






Its Kernel
https://www.interdb.jp/pg/index.html
Chapter1 Database Cluster, Databases, and Tables(数据簇,数据库,表)
1.1 The Structure of Database Cluster(数据簇的结构)
1.1.1 Logical Structure(逻辑结构)
- A database is a collection of database objects
- Database objects include database itself, index, view, sequence, function etc.
- All the database objects in PostgreSQL are internally managed by respective object identifiers (OIDs), which are unsigned 4-bytes integers. (数据库对象包括,数据库本身,关系表,索引,视图,序列,函数等,每个数据库对象都由一个4字节的无符号整数型标识符标识,不同类型的对象标识符存储在system catalogs目录不同的文件中)
- They (database objects) are stored in appropriate system catalogs ,for example, OIDs are stored in pg_database, heap tables are stored in pg_class. These two files are also heap table object themselves. So we could find out the OIDs or heap tables by issuing the queries to their relative table. Such as:
my_first_pgdb=# select datname,oid from pg_database where datname='my_first_pgdb';
datname | oid
---------------+-------
my_first_pgdb | 16387
(1 row)
# relname: Name of the table, index, view, etc.
select relname, oid from pg_class where relname = 'my_first_pgtbl';
relname | oid
----------------+-------
my_first_pgtbl | 16384
(1 row)
1.1.2 Physical Structure(物理结构)
Layout of Database Cluster(数据簇的布局)
- After installing the PostgreSQL, you executed a initdb utility be like:
# 进入数据目录,用initdb命令初始化该目录,初始化成功后最后出现Success字样
[user@localhost ~]$ cd /pgdata/15.3/poc
[user@localhost poc]$ /opt/pgsql-15.3/bin/initdb -D /pgdata/15.3/poc/data/ -E UTF-8
……
……
Success. You can now start the database server using:
/opt/pgsql-15.3/bin/pg_ctl -D /pgdata/15.3/poc/data/ -l logfile start
- The use of this command is that create a new PostgreSQL database cluster.
- **Definition: **A database cluster is a collection of databases that are managed by a single server instance.
- Creating a database cluster consists of creating the directories in which the database data will live, generating the shared catalog tables (the tables which belong to the whole cluster rather than any particular database), and creating the databases which named
