







Spark/SparkSQL-生产问题汇总
Failed to get records for groupId topic partition offset after polling for 120000
描述
这是一个Sparkstreaming的异常,公司实时抽检任务最近经常报这个错:
23/03/09 18:33:16 WARN scheduler.TaskSetManager task-result-getter-0: Lost task 8.0 in stage 2535.0 (TID 81635, tjtx162-23-46.58os.org, executor 21): java.lang.IllegalArgumentException: requirement failed: Failed to get records for spark-executor-hdp_ubu_xxzl-hdp_sampling03182614-2a7a-4d89-b288-736f1428085e hdp_ubu_xxzl_dw_v_neirongzhuaqu_di 3 134565737 after polling for 120000
at scala.Predef$.require(Predef.scala:224)
at org.apache.spark.streaming.kafka010.CachedKafkaConsumer.get(CachedKafkaConsumer.scala:72)
at org.apache.spark.streaming.kafka010.KafkaRDDIterator.next(KafkaRDD.scala:271)
at org.apache.spark.streaming.kafka010.KafkaRDDIterator.next(KafkaRDD.scala:231)
at scala.collection.Iterator$$anon$11.next(Iterator.scala:409)
at org.apache.spark.storage.memory.MemoryStore.putIteratorAsBytes(MemoryStore.scala:379)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1111)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1085)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1020)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1085)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:811)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:332)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.rdd.UnionRDD.compute(UnionRDD.scala:107)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:334)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:332)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1$$anonfun$apply$10.apply(BlockManager.scala:1132)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1$$anonfun$apply$10.apply(BlockManager.scala:1130)
at org.apache.spark.storage.DiskStore.put(DiskStore.scala:69)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1130)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1085)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1020)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1085)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:811)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:332)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:334)
at org.apache.spark.rdd.RDD$$anonfun$7.apply(RDD.scala:332)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1094)
at org.apache.spark.storage.BlockManager$$anonfun$doPutIterator$1.apply(BlockManager.scala:1085)
at org.apache.spark.storage.BlockManager.doPut(BlockManager.scala:1020)
at org.apache.spark.storage.BlockManager.doPutIterator(BlockManager.scala:1085)
at org.apache.spark.storage.BlockManager.getOrElseUpdate(BlockManager.scala:811)
at org.apache.spark.rdd.RDD.getOrCompute(RDD.scala:332)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:283)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:49)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:321)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:285)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:89)
at org.apache.spark.scheduler.Task.run(Task.scala:111)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:365)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
原因
spark版本为2.3.2,定位到源码的位置,在CachedKafkaConsumer类中,这个类在KafkaRDD中的KafkaRDDIterator迭代器中承担着kafka消费者的作用。
private class KafkaRDDIterator[K, V](
part: KafkaRDDPartition,
context: TaskContext,
kafkaParams: ju.Map[String, Object],
useConsumerCache: Boolean,
pollTimeout: Long,
cacheInitialCapacity: Int,
cacheMaxCapacity: Int,
cacheLoadFactor: Float
) extends Iterator[ConsumerRecord[K, V]] {
val groupId = kafkaParams.get(ConsumerConfig.GROUP_ID_CONFIG).asInstanceOf[String]
context.addTaskCompletionListener(_ => closeIfNeeded())
// 构建一个CachedKafkaConsumer
val consumer = if (useConsumerCache) {
CachedKafkaConsumer.init(cacheInitialCapacity, cacheMaxCapacity, cacheLoadFactor)
if (context.attemptNumber >= 1) {
// just in case the prior attempt failures were cache related
CachedKafkaConsumer.remove(groupId, part.topic, part.partition)
}
CachedKafkaConsumer.get[K, V](groupId, part.topic, part.partition, kafkaParams)
} else {
CachedKafkaConsumer.getUncached[K, V](groupId, part.topic, part.partition, kafkaParams)
}
var requestOffset = part.fromOffset
def closeIfNeeded(): Unit = {
if (!useConsumerCache && consumer != null) {
consumer.close()
}
}
override def hasNext(): Boolean = requestOffset < part.untilOffset
// 获取迭代器的下一个值,在这里是调用get方法,返回的是消费者消费下一批消息
override def next(): ConsumerRecord[K, V] = {
if (!hasNext) {
throw new ju.NoSuchElementException("Can't call getNext() once untilOffset has been reached")
}
val r: ConsumerRecord[K, V] = consumer.get(requestOffset, pollTimeout)
requestOffset += 1
r
}
}
在CachedKafkaConsumer#get方法中进行了如下操作:
1.调用poll方法通过KafkaConsumer拉取数据,并将拉取回来的消息放入了buffer当中。
2.判断buffer中有没有消息,没有的话再poll一次
3.在判断buffer中有没有消息,还没有的话就抛出异常
protected var buffer = ju.Collections.emptyListIterator[ConsumerRecord[K, V]]()
/**
* Get the record for the given offset, waiting up to timeout ms if IO is necessary.
