









hadoop/hive-生产问题记录
reduce端出现 java.lang.OutOfMemoryError: Direct buffer memory
描述
MR数据量级大,reduce端Direct buffer memory:
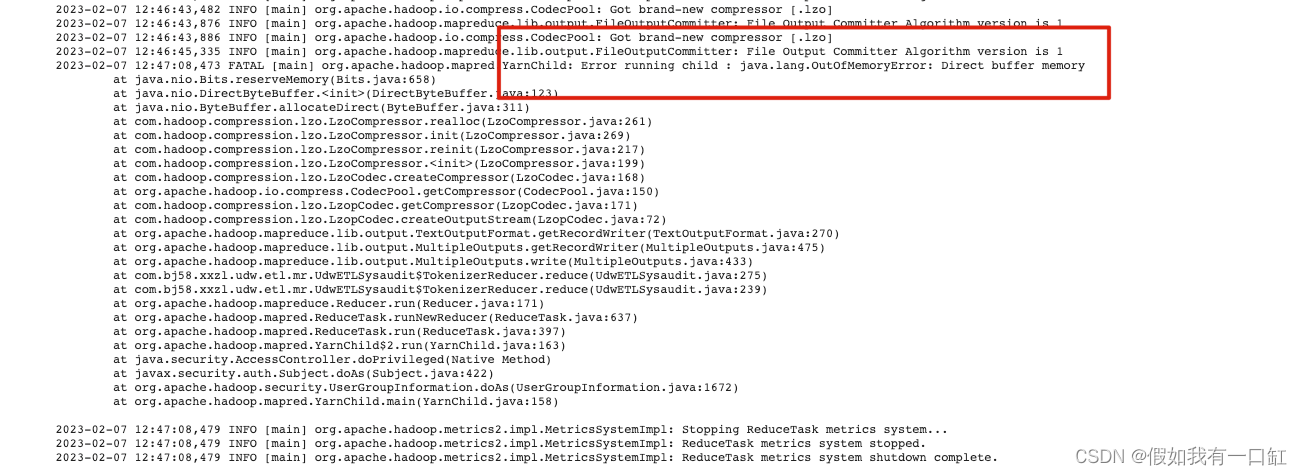
这种情况最好找到configration对应参数,并提高。
解决
在MR任务的yarn UI->Configuration中,搜索 direct 相关的参数:
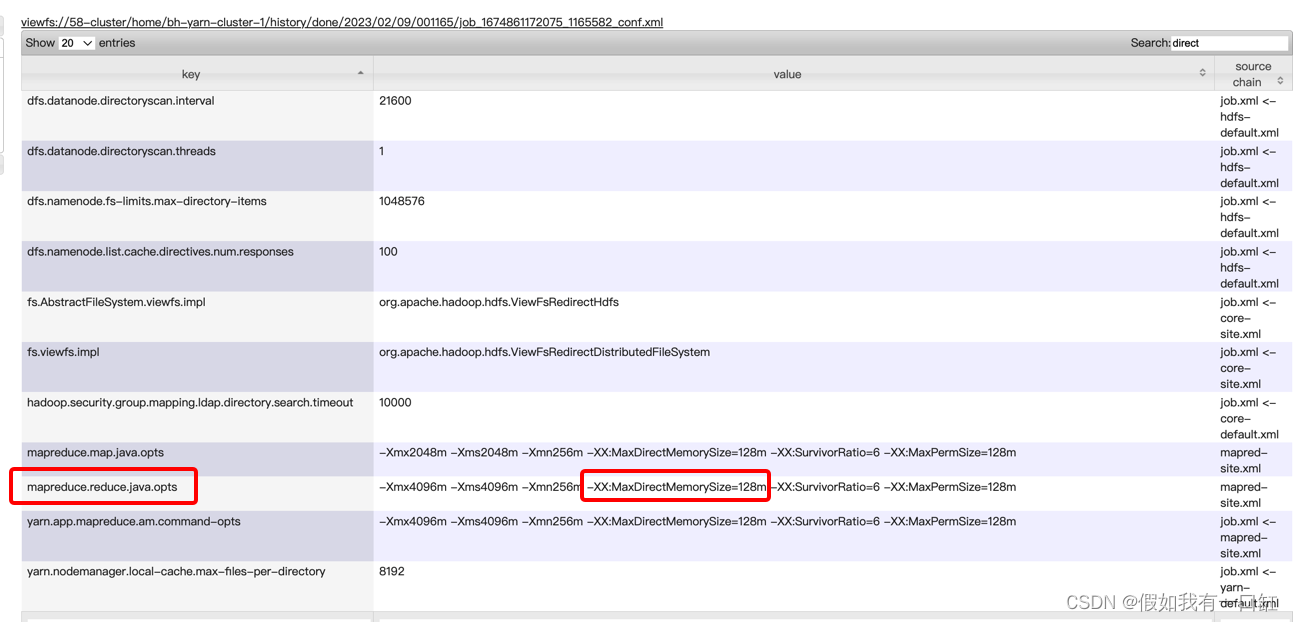
发现使用mapreduce.reduce.java.opts参数来控制reduce端的Direct Memory。
所以在MR main方法中修改mapreduce.reduce.java.opts,把 -XX:MaxDirectMemorySize的值增大到640m:
conf.set("mapreduce.reduce.java.opts",