postgres,template0andtemplate1.- Database –
postgres, is a default database for use by all users, utilities and third party applications. It means that you don’t need to create any new databases, and you could use this database cluster to store and manage your data. - Databases–
template1,template0, are meant as source databases to be copied by laterCREATE DATABASEcommands.template0should never be modified, but you can add objects (like table, index, sequence, view and so on) totemplate1, which by default will be copied into databases created later.
- Database –
- Creating the database cluster is not compulsory,
- The path of the base directory is usually set to the environment variable
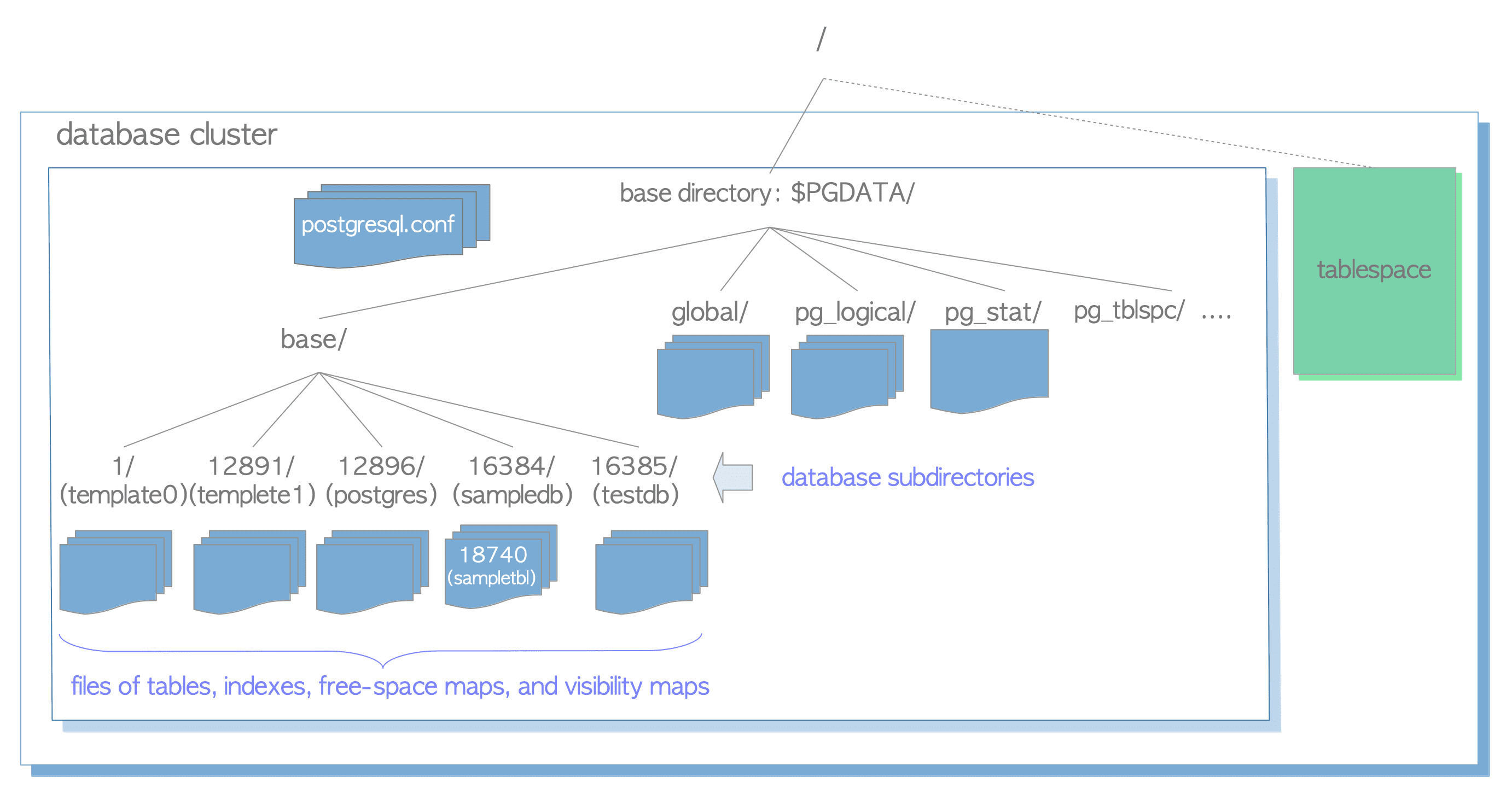
$PGDATA. - The figure of a database cluster directory:
[usera@localhost ~]$ ls /pgdata/15.3/poc/data/
base
pg_commit_ts
pg_hba.conf
pg_logical
pg_notify
pg_serial
pg_stat
pg_subtrans
pg_twophase
pg_wal
postgresql.auto.conf
postmaster.opts
global
pg_dynshmem
pg_ident.conf
pg_multixact
pg_replslot
pg_snapshots
pg_stat_tmp
pg_tblspc
PG_VERSION
pg_xact
postgresql.conf
postmaster.pid
[usera@localhost ~]$ ll /pgdata/15.3/poc/data/base
总用量 48
drwx------. 2 usera usera 8192 6月 12 09:39 1 # template1
drwx------. 2 usera usera 8192 6月 12 14:07 16387 # my_first_pgdb
drwx------. 2 usera usera 8192 6月 8 15:12 4 # template0
drwx------. 2 usera usera 8192 6月 12 09:39 5 # postgres
- A database is a subdirectory under the base subdirectory, and each of the tables and indexes is (at least) one file stored under the subdirectory of the database to which it belongs.
- PostgreSQL supports
tablespaces, the meaning of the term is different from other **RDBMS **(Relation Database Management System,关系数据库管理系统). Atablespacein PostgreSQL is one directory that contains some data outside of the base directory——/pgdate/xx.x/poc/data.
