






对于一个统计量的分析
在我们遇到数据是,首先要从电脑上去导入数据,在这里要用到pandas来导入该库,一般的dos命令行去下载就行了,不需要去pandas的官网上去下载,
pip install pandas -i 国内的源
因为这些库全部都是国外的,我们在下载的时候一般都是比较的慢的,所以一般在下载的时候去导入国内的源,在搜索的时候搜索python换源就可以去导入了。
接下来就开始导入数据了,
data=pd.read_csv("数据路径")在这里导入一般导入的是csv文件,在导入之后
一定会要用到一个函数,去描述该数据,即describe,这个函数就可以去清楚的看见该数据的所有的信息
data.describe()这个函数就可以简单的去分析到的这整个数据的所有信息,我的在这里导入了我的一个数据,在数据描述之后
'''
Rank Year ... Revenue (Millions) Metascore
count 1000.000000 1000.000000 ... 872.000000 936.000000
mean 500.500000 2012.783000 ... 82.956376 58.985043
std 288.819436 3.205962 ... 103.253540 17.194757
min 1.000000 2006.000000 ... 0.000000 11.000000
25% 250.750000 2010.000000 ... 13.270000 47.000000
50% 500.500000 2014.000000 ... 47.985000 59.500000
75% 750.250000 2016.000000 ... 113.715000 72.000000
max 1000.000000 2016.000000 ... 936.630000 100.000000
[8 rows x 7 columns]
'''
从这个描述我们就可以简单的看到这个数据的所有数据,count描述的就是每列的数据的个数,mean表述的是平均数,std是指标准差,min是指的是最小值,25%:四分之一位数,50%二分之一分位数,75%,四分之三分位数,max表示的是最大值
对电影数据的时长分布的一个简单的分析
在上面的描述的信息中我们可以清楚的看见,对于每列的数据的个数来看,也就是我们上面的count来看,还是不太清晰,因为在最后的时候我们要将这个关于时长的数据进行可视化,但是数据可能会有缺失,所以我们要用一个函数来看是否数据会有一个缺失值,在这里我们要用到的是info这个函数,
data.info()
'''
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Rank 1000 non-null int64
1 Title 1000 non-null object
2 Genre 1000 non-null object
3 Description 1000 non-null object
4 Director 1000 non-null object
5 Actors 1000 non-null object
