







- Hive调优作用:在保证业务结果不变的前提下,降低资源的使用量,减少任务的执行时间。
1、调优须知
(1)对于大数据计算引擎来说:数据量大不是问题,数据倾斜是个问题。
(2)Hive的复杂HQL底层会转换成多个MapReduce Job并行或者串行执行,Job数比较多的作业运行效 率相对比较低,比如即使只有几百行数据的表,如果多次关联多次汇总,产生十几个Job,耗时很长。 原因是 MapReduce 作业初始化的时间是比较长的。
(3)在进行Hive大数据分析时,常见的聚合操作比如sum,count,max,min,UDAF等 ,不怕数据倾斜问题**,MapReduce 在 Mappe阶段 的预聚合操作,使数据倾斜不成问题**。 (4)好的建表设计,模型设计事半功倍。
(5)设置合理的 MapReduce 的 Task 并行度,能有效提升性能。(比如,10w+数据量 级别的计算,用 100 个 reduceTask,那是相当的浪费,1个足够,但是如果是 亿级别的数据量,那么1个Task又显得捉 襟见肘)
(6)了解数据分布,自己动手解决数据倾斜问题是个不错的选择。这是通用的算法优化,但算法优化有 时不能适应特定业务背景,开发人员了解业务,了解数据,可以通过业务逻辑精确有效的解决数据倾斜 问题。
(7)对小文件进行合并,是行之有效的提高调度效率的方法,假如所有的作业设置合理的文件数,对任务的整体调度效率也会产生积极的正向影响
(8)优化时把握整体,单个作业最优不如整体最优。
2、Hive的建表设计层面
2.1、建表类型 - 分区VS分桶
(1)分区表
当一个 Hive 表的查询大多数情况下,会根据某一个字段进行筛选时,那么非常适合创建为 分区表,该字段即为分区字段。
- 应用场景:数据基本上只会分析增量数据,不会分析全量数据,则应该按照时间来分区
(2)分桶表
指将数据以指定列的值为 key 进行 hash,hash 到指定数目的桶中,这样做的 目的和分区表类似,使得筛选时不用全局遍历所有的数据,只需要遍历所在桶就可以了
- 应用场景:AB试验数据采样、Join数据倾斜
2.2、选择合适的文件存储格式
- 优化方案:、表的文件存储格式尽量采用Parquet或ORC,不仅降低存储量,还优化了查询,压缩,表关联等性能
(1)TextFile : 每一行都是一条记录,每行都以换行符(\ n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
(2)SequenceFile : 是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
(3)RCFile : 是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
ORCFile : ORC文件格式提供了一种将数据存储在Hive表中的高效方法。这个文件系统实际(4)上是为了克服其他Hive文件格式的限制而设计的。Hive从大型表读取,写入和处理数据时,使用ORC文件可以提高性能。
(5)Parquet : 一个面向列的二进制文件格式。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。
| 存储格式 | 存储方式 | 特点 |
|---|---|---|
| TextFile | 行存储 | 存储空间消耗比较大,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高 |
| SequenceFile | 行存储 | 存储空间消耗最大,压缩的文件可以分割和合 ,查询效率高,需要通过text文件转化来加载,适合全量表的读取 |
| RCFile | 数据按行分块 每块按照列存储 | 存储空间最小,查询的效率最高 ,需要通过text文件转化来加载,加载的速度最低。压缩快 快速列存取。读记录尽量涉及到的block最少,读取需要的列只需要读取每个row group 的头部定义。 读取全量数据的操作 性能可能比sequencefile没有明显的优势 |
| ORCFile | 数据按行分块 每块按照列存储 | ORC File会基于列创建索引,当查询的时候会很快 |
| Parquet | 列存储 | 相对于ORC,Parquet压缩比较低,查询效率较低,不支持update、insert和ACID.但是Parquet支持Impala查询引擎 |
2.3、选择合适的文件压缩格式
- 含义:Hive 语句最终是转化为 MapReduce 程序来执行的,而 MapReduce 的性能瓶颈在与 网络IO 和 磁盘 IO,要解决性能瓶颈,最主要的是减少数据量,对数据进行压缩是个好方式。
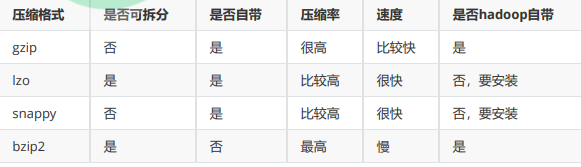
(1)压缩比:压缩比越高,压缩后文件越小,所以压缩比越高越好
