







分库分表(水平分表)
数据分片官方文档
rules:
- !SHARDING
tables: # 数据分片规则配置
<logic-table-name> (+): # 逻辑表名称
actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 分片算法名称
complex: # 用于多分片键的复合分片场景
shardingColumns: # 分片列名称,多个列以逗号分隔
shardingAlgorithmName: # 分片算法名称
hint: # Hint 分片策略
shardingAlgorithmName: # 分片算法名称
none: # 不分片
tableStrategy: # 分表策略,同分库策略
keyGenerateStrategy: # 分布式序列策略
column: # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: # 分布式序列算法名称
autoTables: # 自动分片表规则配置
t_order_auto: # 逻辑表名称
actualDataSources (?): # 数据源名称
shardingStrategy: # 切分策略
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
shardingAlgorithmName: # 自动分片算法名称
bindingTables (+): # 绑定表规则列表
- <logic_table_name_1, logic_table_name_2, ...>
- <logic_table_name_1, logic_table_name_2, ...>
broadcastTables (+): # 广播表规则列表
- <table-name>
- <table-name>
defaultDatabaseStrategy: # 默认数据库分片策略
defaultTableStrategy: # 默认表分片策略
defaultKeyGenerateStrategy: # 默认的分布式序列策略
defaultShardingColumn: # 默认分片列名称
# 分片算法配置
shardingAlgorithms:
<sharding-algorithm-name> (+): # 分片算法名称
type: # 分片算法类型
props: # 分片算法属性配置
# ...
# 分布式序列算法配置
keyGenerators:
<key-generate-algorithm-name> (+): # 分布式序列算法名称
type: # 分布式序列算法类型
props: # 分布式序列算法属性配置
# ...
由于order数据庞大 ,所以对order进行水平分片
服务器规划使用docker方式创建如下容器

● 服务器:容器名server-order0,端口3510
● 服务器:容器名server-order1,端口3511
创建数据库服务器
创建docker-compose文件
version: '3'
services:
lx-server-user:
image: mysql:8.0.29
environment:
MYSQL_ROOT_PASSWORD: 123456
MYSQL_PASSWORD: 123456
ports:
- 3510:3306