"-Xmx4096m -Xms4096m -Xmn256m -XX:MaxDirectMemorySize=640m -XX:SurvivorRatio=6 -XX:MaxPermSize=128m -XX:ParallelGCThreads=10");
任务运行成功。
hive在读取lzo压缩文件且有index索引的情况下,map端没有进行切片
描述
数据源表的文件使用了lzo压缩,且增加了索引,单个文件大小在10000MB左右:
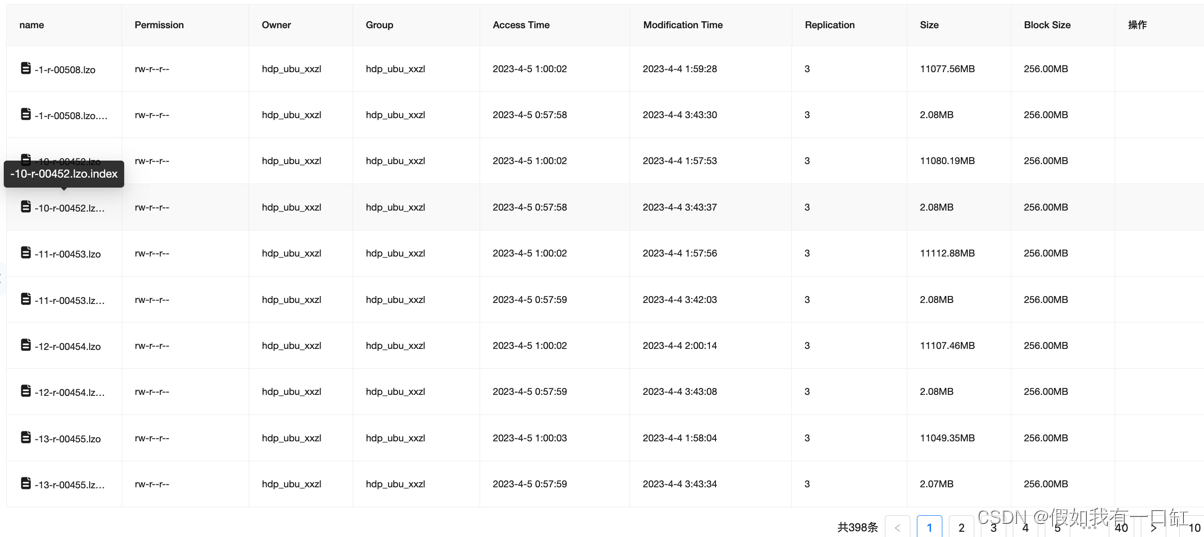
写sql读取的时候,发现map端没有对文件进行切割,map数量等于文件数,运行非常缓慢,耗时1h9m:
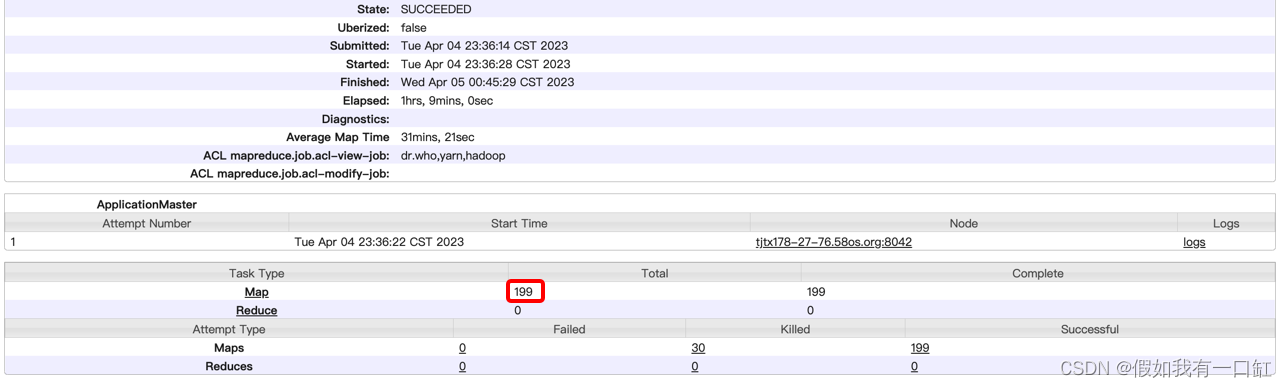
解决
hive脚本需要设置inputFormat:
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
再次运行发现map端进行了文件切割,map数量增加,耗时14m:
参考资料: hive 里面不能split lzo的文件,这是怎么回事?