(2)压缩时间:越快越好
(3)已经压缩的格式文件是否可以再分割:可以分割的格式允许单一文件由多个Mapper程序处理,可以更好的并行化
- 是否压缩的前提
1、计算密集型,不压缩,否则进一步增加了CPU的负担
2、网络密集型,推荐压缩,减小网络数据传输
3、HiveSQL语句优化
3.1、列裁剪
- 含义: Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。【裁剪所对应的参数项为:hive.optimize.cp=true(默认值为真)】
set hive.optimize.cp = true; ## 列裁剪,取数只取查询中需要用到的列,默认是true
- 主要作用:节省了读取开销,中间表存储开销和数据整合开销。【减少磁盘读写开销、网络IO开销】
3.2、谓词下推
- 含义:将 SQL 语句中的 where 谓词逻辑都尽可能提前执行,减少下游处理的数据量。对应逻辑优化器是 PredicatePushDown。
set hive.optimize.ppd=true; ## 默认是true
select a.*, b.* from a join b on a.id = b.id where b.age > 20;
#优化后
select a.*, c.* from a join (select * from b where age > 20) c on a.id = c.id
3.3、分区裁剪
- 含义: 可以在查询的过程中减少不必要的分区。【分区参数为:hive.optimize.pruner=true(默认值为真)】
set hive.optimize.pruner=true; ## 默认是true
- 主要作用:减少读取开销以及中间表存储开销和数据整合开销,减少磁盘IO与网络IO
3.4、合并小文件
- 含义:合理设置map数量,map数又和文件块数量有关,一个文件块对应一个map,小文件过多势必造成启动map任务和初始划的时间远远大于逻辑处理时间,所以在map执行前合并小文件,减少map数
# 1、在 map only 的任务结束时合并小文件
set hive.merge.mapfiles = true
# 2、true 时在 MapReduce 的任务结束时合并小文件
set hive.merge.mapredfiles = false
# 3、合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
# 4、每个 Map 最大分割大小
set mapred.max.split.size=256000000;
# 5、一个节点上 split 的最少值
set mapred.min.split.size.per.node=1;
# 6、执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- 注意事项:
- ①默认情况先把这个节点上的所有数据进行合并,如果合并的那个文件的大小超过了256M就开启另外一个文 件继续合并
- ②如果当前这个节点上的数据不足256M,那么就都合并成一个逻辑切片。
3.5、合理设置MapTask并行度
3.6、合理控制ReduceTask并行度
3.7、Join优化
3.8、Group By优化
- 含义:Map端部分聚合:事实上并不是所有的聚合操作都需要在 Reduce 部分进行,很多聚合操作都可以先在 Map 端进行部分 聚合,然后在 Reduce 端的得出最终结果。
## 开启Map端聚合参数设置
set hive.map.aggr=true;
# 设置map端预聚合的行数阈值,超过该值就会分拆job,默认值100000
set hive.groupby.mapaggr.checkinterval=100000
3.9、Order By优化
-
含义:order by 只能是在一个 reduce 进程中进行,所以如果对一个大数据集进行 order by ,会导致一个 reduce 进程中处理的数据相当大,造成查询执行缓慢。
-
解决方案:分桶后进行区间排序
如果是取排序后的前N条数据,可以使用distribute by和sort by在各个reduce上进行排序后前N 条,然后再对各个reduce的结果集合合并后在一个reduce中全局排序,再取前N条,因为参与全局排序的 order by的数据量最多是reduce个数 * N,所以执行效率会有很大提升。
4、Hive配置参数(Hive架构层面)
4.1、Fetch抓取
Fetch抓取:Hive中对某些情况的查询可以不必使用MapReduce计算,在全局查找、字段查找、limit查找等都不走mapreduce。
(1)把hive.fetch.task.conversion设置成none,然后执行查询语句,都会执行mapreduce程序。