[usera@localhost ~]$ ll /pgdata/15.3/poc/data/
总用量 64
# base/ ,Subdirectory containing per-database subfirectiories
# 包含了每一个数据库对象子目录的目录
drwx------. 6 usera usera 46 6月 8 15:21 base
# global/ ,Subdirectory containing cluster-wide tables, such as pg_database and pg_control
# [usera@localhost ~]$ ls /pgdata/15.3/poc/data/global/
# 1213 1214 1260 1261 1262 2396 2397 2676 2695 2846 2965 3592 4061 4177 4182 4185 6001 6114 6244 6247 pg_internal.init
# 1213_fsm 1232 1260_fsm 1261_fsm 1262_fsm 2396_fsm 2671 2677 2697 2847 2966 3593 4175 4178 4183 4186 6002 6115 6245 pg_control
# 1213_vm 1233 1260_vm 1261_vm 1262_vm 2396_vm 2672 2694 2698 2964 2967 4060 4176 4181 4184 6000 6100 6243 6246 pg_filenode.map
# global目录下包含了cluster范围的表,这些表属于该cluster范围下所有的database对象
drwx------. 2 usera usera 4096 6月 12 14:07 global
# pg_commit_ts/ ,Subdirectory containing transaction commit timestamp data (new file emerged in PGv9.5)
# 该目录包含了事务提交时间的数据
drwx------. 2 usera usera 6 6月 8 15:12 pg_commit_ts
# pg_dynshmem/ ,Subdirectory containing files used by the dynamic shared memory subsystem.
# WHAT IS DYNAMIC SHARED MEMORY SUBSYSTEM???????????????????????????
# 动态共享内存子系统使用的文件
drwx------. 2 usera usera 6 6月 8 15:12 pg_dynshmem
# pg_hba.conf, A file to control PostgreSQL's client authentication
# 控制客户端认证
-rw-------. 1 usera usera 4789 6月 8 15:12 pg_hba.conf
# pg_ident.conf, A file to control PostgreSQL's user name mapping.
# 控制用户名映射
-rw-------. 1 usera usera 1636 6月 8 15:12 pg_ident.conf
# pg_logical/ , containing status data for logical decoding
# WHAT IS STATUS DATA for LOGICAL DECODING??????????????????????????
# 逻辑译码的状态数据
drwx------. 4 usera usera 68 6月 12 15:38 pg_logical
drwx------. 4 usera usera 36 6月 8 15:12 pg_multixact
drwx------. 2 usera usera 6 6月 8 15:12 pg_notify
drwx------. 2 usera usera 6 6月 8 15:12 pg_replslot
drwx------. 2 usera usera 6 6月 8 15:12 pg_serial
drwx------. 2 usera usera 6 6月 8 15:12 pg_snapshots
drwx------. 2 usera usera 6 6月 9 16:03 pg_stat
drwx------. 2 usera usera 6 6月 8 15:12 pg_stat_tmp
drwx------. 2 usera usera 18 6月 8 15:12 pg_subtrans
drwx------. 2 usera usera 6 6月 8 15:12 pg_tblspc
drwx------. 2 usera usera 6 6月 8 15:12 pg_twophase
# PG_VERSION, A file containing the major version number of PG
# PG版本文件
-rw-------. 1 usera usera 3 6月 8 15:12 PG_VERSION
drwx------. 3 usera usera 60 6月 8 15:12 pg_wal
drwx------. 2 usera usera 18 6月 8 15:12 pg_xact
# postgresql.auto.conf, A file used for storing configuration parameters that are set in ALTER SYSTEM (new file emerged in PGv9.4)
# WHAT IS ALTER SYSTEM??????????????????????????????????????????????
-rw-------. 1 usera usera 88 6月 8 15:12 postgresql.auto.conf
# postgresql.conf, A file to set configureation parameters
# 设置配置参数的文件
-rw-------. 1 usera usera 29442 6月 8 15:12 postgresql.conf
# postmaster.opts, A file recording the command line options the server was last started with
# 记录pg服务上次启动时使用的命令行选项
-rw-------. 1 usera usera 58 6月 12 09:39 postmaster.opts
-rw-------. 1 usera usera 87 6月 12 09:39 postmaster.pid
Layout of Databases
- The database directory names are identical to the respective OIDs, which meant its subdirectory name is the OIDs of the database. For example, the OIDs of
pg_databaseis1262, the subdirectory name of it inGlobal/is1262 - The file of database can not be opened, because it actually stored by using binary code.
