






【导读】GPT-4o mini头把交椅还未坐热,Mistral AI联手英伟达发布12B参数小模型Mistral Nemo,性能赶超Gemma 2 9B和Llama 3 8B。
小模型,成为本周的AI爆点。
先是HuggingFace推出了小模型SmoLLM;OpenAI直接杀入小模型战场,发布了GPT-4o mini。
GPT-4o mini发布同天,欧洲最强AI初创公司Mistral立马发布旗下最新最强小模型——Mistral NeMo。

Mistral NeMo由Mistral AI和英伟达联手打造,有12B参数,支持128K上下文。
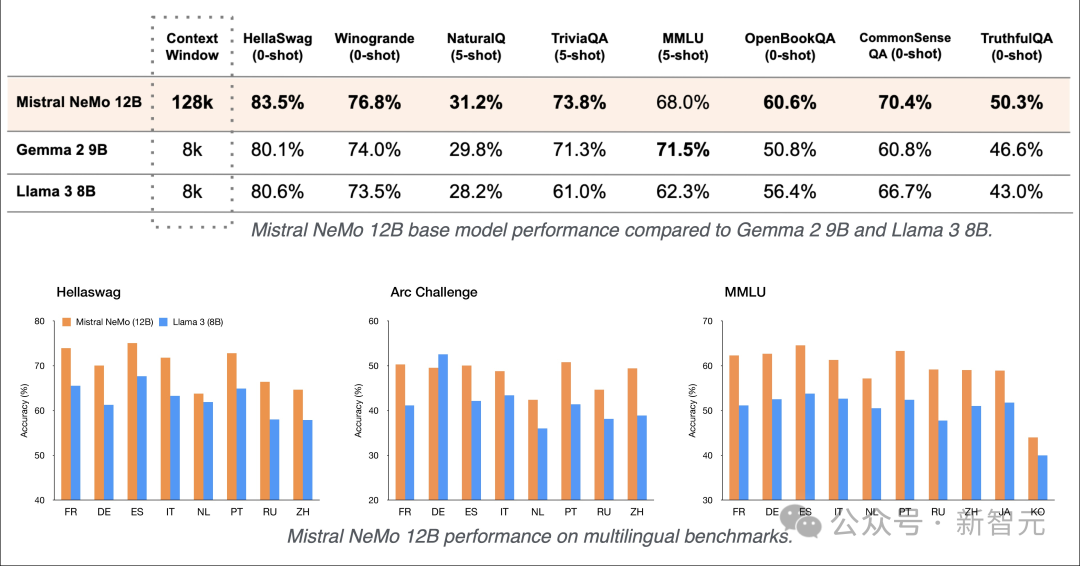
从整体性能上来看,Mistral NeMo在多项基准测试中,击败了Gemma 2 9B和Llama 3 8B。
看到各大巨头和独角兽都和小模型杠上了,吃瓜群众纷纷鼓掌。
HuggingFace创始人表示,本周巨头小模型三连发,「小模型周」来了!卷!继续卷!

Mistral这周的确像打了鸡血,火力全开。
几天前,Mistral才发布了两款小模型,专为数学推理和科学发现设计的Mathstral 7B和代码模型Codestral Mamba,是首批采用Mamba 2架构的开源模型之一。
没想到周这只是平A了两下热热场子,还和老黄憋着大招等待闪亮登场。
1+1>2?
最新发布的小模型Mistral NeMo 12B,瞄准企业用户的使用。
开发人员可以轻松定制和部署支持聊天机器人、多语言任务、编码和摘要的企业应用程序。
通过将Mistral AI在训练数据方面的专业知识,与英伟达优化的硬件和软件生态系统相结合,「最强爹妈」培养出的娃,Mistral NeMo模型性能极其优秀。
Mistral AI联合创始人兼首席科学家Guillaume Lample表示,「我们很幸运能够与英伟达团队合作,利用他们的顶级硬件和软件。」