hive (default)> **set hive.fetch.task.conversion=none;**
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;
(2)把hive.fetch.task.conversion设置成more,如下查询方式都不会执行mapreduce程序。
hive (default)> **set hive.fetch.task.conversion=more;**
hive (default)> select * from emp;
hive (default)> select ename from emp;
hive (default)> select ename from emp limit 3;
4.2、本地执行优化
对于小数据集,可以通过本地模式,在单台机器上处理所有任务,执行时间明显被缩短。
## 打开hive自动判断是否启动本地模式的开关
set hive.exec.mode.local.auto=true;
## map任务数最大值,不启用本地模式的task最大个数
set hive.exec.mode.local.auto.input.files.max=4;
## map输入文件最大大小,不启动本地模式的最大输入文件大小
set hive.exec.mode.local.auto.inputbytes.max=134217728;
4.3、JVM重用
如果任务花费时间很短,又要多次启动 JVM 的情况下,JVM 的启动时间会变成一个比较大的消耗,这时,可以通过重用 JVM 来解决。
set mapred.job.reuse.jvm.num.tasks=5;
- 注意事项:JVM也是有缺点的,开启JVM重用会一直占用使用到的 task 的插槽,以便进行重用,直到任务完成后才 会释放。
4.4、并行度优化
- 含义:**Hive会将一个查询转化成一个或者多个阶段,MapReduce阶段、抽样阶段、合并阶段、limit阶段,默认情况hive一次只会执行一个阶段。**而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。
set hive.exec.parallel=true; #打开任务并行执行
set hive.exec.parallel.thread.number=16; #同一个sql允许最大并行度,默认为8。
4.5、推测执行
Hadoop采用了推测执行(Speculative Execution)机制,它 根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
# 启动mapper阶段的推测执行机制
set mapreduce.map.speculative=true;
# 启动reducer阶段的推测执行机制
set mapreduce.reduce.speculative=true;
- 注意事项:如果用户因为输入数据量很大而需要执行长时间的 mapTask 或者 reduceTask 的话,那么启动推测执行造成的浪费是非常巨大。
5、Hive数据倾斜
5.1、数据倾斜定义
数据分布不均,造成大量数据集中到一点,造成数据热点。
5.2、数据倾斜的表现
(1)在执行任务的时候,任务进度长时间维持在99%左右;
(2)查看stage的执行情况时,卡在最后1-2个task长时间不动,查看task监控页面,发现某个或某两三个task运行的时间远远大于其他task的运行时间,这些task处理的数据量也远远大于其他task。
- 注意事项:关于Hive On Spark,一个spark任务的运行时间是由最后一个执行成功的task决定的,如果某个task发生了数据倾斜,会拖慢整个spark任务执行效率,即便其他没有倾斜的task已经执行完毕,甚至会导致OOM
3、查看数据倾斜方法
在yarn界面查看是否产生数据倾斜:

上图是yarn界面task的监控页面,从上图可以看出大部分task的执行时间是25s,处理记录数为几万到几十万不等(处理数据量大部分为几兆到几十兆),但是有一个task处理时间为1小时处理数据量高达72G且还没执行完,此时可以推断数据发生了倾斜,可以通过group by或者抽样找出倾斜key。
4、数据倾斜条件
数据计算时发生了shuffle,即对数据进行了重新分区。
| 关键词 | 情形 | 后果 |
|---|---|---|
| join | 某个或某几个key比较集中,或者存在大量null key | 分发到某一个或者某几个Reduce上的数据远高于平均值 |
| group by | 维度过小,某值的数量过多 | 某个维度或者某几个维度且这些维度的数据量特别大,集中在一个reduce |
5、数据倾斜的解决方案
5.1、特殊情形处理
①同数据类型关联产生数据倾斜
-