6 Year 1000 non-null int64
7 Runtime (Minutes) 1000 non-null int64
8 Rating 1000 non-null float64
9 Votes 1000 non-null int64
10 Revenue (Millions) 872 non-null float64
11 Metascore 936 non-null float64
dtypes: float64(3), int64(4), object(5)
memory usage: 93.9+ KB
None
'''
在这里我们就可以特别清楚的看到,由于我们要用的是一个电影时长的一个分析而且刚好在电影时长这里non_null,无空值,则对他的分析就特别的简单了,但是,我们在看到索引位10和11的时候是872和936,所以肯定是有缺失值的,在后面我会对这两个列进行一个数据的填充,在这里先对电影时长这里进行一个分析,由于是对电影时长的分布进行一个分析,所以
要将电影时长这一列提取出来,在这里用到的就是loc,直接用列名来进行一个提取,data_=data.loc[:,"Runtime (Minutes)"],但是在绘制图形的时候,要变成列表来作为横坐标,所以将数据的values值给提取出来,则是
data_values=data_.values这样的话我们就可以把values给提取出来而且变成列表类型,我们在这里可以用type来看一下type(data_values)<class ‘numpy.ndarray’>在这里我们可以看出他已经转变成为了一个一维数组`
现在在绘制图形之前的准备的工作全部结束了,在这个时候由于是分析电影时长的分布,则我们要用到的是频率直方图
import numpy as np
import matplotlib.pyplot as plt
AApl_data=AApl.loc[:,"Runtime (Minutes)"]
AApl_data_values=AApl_data.values
# print(type(AApl_data_values))
ptp_data=np.ptp(AApl_data_values)#求极差 125 在这里组距设置为5
d=5#组距设置为5
#求组数
AApl_data_values_num=ptp_data//d
min_data=min(AApl_data_values)
max_data=max(AApl_data_values)
plt.figure(figsize=(14,8))
plt.hist(AApl_data_values,bins=AApl_data_values_num)
plt.xticks(range(min_data,max_data+5,5))
plt.show()
做出来的效果就是这样的
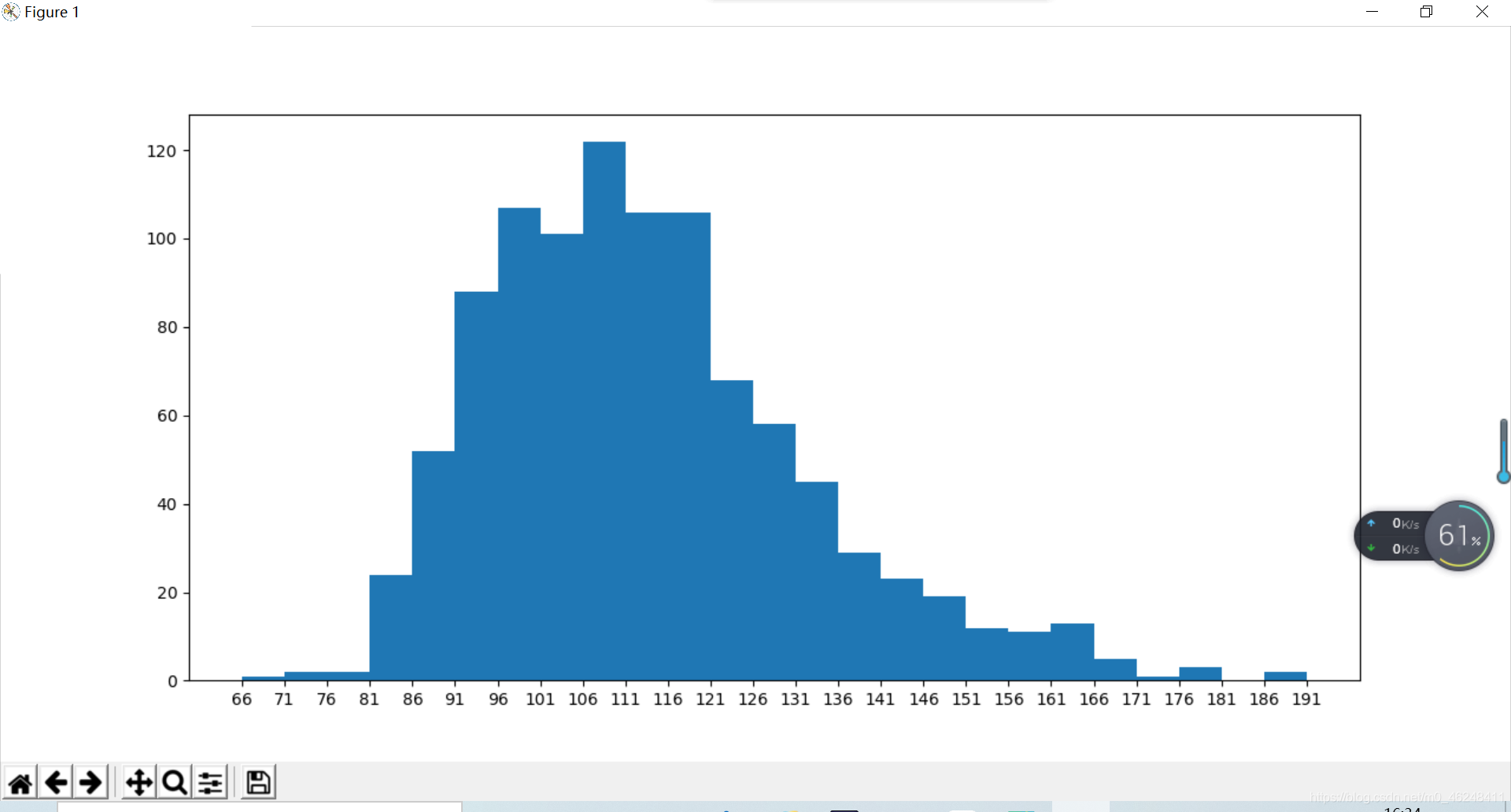
这样,一个简单的可视化图案就完成了,本人目前还是小白一个,如果有什么地方不太正确的话,谢谢大佬们的指正!!

















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