Mistral NeMo在NVIDIA DGX Cloud AI平台完成了训练,该平台提供对最新英伟达架构的专用和可扩展访问。
加速大语言模型推理性能的NVIDIA TensorRT-LLM,以及构建自定义生成AI模型的NVIDIA NeMo开发平台也用于推进和优化新模型的性能。
此次合作也凸显了英伟达对支持模型构建器生态系统的承诺。
企业赛道,卓越性能
Mistral NeMo支持128K上下文,能够更加连贯、准确地处理广泛且复杂的信息,确保输出与上下文相关。
与同等参数规模模型相比,它的推理、世界知识和编码准确性都处于领先地位。
下表结果所示,除了在MMLU基准上,Mistral NeMo不如Gemma 2 9B。
但在多轮对话、数学、常识推理、世界知识和编码等基准中,超越了Gemma 2 9B和Llama 3 8B。

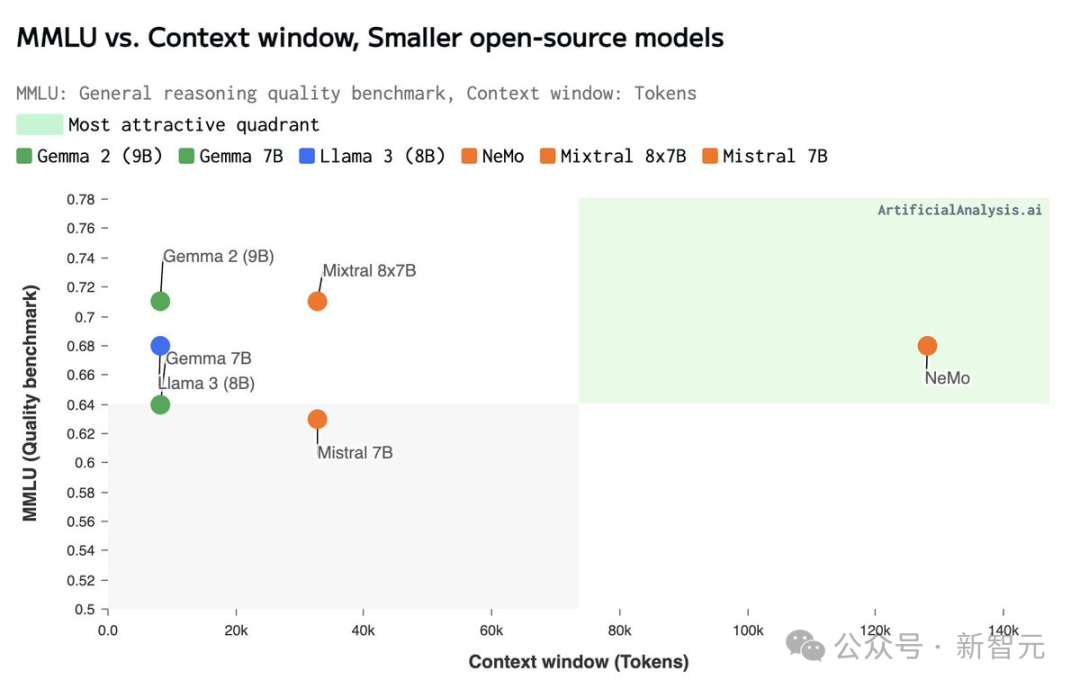
由于Mistral NeMo使用标准架构,因此兼容性强,易于使用,并且可以直接替代任何使用Mistral 7B的系统。
Mistral NeMo是一个拥有120亿参数的模型,根据Apache 2.0许可证发布,任何人皆可下载使用。

此外,模型使用FP8数据格式进行模型推理,这可以减少内存大小并加快部署速度,而不会降低准确性。
这意味着,模型可以流畅丝滑地学习任务,并更有效地处理不同的场景,使其成为企业的理想选择。
这种格式可以在任何地方轻松部署,各种应用程序都能灵活使用。
因此,模型可以在几分钟内,部署到任何地方,免去等待和设备限制的烦恼。
Mistral NeMo瞄准企业用户的使用,采用属于NVIDIA AI Enterprise一部分的企业级软件,具有专用功能分支、严格的验证流程以及企业级安全性的支持。
开放模型许可证也允许企业将Mistral NeMo无缝集成到商业应用程序中。
Mistral NeMo NIM专为安装在单个NVIDIA L40S、NVIDIA GeForce RTX 4090或NVIDIA RTX 4500 GPU的内存上而设计,高效率低成本,并且保障安全性和隐私性。
也就是说,单个英伟达L40S,一块GPU就可跑了。