情形:比如用户表中user_id字段为int,log表中user_id字段string类型。当按照user_id进行两个表的Join操作时。
-
解决方式:把数字类型转换成字符串类型
select * from users a
left outer join logs b
on a.usr_id = cast(b.user_id as string)
②null key不参与关联
select
a.*
from(
select
*
from log
where user_id is not null
) a
join
users b on a.user_id = b.user_id
union all
select
*
from log where user_id is null
③数据加盐:赋予null值随机值
1. select *
2. from log a
3. left outer join users b
4. on case when a.user_id is null then concat('hive',rand() ) else a.user_id end = b.user_id;
- 两种方式优缺点比较
方法2比方法1效率更好,不但io少了,而且作业数也少了。
解决方法1中 log读取两次,jobs是2。解决方法2 job数是1 ;
这个优化适合无效 id (比如 -99 , ’’, null 等) 产生的倾斜问题。
把空值的 key 变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
④提高reduce并行度
设置reduce个数:set mapred.reduce.tasks=15,可以通过改参数提高reduce端并行度,从而缓解数据倾斜的情况。
Ⅰ、未优化前,假设key1、key2、key3、key4的数据量都是50w,key5是10w,此时key1和key3shuffle到了一个reduce,key2和key4shuffle到了一个reduce,导致有两个reduce task需要处理100w数据,而有一个task只需要处理10w数据,此时数据出现了10倍的倾斜。

Ⅱ、优化后,如图所示,为优化前reduce的并行度为3,单个task处理的最大数据量为100w,现在将并行度提高到5,单个task处理的最大数据量为50w,相比之前缓解了5倍的倾斜程度。此方案适合倾斜的程度不是很严重,并有两个以上的倾斜key到shuffle到了同一个reduce。

5.2、group by导致的数据倾斜
(1)开启负载均衡
- 含义:有数据倾斜的时候进行负载均衡(默认是false)
set hive.groupby.skewindata = true
- 当选项设定为 true,生成的查询计划会有两个MR Job。
①第一个MR Job:Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;
②第二个MR Job:根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
(2)group by 双重聚合
当使用group by进行聚合统计时,如果存在某个或某几个key发生了倾斜,会导致某个倾斜key shuffle到一个reduce。

select
split(sp_app_id,'_')[0] sp_app_id
,sum(pv)
from
(
select
sp_app_id||'_'||CAST(CAST(MOD(rand() * 10000,10) AS BIGINT) AS STRING) sp_app_id
,sum(nvl(op_cnt, 1)) pv
from t1
group by sp_app_id||'_'||CAST(CAST(MOD(rand() * 10000,10) AS BIGINT) AS STRING)
) group by split(sp_app_id,'_')[0]
5.3、join导致的数据倾斜
(1)reduce join 转换成 map join(此方案适合小表join大表的时候)
select /+ mapjoin(t2)/ column from table
(2)过滤倾斜join单独进行join(此方案适合大表关联达标)
所以如果把倾斜key过滤出来单独去join,这个倾斜key就会分散到多个task去进行join操作,最后union all。

select
*
from
(
select
*
from t1
where rowkey <> '123456789'
) a1 join a2 on a1.rowkey = a2.rowkey
union all
select
*
from
(
select
*
from t1
where rowkey = '123456789'
)a1 join a2 on a1.rowkey = a2.rowkey