container_name: "lx-server-user"
lx-server-order0:
image: mysql:8.0.29
environment:
MYSQL_ROOT_PASSWORD: 123456
MYSQL_PASSWORD: 123456
ports:
- 3510:3306
container_name: "lx-server-order0"
lx-server-order1:
image: mysql:8.0.29
environment:
MYSQL_ROOT_PASSWORD: 123456
MYSQL_PASSWORD: 123456
ports:
- 3511:3306
container_name: "lx-server-order1"
启动数据库
docker-compose -f docker-compose-order.yml up -d
3501准备数据
创建数据库
CREATE DATABASE db_user;
创建表
CREATE TABLE t_user (
id BIGINT AUTO_INCREMENT,
uname VARCHAR(30),
PRIMARY KEY (id)
);
3510和3511分别创建库表
创建库
CREATE DATABASE db_order;
创建表
CREATE TABLE t_order0 (
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
CREATE TABLE t_order1 (
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
基本水平分片
# ------------------- 基本配置
# 应用名称
spring:
application:
name: sharding-jdbc-demo
profiles:
active: dev
shardingsphere:
mode:
type: Memory
props:
sql-show: true
#-------------- 数据源配置
# 配置真实数据源
datasource:
names: server-user,server-order0,server-order1
# 配置第 1 个数据源
server-user:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3501/db_user?allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 123456
# 配置第 2 个数据源
server-order0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3510/db_order?allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 123456
# 配置第 3 个数据源
server-order1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3511/db_order?allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 123456
#========================标准分片表配置(数据节点配置)