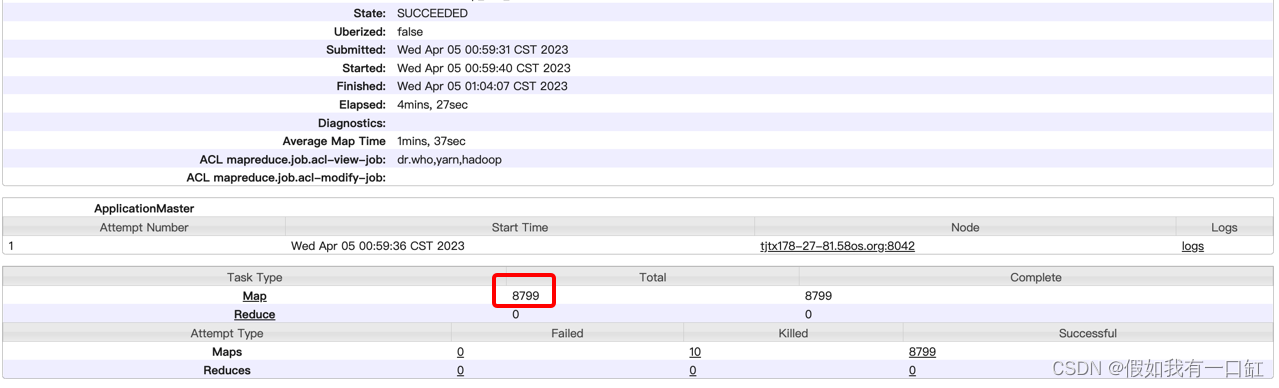
hive开启map join
描述
在使用一张大表join小表时,由于关联的key分布极度不均,导致reduce端数据倾斜,reduce端发生 java.lang.OutOfMemoryError: Java heap space
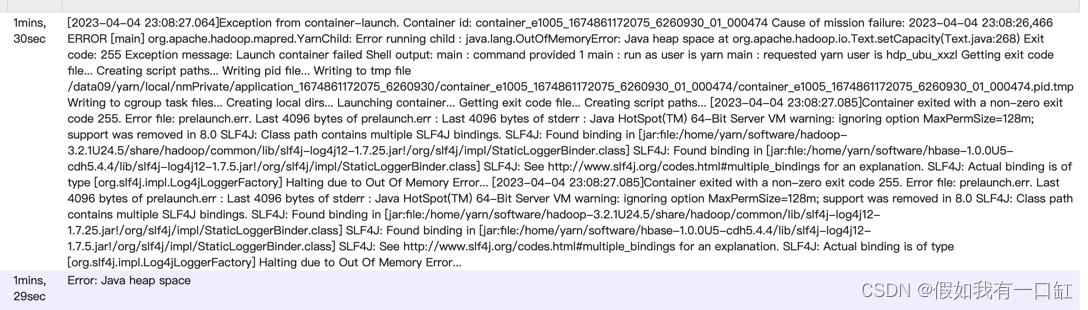
解决
由于用到的小表的数据量较小,在100MB左右,而大表的大小在1TB左右,所以考虑使用map join来避免shuffle后的数据倾斜问题
1.设置参数:
-- 开启自动map join
set hive.auto.convert.join=true;
-- 设置map join中小表的数据量上限,确保能把小表“广播”出去
set hive.mapjoin.smalltable.filesize=250000000;
2.调整sql
需要将小表放在join前面
select
...
from
小表
right join
打标
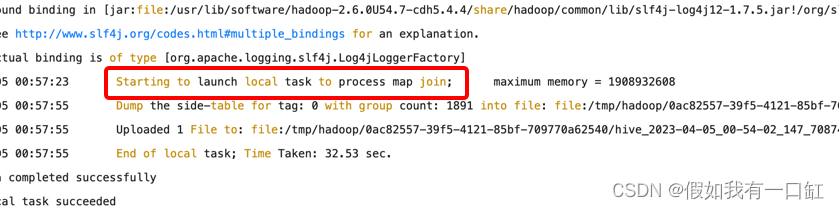
修改后发现开始了map join,成功运行且耗时较短:
hive数据倾斜表象:Table 0 has 10000 rows for join key [0,0]
有hive任务发生数据倾斜,reduce端一直99%,有一个reduce任务卡主了。
打开这个reduce任务的log日志,发现如下日志:
[INFO] org.apache.hadoop.hive.ql.exec.JoinOperator: Table 0 has 10000 rows for join key [0,0]
打开hive源码定为输入日志行:
if (sz == nextSz) {
LOG.info("Table {} has {} rows for join key {}", alias, sz, keyObject);
nextSz = getNextSize(nextSz);
}
输出的类是org.apache.hadoop.hive.ql.exec.JoinOperator,是hive中join运算符的实现类,具体运行机制尚不清楚。
查询资料得知,当一个key关联了超过1000行时,会输出一条该警告日志,此后每1000会输出一条。所以这条日志的目的在于警告可能存在的Join数据倾斜的风险。
参考资料: hive JoinOperator















 502
502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