对于希望实现先进人工智能的企业来说,Mistral NeMo 12B提供了强大且实用的组合技。
先进模型的开发和定制
Mistral AI和英伟达各自擅长的领域结合,优化了Mistral NeMo的训练和推理。
模型利用Mistral AI的专业知识进行训练,尤其是在多语言、代码和多轮内容方面,受益于英伟达全堆栈的加速训练。
它专为实现最佳性能而设计,利用高效的模型并行技术、可扩展性以及与Megatron-LM的混合精度。
该模型使用NVIDIA NeMo的一部分Megatron-LM进行训练,在DGX Cloud上配备3,072个H100 80GB Tensor Core GPU,由NVIDIA AI架构组成,包括加速计算、网络结构和软件,以提高训练效率。
面向大众的多语言模型
Mistral NeMo模型专为全球多语言应用程序而设计。
它经过函数调用训练,具有较大的上下文窗口,并且在英语、法语、德语、西班牙语、意大利语、葡萄牙语、中文、日语、韩语、阿拉伯语和印地语多语言方面性能强大。
可以说,这是将前沿人工智能模型带到全世界不同语言使用者手中的重要一步。
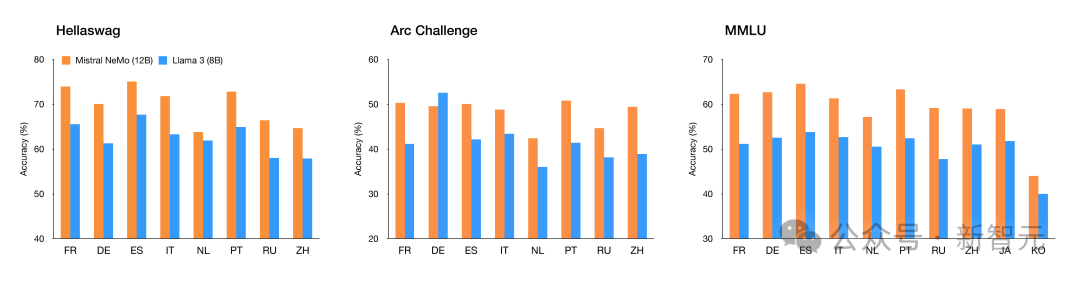
Mistral NeMo在多语言基准测试中的表现
Tekken:更高效的分词器
Mistral NeMo使用基于Tiktoken的全新分词器——Tekken,该分词器已针对100多种语言进行训练,并且比以前的Mistral模型中使用的SentencePiece分词器更有效地压缩自然语言文本和源代码。
具体而言,在压缩源代码、中文、意大利语、法语、德语、西班牙语和俄语方面的效率提高了约30%;
在压缩韩语和阿拉伯语方面的效率也分别提高了2倍和3倍。与Llama 3分词器相比,Tekken在压缩大约85%的所有语言的文本方面表现更为出色。

Tekken压缩率
指令微调
Mistral NeMo已经经过了高级微调和对齐阶段。与Mistral 7B相比,它在遵循精确指令、推理、处理多轮对话和生成代码方面表现得更好。

Mistral NeMo指令微调模型精度,使用GPT-4o作为官方参考的评判标准进行评估
可用性和部署
凭借在云、数据中心或RTX工作站等任何地方运行的灵活性,Mistral NeMo已准备好成为彻底改变跨平台使用AI应用程序的先锋。
用户可以立即通过ai.nvidia.com作为NVIDIA NIM体验Mistral NeMo,可下载的NIM版本即将推出。
有网友已经迫不及待在英伟达NIM推理微服务中运行了Mistral NeMo 12B。