rules:
sharding:
tables:
t_user:
actualDataNodes: server-user.t_user
t_order:
actualDataNodes: server-order0.t_order0,server-order0.t_order1,server-order1.t_order0,server-order1.t_order1
测试插入数据
注意:水平分片的id需要在业务层实现,不能依赖数据库的主键自增
创建实体类
User
@TableName("t_user")
@Data
public class TUser {
@TableId(type = IdType.AUTO)
private Long id;
private String uname;
}
Order
@Data
public class Order {
//注意: 水平分片的id需要在业务层实现,不能依赖数据库的主键自增
//@TableId(type = IdType.AUTO)//依赖数据库的主键自增策略
@TableId(type = IdType.ASSIGN_ID)//分布式id
//AUTO的配置大于ASSIGN_ID的配置
private Long id;
private String orderNo;
private Long userId;
private BigDecimal amount;
}
创建Mapper
TUserMapper
@Mapper
public interface TUserMapper extends BaseMapper<TUser> {
}
OrderMapper
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
}
为了方便测试,保留上面配置中的一个分片表节点分别进行测试,检查每个分片节点是否可用
修改
t_order:
actualDataNodes:
的值分别为
server-order0.t_order0
server-order0.t_order1
server-order1.t_order0
server-order1.t_order1
分别添加数据 检查数据源是否有问题
测试插入数据
/**
* 垂直分片:插入数据测试
*/
@Test
public void testInsertOrderAndUser(){
TUser user = new TUser();
user.setUname("数据分片");
userMapper.insert(user);
Order order = new Order();
order.setOrderNo("0001");
order.setUserId(user.getId());
order.setAmount(new BigDecimal(100));
orderMapper.insert(order);
}
server-order0.t_order0

server-order0.t_order1
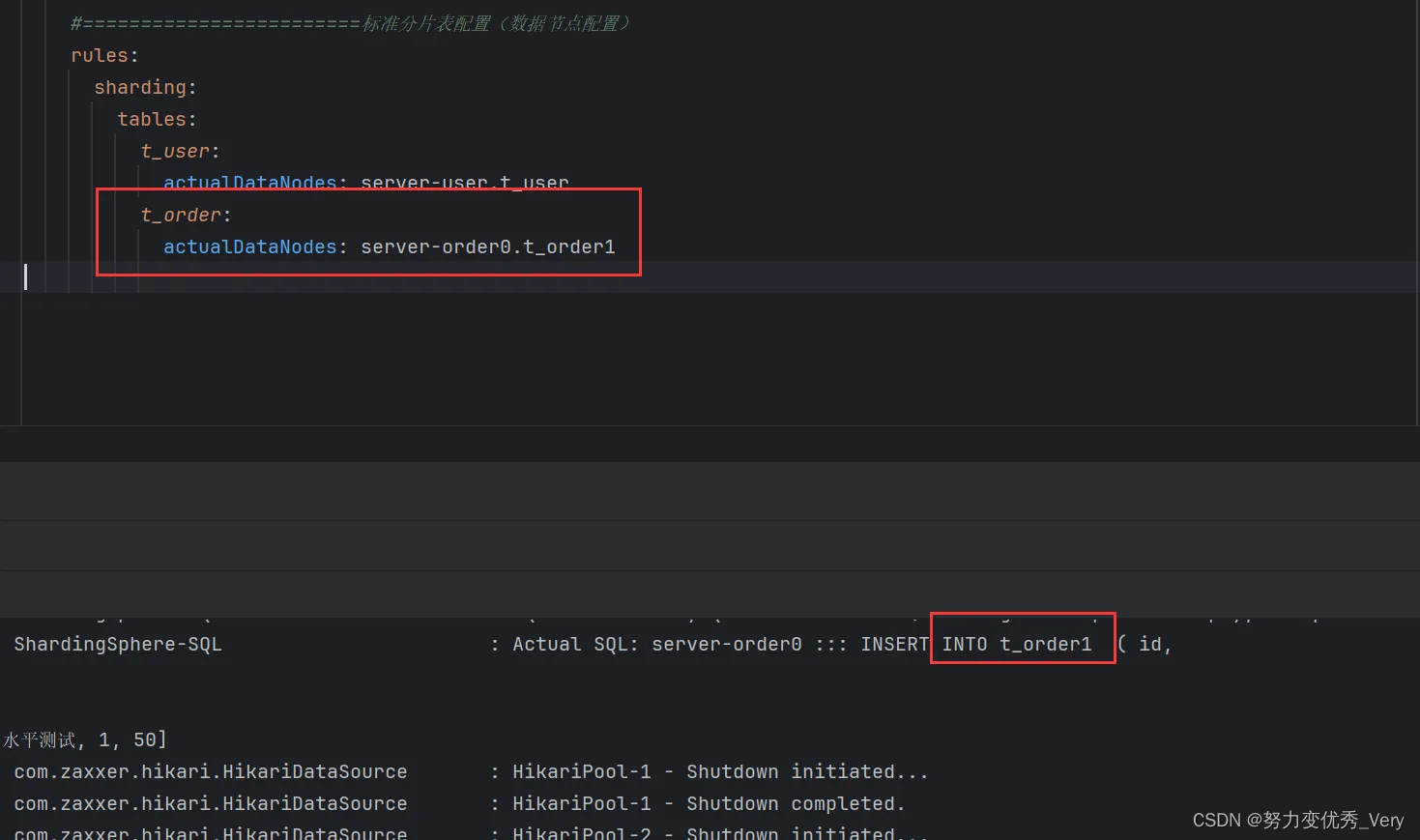
server-order1.t_order0
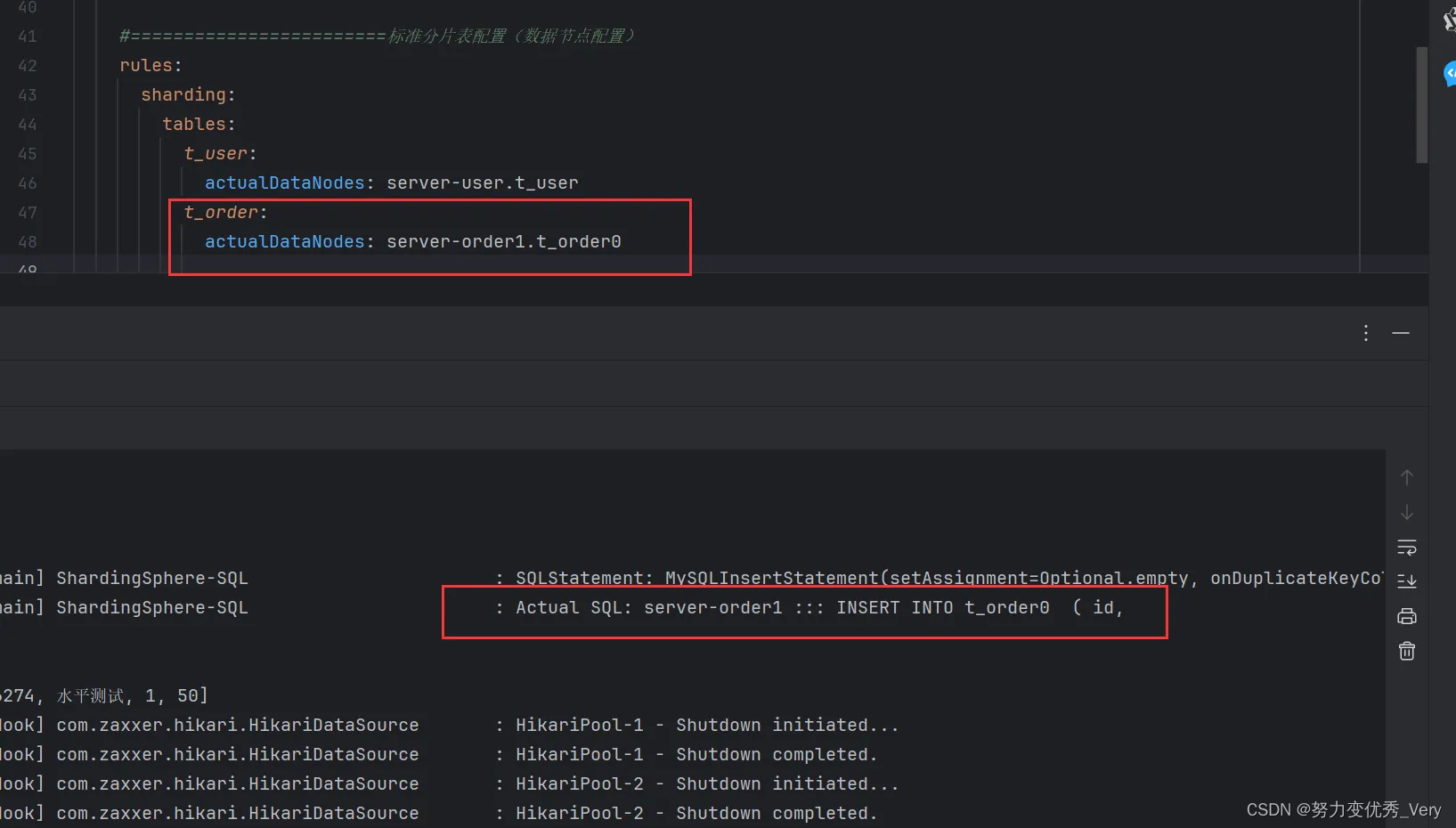
server-order1.t_order1

数据节点很多配置很麻烦,难道就没有简单的方法吗?