Layout of Files Associated with Tables and Indexs
- Each table or index (as database object) stored under the database directory it belongs to (size less than 1 GB). They are internally managed by individual OIDs, and their data files are managed by different
relfilenode.(*OIDs对应数据库对象(表,索引…),relfilenode*对应数据库对象的数据文件) - The
relfilenodevalues of tables and indexes basically but not always match the respective OIDs, the details are described below.(relfilenode基本上(但不是所有的)都和文件对应的对象的OIDs一致,也就是大部分数据库对象的文件名就是该数据库对象的OIDs,但不是所有的都是)Match or not could refer to the fieldrelfilenodein tablepg_class, if zero, means this is a “mapped” relation, its data file name (also meant *relfilenode*values) is equal to its OIDs. - WHAT SITUATION WILL BE DIFFERENT?——For example, truncate the table, PG will assigns a new
relfilenodeto the table, and removes the old data file, and create a new one. - HOW to FIND THE FILE NAME of DATABASE OBJECT?——In version 9.0 or later, the built-in function
pg_relation_filepath(OID or Database object name)is useful as this function returns the file path name of the relation with the specified OIDs or name.
my_first_pgdb=# select pg_relation_filepath('pg_database');
pg_relation_filepath
----------------------
global/1262
(1 row)
- If the database size exceeds 1 GB, PG will creates a new file which named like
relfilenode.1, if this new file still has been filled up, next new file will named likerelfilenode.2, and so on. ( The 1 GB is not fixed standard, it can be changed by modifying configuration option. )
ls base/16384/19427*
19427 19427.1
- Each TABLE database object has two files suffixes respectively with ‘_fsm’ and ‘_vm’. Those are referred to as free space map(自由空间映射) and visibility map(可见的映射).(NOTICE: INDEX database object only have individual free space maps)
- free space map: storing the information of the free space capacity
- visibility map: storing the visibility on each page within the table file(表文件中每个页面上的可见性)
- They may also be internally referred to as the forks of each relation
Tablespaces (tblspc)
-
The green area in the right of the figure of a database cluster directory show the
tablespacedata area. -
Definition: A
tablespacein PostgreSQL is an additional data area outside the base directory. PG usetablespacesmapping disk physical location to the logical name. (symbolic link, 符号链接)(表空间tablespace实际就是给表制定一个存储目录,用来存放数据库对象的文件的位置。) -
You can create
tablespacesunder the specified directory by issuingcreate tablespacestatement. And under the directory, the version-specific subdirectory will be created. ( For example, if you create a tablespace'new_tblspc'at'/opt/pgsql-15.3/tblspc', whose OID is 16386, a subdirectory such as'PG_15_202011044'would be created under the tablespace. ) The SQL command is as followed:
CREATER TABLESPACE tblspc_name OWNER user_name LOCATION directory_path;
# 特定于版本的子目录
PG_'Major version'_'Catalogue version number'
# 目录情况
ls /opt/pgsql-15.3/tblspc/PG_15_XXXXXXXXX/
db1_OID db2_OID …… dbn_OID

- You can manage the disk layout through PG
tablespaces. - The tablespace directory is addressed by a symbolic link from the
pg_tblspcsubdirectory, and the link name is the same as the OID value of tablespace. - WHY SHOULD SET THE SPECIFIC TABLESPACE?——不指定其他表空间的话会把各种数据放到默认的空间里,如果所有的表都不指定没准什么时候默认表空间满了,表就插入不了数据了。目的就是防止物理空间不足,用额外的地方来存储。
1.2 The Internal Layout of Heap Table File
-
数据文件内部 is divided into pages of fixed length (8 KB)
-
Those pages within each file are numbered sequentially from 0(从0开始按顺序编号), and such numbers are called as block numbers. (每一个page 的编号称之为块号,理解为页号就行)
-
If the file has been filled up, PostgreSQL adds a new empty page to the end of the file to increase the file size.
-
Internal layout of pages depend on the data file types.
-
One page within a table contains three kinds of data described as follow:(每一个page中又分为三种数据类型,定义为一个结构体
PageHeaderDate,定义在文件src/include/storage/bufpage.h 中)- heap tuples (s)(堆元组)— is a record data itself, They are stacked in order from the bottom of the page. (对应数据库关系表的元组数据,也就是行,每insert一组数据就增加一个heap tuple,它本身就是一种记录数据,它从 page 的底部开始按顺序堆叠)Internal layout of tuples will be detailed introduces in Section 5.2 and Chapter 9.