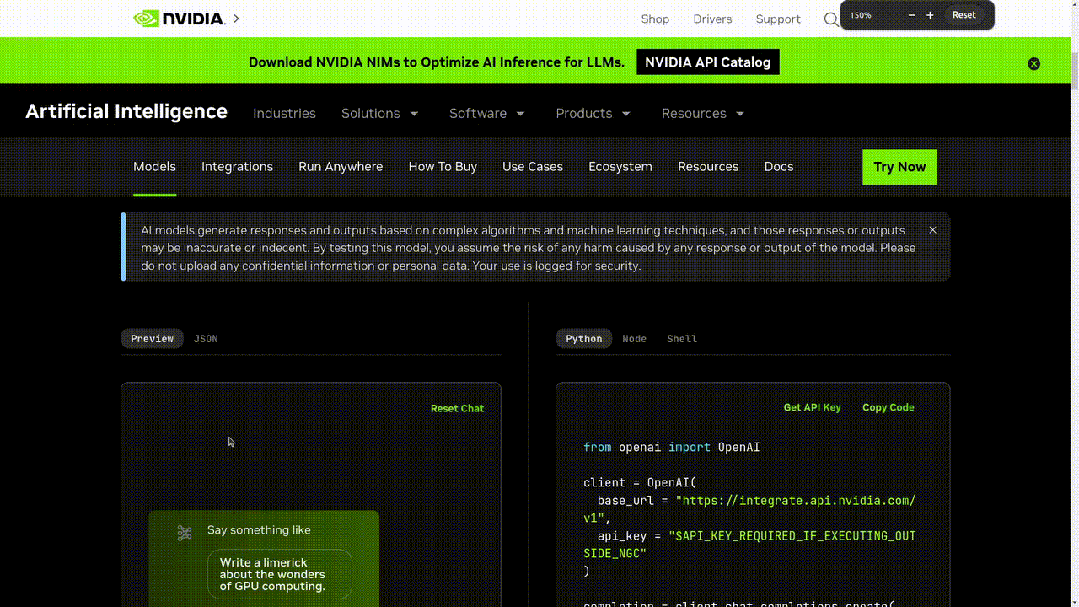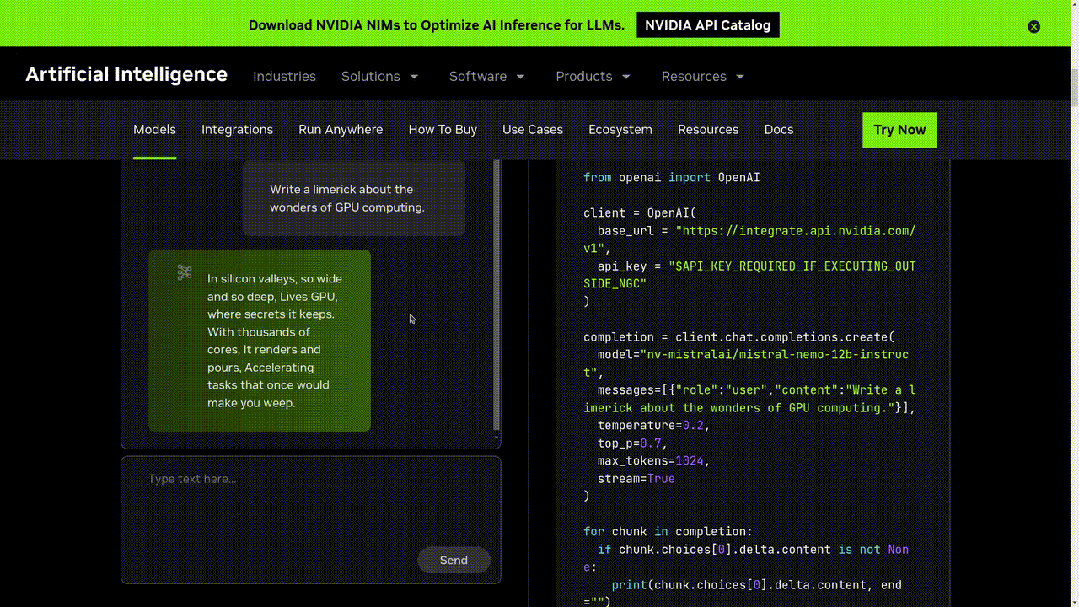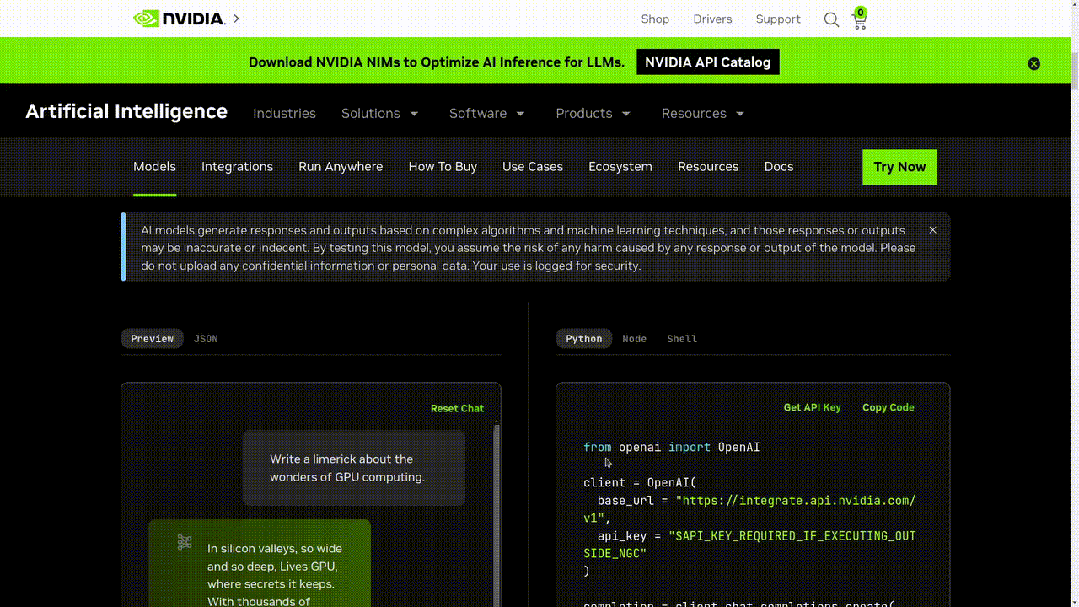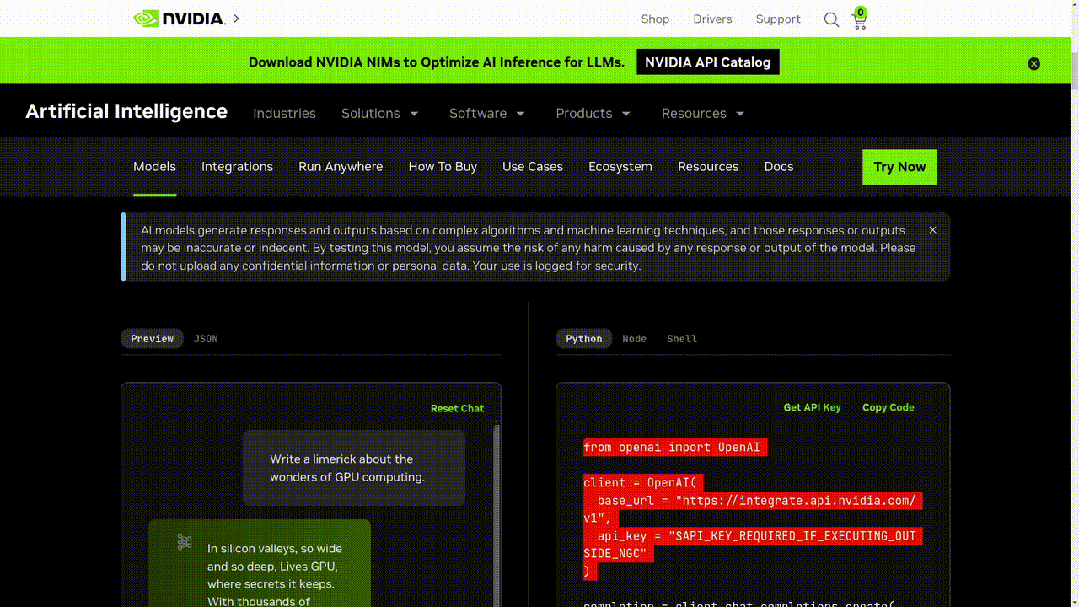
开发者现在可以使用mistral-inference试用Mistral NeMo,并使用mistral-finetune对其进行微调。
Mistral NeMo在La Plateforme上以open-mistral-nemo-2407的名称公开。
参考资料:
https://blogs.nvidia.com/blog/mistral-nvidia-ai-model/?ncid=so-twit-243298&linkId=100000274370636
https://x.com/arthurmensch/status/1813949845704745223
https://x.com/theo_gervet/status/1813951882815000628
https://x.com/ClementDelangue/status/1813962747056652515















 1115
1115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