行表达式
语法
${begin..end} 表示范围区间
${[unit1, unit2, unit_x]} 表示枚举值
-----------------------------------------
${['online', 'offline']}_table${1..3}
最终会解析为 简单理解就是两个的卡迪尔积
online_table1, online_table2, online_table3,
offline_table1, offline_table2, offline_table3
比如我们有一下数据节点
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
使用行表达式为
db${0..1}.t_order${0..1}
或者
db$->{0..1}.t_order$->{0..1}
当数据节点如以下时 对于这种不能使用通用的配置 就需要单据配置
多个数据源中的表结构不是一样的
db0
├── t_order0
└── t_order1
db1
├── t_order2
├── t_order3
└── t_order4
使用行表达式为
db0.t_order${0..1},db1.t_order${2..4}
或者
db0.t_order$->{0..1},db1.t_order$->{2..4}
对于有前缀的数据节点,也可以通过行表达式灵活配置,如果数据结构如下:
db0
├── t_order_00
├── t_order_01
├── t_order_02
├── t_order_03
├── t_order_04
├── t_order_05
├── t_order_06
├── t_order_07
├── t_order_08
├── t_order_09
├── t_order_10
├── t_order_11
├── t_order_12
├── t_order_13
├── t_order_14
├── t_order_15
├── t_order_16
├── t_order_17
├── t_order_18
├── t_order_19
└── t_order_20
db1
├── t_order_00
├── t_order_01
├── t_order_02
├── t_order_03
├── t_order_04
├── t_order_05
├── t_order_06
├── t_order_07
├── t_order_08
├── t_order_09
├── t_order_10
├── t_order_11
├── t_order_12
├── t_order_13
├── t_order_14
├── t_order_15
├── t_order_16
├── t_order_17
├── t_order_18
├── t_order_19
└── t_order_20
可以使用分开配置的方式,先配置包含前缀的数据节点,再配置不含前缀的数据节点,再利用行表达式笛卡尔积的特性,自动组合即可。 上面的示例,用行表达式可以简化为:
db${0..1}.t_order_0${0..9}, db${0..1}.t_order_${10..20}
或者
db$->{0..1}.t_order_0$->{0..9}, db$->{0..1}.t_order_$->{10..20}
使用行表达式配置数据节点
server-order0.t_order0,server-order0.t_order1,server-order1.t_order0,server-order1.t_order1使用行表达式就是
server-order$->{0..1}.t_order$->{0..1}
分片算法类型
分片算法类型官网
分库配置
需求
shardingColumn 分片键 我们希望当user_id的值是偶数时 ,则路由到server-order0中,当user_id的值是奇数时,则路由到server-order1中
因为还没有配置分表的策略 为了方便测试,先设置只在actualDataNodes : t_order0表上进行测试
rules:
sharding:
tables:
t_user:
actualDataNodes: server-user.t_user
t_order:
# 实际数据源
actualDataNodes: server-order$->{0..1}.t_order0 修改这里
# 分库策略
databaseStrategy:
standard:
# 分片列名称 当user_id的值是偶数时 ,则路由到server-order0中,当user_id的值是奇数时,则路由到server-order1中
shardingColumn: user_id
# 分片算法名称
shardingAlgorithmName: my_inlineuserid
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
my_inlineuserid:
# 分片算法类型 行表达式分片算法
type: INLINE
# 相关配置参数
props:
# 分片算法的行表达式 根据user_id取模取余数 可以得出实际的数据库 server-order0,server-order1
algorithm-expression: server-order$->{user_id % 2}
总结配置
通过user_id进行分库。分库的类型是INLINE行表达式分片算法。通过配置algorithm-expression参数,进行配置行表达式。server-order$->{user_id % 2}。根据行表达式 进行路由具体的数据库。
进行分库测试
/**
* 水平分片:分库插入数据测试
*/
@Test
public void testInsertOrderDatabaseStrategy(){
for (long i = 0; i < 4; i++) {
Order order = new Order();
order.setOrderNo("order");
order.setUserId(i + 1);
order.setAmount(new BigDecimal(50));
orderMapper.insert(order);
}
}
出现异常
org.apache.shardingsphere.spi.exception.ServiceProviderNotFoundException:
No implementation class load from SPI `org.apache.shardingsphere.sharding.spi.ShardingAlgorithm`
with type `null`.