- To identify a tuple within the table, internally using tuple identifier (TID), a TID comprises a pair of (two) values: ①the block number of the page that contains the tuple, and ②the offset number of the line pointer that points to the tuple.(元组标识符(TID)由两个值组成:①元组所属页面的块()页号,②指向该元组的指针在页面内的偏移量), For example, showing pseudo code below:
TID = (block=7,offset-2) - In addition, heap tuple whose size is greater than about 2 KB (about 1/4 of 8 KB) is stored and managed using a method called TOAST. (用TOAST() 方法存储和管理约占 1/4 Page 大小(2 KB)的堆元组)
- To identify a tuple within the table, internally using tuple identifier (TID), a TID comprises a pair of (two) values: ①the block number of the page that contains the tuple, and ②the offset number of the line pointer that points to the tuple.(元组标识符(TID)由两个值组成:①元组所属页面的块()页号,②指向该元组的指针在页面内的偏移量), For example, showing pseudo code below:
- line pointer (s)(行指针)— A line pointer is 4 byte long (not 8 byte), containing each pointer which points to each heap tuple.(行指针们形成一个指针数组,并且每一个指针都指向一个tuple) It plays the role of index to the tuples, and all of line pointers from a simple array. (充当了tuple索引的作用)Each index is numbered sequentially from 1, and called offset number. (每个索引从1开始按顺序编号,称为偏移量)When a new tuple is added to the page, a new line pointer is also pushed onto the array to point to the new one. (每添加一个元组到page,数组里就会相应地添加一个行指针指向新元组)
- free space or hole(可用空间)— An empty space between the end of the line pointers and the beginning of the newest tuple.(可用空间是page中位于行指针数组,和最新加入page的元组之间的空间,图片中很直观的表示了这一片空间)
- header data(标题数据)— its data structure is shown as followed: (pd–Page Header Data); (LSN–Log Sequence Number)
pd_lsn—This variable stores the Log Sequence Number of XLOG record written by the last change of this page. (这个变量存储着这个page最后一次修改的日志序列号) The details are described in Chapter 9 - WAL.pd_checksum— This variable stores the checksum value of this page.(这个变量存储着这个page的校验和)pd_lower, pd_upper— These two variables respectively point to the end of the line pointers and the beginning of the newest heap tuples.(分别指向行指针数组的结尾位置&最新加入page的元组的开头位置,同时也对应了free space 的开头&结尾位置)(因为元组是从page的底部开始存放)pd_special— This variable is for indexes. In the page within tables, it points to the end of the page.(用于索引,在表的page中指向page的结尾位置)
typedef struct PageHeaderData @src/include/storage/bufpage.h { /* XXX LSN is member of *any* block, not only page-organized ones */ XLogRecPtr pd_lsn; /* LSN (Log Sequence Number,日志序列号): next byte after last byte of xlog.(xlog最后一个字节的下一个字节)是uint8类型。 * record for last change to this page(记录对该页面的上次更改) */ uint16 pd_checksum; /* checksum(校验和) */ uint16 pd_flags; /* flag bits, see below(标志位) */ LocationIndex pd_lower; /* offset to start of free space(可用空间起始位置的偏移量) */ LocationIndex pd_upper; /* offset to end of free space(可用空间结尾位置的偏移量) */ LocationIndex pd_special; /* offset to start of special space(特殊空间起始位置的偏移量) */ uint16 pd_pagesize_version; /* page的内存大小or版本号 */ TransactionId pd_prune_xid;/* oldest prunable XID, or zero if none */ ItemIdData pd_linp[1]; /* beginning of line pointer array(行指针数组的起始位置) */ } PageHeaderData; typedef PageHeaderData *PageHeader; typedef uint64 XLogRecPtr; /* uint16,undesigned int 16,16位无符号整数 */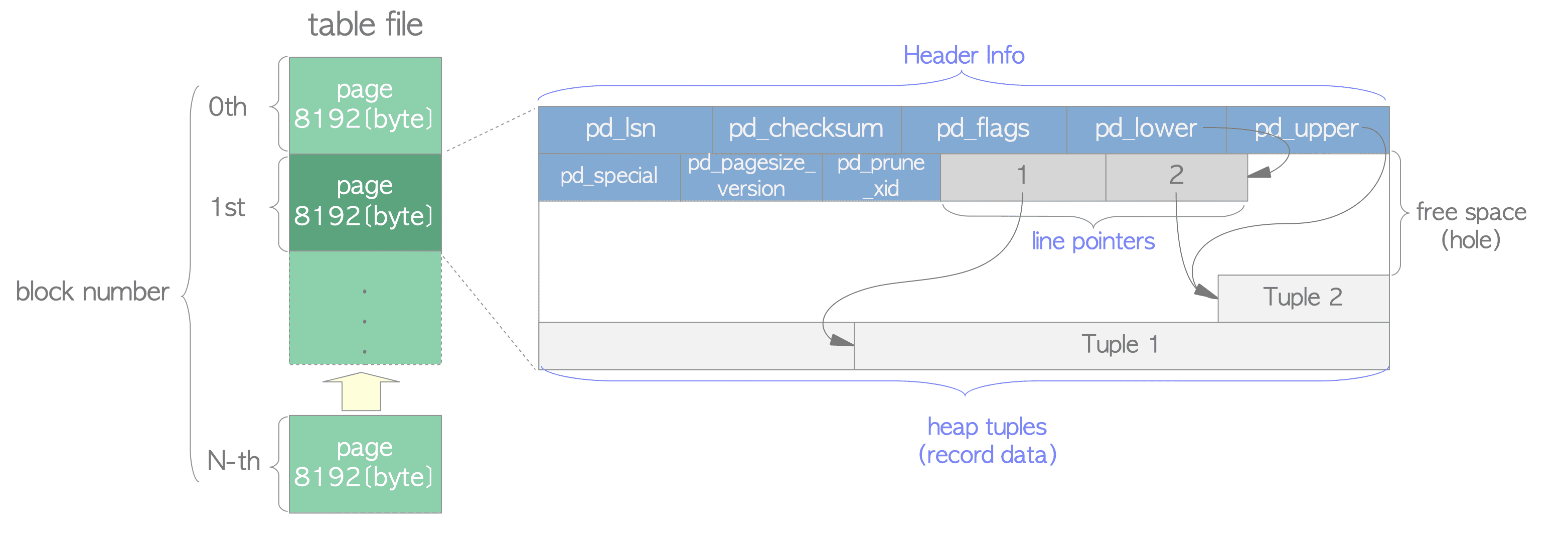
- heap tuples (s)(堆元组)— is a record data itself, They are stacked in order from the bottom of the page. (对应数据库关系表的元组数据,也就是行,每insert一组数据就增加一个heap tuple,它本身就是一种记录数据,它从 page 的底部开始按顺序堆叠)Internal layout of tuples will be detailed introduces in Section 5.2 and Chapter 9.
1.3 The Methods of Writing & Reading Data to A Table (The Methods of W&R Tuples)
1.3.1 Writing Heap Tuples (INSERT)
- (Premise: Suppose a table composed of one page which contains just one heap tuple. 假设一张关系表仅包含一页,这一页也仅包含一个堆元组 )
- When
INSERTnew data, page internal will change —- ①The second tuple will be created, and be placed after the first one.
- ②The second line pointer will be created, and point at the new tuple.
- ③The
pd_lowerwill change to point to the new line pointer, and thepd_upperwill be change to point to the beginning of the new tuple. - ④OF COURSE, Other header data within this page (e.g. ,
pd_lsn,pg_checksum,pg_flag) are also rewritten to appropriate values.

1.3.2 Reading Heap Tuples (SELECT)
-
There are two typical access method to find the corresponding target data: ①sequential scan ②B-tree index scan.
- ①Sequentially read: by scanning all line pointers in each page.(顺序扫描:扫描所有 page 中的每一个行指针 line pointer)

- ②B-tree
- ③TID-Scan: TID-Scan is a method that accesses a tuple directly by using TID of the desired tuple. For example, to find the 1st tuple in the 0-th page within the table, issue the following query: (直接通过TID的两个值进行查询)
my_first_pgdb=# select ctid,city from weather where ctid='(0,1)'; ctid | city -------+--------------- (0,1) | San Francisco (1 row)- ④Bitmap-Scan
- ⑤Index-Only-Scan
1.4 About the Internals of Index in PostgreSQL
( How to use indexes to speed up queries? — Firstly, clarify the role of indexes, they are special db objects mainly designed to speed up data access.
https://postgrespro.com/blog/pgsql/3994098
The Sort of Indexes
- Six different kinds of indexes are built into PostgreSQL-9.6. Despite all differences between types of indexes, each of them eventually associates a key with table rows that contain this key.















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