* Sequential forward access will use buffers, but random access will be horribly inefficient.
*/
def get(offset: Long, timeout: Long): ConsumerRecord[K, V] = {
logDebug(s"Get $groupId $topic $partition nextOffset $nextOffset requested $offset")
if (offset != nextOffset) {
logInfo(s"Initial fetch for $groupId $topic $partition $offset")
seek(offset)
poll(timeout)
}
if (!buffer.hasNext()) { poll(timeout) }
require(buffer.hasNext(), // 抛异常的位置
s"Failed to get records for $groupId $topic $partition $offset after polling for $timeout")
var record = buffer.next()
if (record.offset != offset) {
logInfo(s"Buffer miss for $groupId $topic $partition $offset")
seek(offset)
poll(timeout)
require(buffer.hasNext(),
s"Failed to get records for $groupId $topic $partition $offset after polling for $timeout")
record = buffer.next()
require(record.offset == offset,
s"Got wrong record for $groupId $topic $partition even after seeking to offset $offset " +
s"got offset ${record.offset} instead. If this is a compacted topic, consider enabling " +
"spark.streaming.kafka.allowNonConsecutiveOffsets"
)
}
nextOffset = offset + 1
record
}
// 拉取消息并放入buffer
private def poll(timeout: Long): Unit = {
val p = consumer.poll(timeout)
val r = p.records(topicPartition)
logDebug(s"Polled ${p.partitions()} ${r.size}")
buffer = r.listIterator
}
所以这个异常的原因就是Sparkstreaming的消费者没有从kafka中消费到数据(连续两次poll拉取数据),原因是这个topic中流量很少,切好在一段时间内没有生产任何消息,导致抛出了异常。
解决方法
先提高poll时的timeout参数的值,超时时间增大一点。这个参数是被spark.streaming.kafka.consumer.poll.ms和spark.network.timeout共同控制的,由于我的任务没有指定这两个参数,所以使用的是默认值120s。先将这个值提升到300s看看情况。
private val pollTimeout = conf.getLong("spark.streaming.kafka.consumer.poll.ms",
conf.getTimeAsMs("spark.network.timeout", "120s"))
注意:该参数必须那必须能被windowDuration和slideDuration,否则会有问题:
Time 1678363020000 ms is invalid as zeroTime is 1678362720000 ms , slideDuration is 600000 ms and difference is 300000 ms
sparksql CustomShuffleReader partition数量太小
描述
sparksql任务,大表join小表之后,写入hive中。
发现在写入hive之前的一个阶段执行非常缓慢。该阶段并行度为5,但数据量约20TB,肯定跑不动。。。
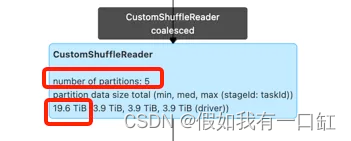
这一阶段在执行计划中叫CustomShuffleReader,查询资料后得知这是Spark AQE的一个优化,目的是将数据量较小分区进行动态合并。在我的任务中,它将20TB的数据量合并成了5个分区。。。
原因应该是合并的时候一些参数不正确,试着通过调参解决。
解决
找到以下参数:
--conf spark.sql.adaptive.maxNumPostShufflePartitions=800
--conf spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum=200
参数1:spark.sql.adaptive.maxNumPostShufflePartitions
该参数为spark AQE中关于动态shuffle partition的一个控制参数,可以增加/减少task数量。主要解决动态shuffle过程中,因为task数量少,spill导致OOM的情况。也是解决stage级别的数据倾斜的一种优化参数(小萝卜有文章说过)。
参数1:spark.sql.optimizer.dynamicPartitionInsertionRepartitionNum
该参数是为了避免数据倾斜的参数,控制动态分区中的文件数。
加上参数之后,发现CustomShuffleReader的分区数增加到了170,速度运行速度明显增加。
开启笛卡尔积
set spark.sql.crossJoin.enabled=true;
开启后,join产生笛卡尔积时就不会失败了。















 668
668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









