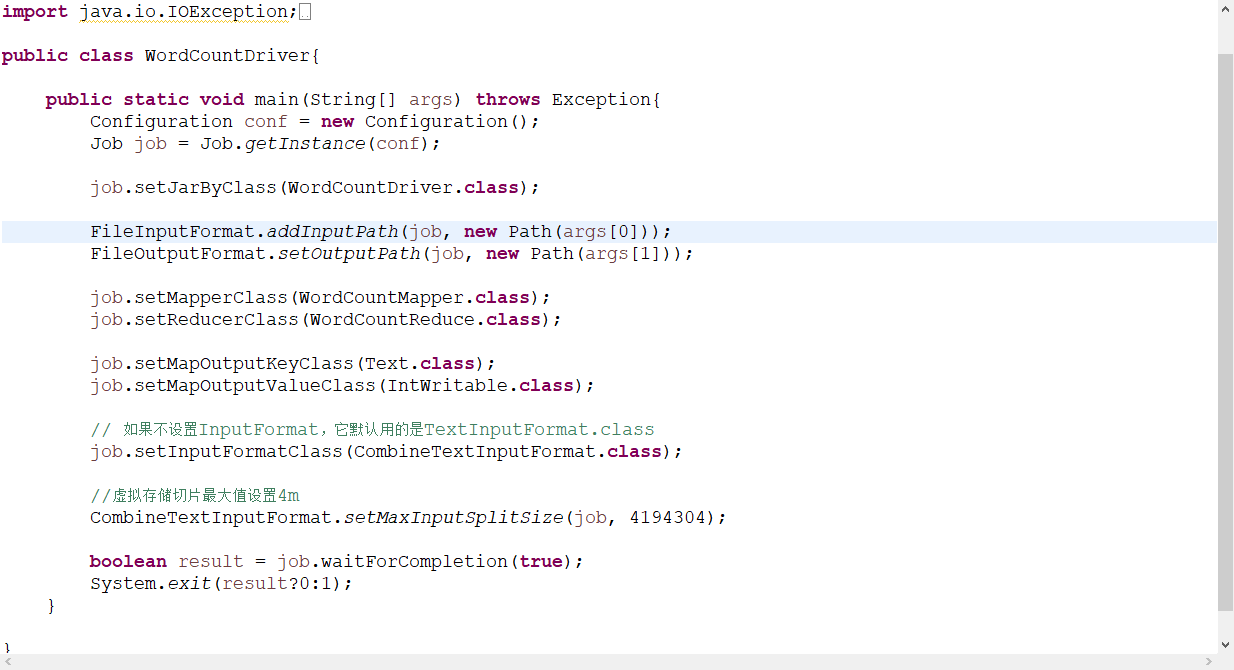
1、wordcount
本地运行
在run configrations的arguments 增加输入输出位置
查看part-r-00000即可
Hadoop集群运行
1、对整个项目project用export导出,选择jar,输入名字,即可生成jar包
2、用rz命令将jar包和数据文件1.txt 上传到虚拟机
3、用-mkdir –p 在集群上创建input 目录,-copyFromLocal 将1.txt 上传到集群的input
4、最后用jar命令运行,注意中间的类名要包括包名package(例子是mapreduce)
[root@master ~]# hadoop fs -mkdir -p /input
[root@master ~]# hadoop fs -copyFromLocal ~/hadooptest/input/1.txt /input
[root@master ~]# hadoop jar ~/hadooptest/mrdemo.jar mapreduce.WordCountDriver /input/1.txt /output
可用-cat查看
反序列化例子要加一个空参构造的FlowBean,否则后面无法打印,会被默认传入两个参数
这里其实有点疑惑,两个一样名字的函数又不会报错是为什么呢?
Mapreduce
主要分三个阶段
1、map阶段
主要处理文件,拆分文件内容
2、reduce阶段
计算阶段,比如计算词数,或者排序
3、driver阶段
主要是job调动,调动前两个阶段,指定路径,指定输入输出类型















 1685
1685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