③md5+分桶处理进行关联(PB级别数据关联PB级别数据,提效100倍+)
- 热点数据处理方式:热点数据直接过滤出来分开Join,md5(key1,Key2)后分桶关联
5.4、企业实战案例之日志表和用户表做连接
- 业务场景:事实表和维度表做关联,即大表关联小表,但是不能直接使用mapJoin
(1)实际业务需求
users 表有 600w+ (假设有5G)的记录,把 users 分发到所有的 map 上也是个不小的开销,而且 MapJoin 不支持这么大的小表。如果用普通的 join,又会碰到数据倾斜的问题。
(2)解决方案
- 原理:提前排除user表中的没用的ID,减少小表的数据量 ==》可以分别建立用户的全量表/天级全量表
①先得到过滤的userid
select distinct user_id from log ==》 a
②再获取有日志记录得以用户的信息
select b.* from a join users b on a.user_id = b.user_id; ==》b
③让C表与log表做关联
select /*+mapjoin(x)*/ * from log c left outer join d
on a.user_id = x.user_id;
5.5、企业实战案例之位图法求连续七天的朋友圈用户
- 业务场景:事实表和事实表做关联,即大表关联大表
(1)实际业务需求
每天都要求 微信朋友圈 过去连续7天都发了朋友圈的小伙伴有哪些? 假设每个用户每发一次朋友圈都记录了一条日志。每一条朋友圈包含的内容:
日期,用户ID,朋友圈内容.....
dt, userid, content, .....
如果 微信朋友圈的 日志数据,按照日期做了分区。
2020-07-06 file1.log(可能会非常大)
2020-07-05 file2.log
.......
(2)解決方案
- 原理:位图法BitMaps,即维护一个位数组
假设微信有10E用户,我们每天生成一个长度为10E的二进制数组,每个位置要么是0,要么是1,如果为1,代
表该用户当天发了朋友圈。如果为0,代表没有发朋友圈。
然后每天:10E / 8 / 1024 / 1024 = 119M左右
求Join实现:两个数组做 求且、求或、异或、求反、求新增
5.6、企业实战案例之用户留存
- 业务场景:事实表与实时表做关联,即大表关联大表
(1)实际业务需求
一般在运营或者BI报表里面,关于渠道用户分析时,用户留存是个不可缺少的过程,也是业界多渠道用户质量比较成熟的判断标准,主要指标,包括计算用户次日、3日、7日、30天、90天等的留存率。
- 指标说明:用户留存率 -今天新增了100名用户,第二天登陆了50名,则次日留存率为50/100=50%,第三天登录了30名,则第二日留存率为30/100=30%
(2)解决方案
- 原理:建立天级全量用户表
步骤一:从数据库中提取user_id和login_time, 并计算 first_day, 用于存储每个用户ID最早登录日期(最小日期);
步骤二:用登录日期-最早登录日期,得到每个登录日期距离最早登录日期的时间间隔,即留存日期;
步骤三:对不同留存日期的user_id进行汇总就是留存人数,除以首日登录人数,就得到了不同留存时间的留存率。
select
a.dt
,count(distinct a.id) as `日活跃用户`
,count(distinct b.id) as `次日留存数`
,count(distinct c.id) as `三日留存数`
,count(distinct d.id) as `七日留存数`
,concat(round(count(distinct b.id) / count(distinct a.id) * 100, 2), '%') as `次日留存率`
,concat(round(count(distinct c.id) / count(distinct a.id) * 100, 2), '%') as `三日留存率`
,concat(round(count(distinct d.id) / count(distinct a.id) * 100, 2), '%') as `七日留存率`
-- select *
from yhlc a
LEFT join yhlc b on a.id=b.id and b.dt=a.dt+1
LEFT join yhlc c on a.id=c.id and c.dt=a.dt+3
LEFT join yhlc d on a.id=d.id and d.dt=a.dt+7
group by a.dt;
6、终极大招
- 向老板要钱申请加资源
















 2143
2143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