at org.apache.shardingsphere.spi.typed.
TypedSPIRegistry.getRegisteredService(TypedSPIRegistry.java:76) ~[shardingsphere-spi-5.1.1.jar:5.1.1]
这个错误通常表明系统无法从服务提供接口(SPI)中加载类型为 null 的分片算法。这可能是由于配置错误或依赖项问题引起的。
意思是找不到分片的算法。但是我们已经导入了相关的依赖
经过查询资料得知 shardingjdbc 配置尽量不要使用 中划线写法,也不能使用驼峰命名的方式。会导致读取配置文件数据失败,造成空指针异常
解决方法
把分片算法名称 my_inlineuserid 改为 myinlineuserid
测试发现按照分片算法分到了具体的数据库

测试mod取模算法
添加取模分片算法配置mymod
# 分片算法配置
shardingAlgorithms:
# 分片算法名称
myinlineuserid:
# 分片算法类型 行表达式分片算法
type: INLINE
# 相关配置参数
props:
# 分片算法的行表达式 根据user_id取模取余数 可以得出实际的数据库 server-order0,server-order1
algorithm-expression: server-order$->{user_id % 2}
# 分片算法名称
mymod:
# 分片算法类型
type: MOD
# 相关配置参数
props:
sharding-count: 2
更改算法
# 分片算法名称
shardingAlgorithmName: mymod
测试
/**
* 水平分片:分库插入数据测试
*/
@Test
public void testInsertOrderDatabaseStrategy(){
for (long i = 10; i < 14; i++) {
Order order = new Order();
order.setOrderNo("order2");
order.setUserId(i + 1);
order.setAmount(new BigDecimal(50));
orderMapper.insert(order);
}
}
测试结果

测试哈希取模算法
特点mod算法只适用于数值类型的字段。哈希取模是先对分片字段进行哈希计算,再通过哈希值进行分片
配置算法
hashmod:
type: HASH_MOD
props:
sharding-count: 2
更改算法
# 分片算法名称
shardingAlgorithmName: hashmod
测试
/**
* 水平分片:分库插入数据测试
*/
@Test
public void testInsertOrderDatabaseStrategy(){
for (long i = 20; i < 24; i++) {
Order order = new Order();
order.setOrderNo("order3");
order.setUserId(i + 1);
order.setAmount(new BigDecimal(50));
orderMapper.insert(order);
}
}

分表
分表策略和分库策略配置都是相同的只是把 databaseStrategy (?): # 分库策略,名称换成了 tableStrategy: # 分表策略,同分库策略,其他配置相同
分库和分表可以使用相同的分片策略。
使用分表策略就可以把实际数据源换成
rules:
sharding:
tables:
t_user:
actualDataNodes: server-user.t_user
t_order:
# 实际数据源
actualDataNodes: server-order$->{0..1}.t_order$->{0..1}
分表新增测试
/**
* 水平分片:分库插入数据测试
*/
@Test
public void testInsertOrderDatabaseStrategy(){
Order order = new Order();
order.setOrderNo("order-1"+ i);
System.out.println("=================");
System.out.println(i% 2 );
order.setUserId(1l );
order.setAmount(new BigDecimal(50));
orderMapper.insert(order);
Order order1 = new Order();
order1.setOrderNo("order-2"+ i);
order1.setUserId(2l );
order1.setAmount(new BigDecimal(50));
orderMapper.insert(order1);
}
分表查询测试
/**
* 水平分片:查询所有记录
* 查询了两个数据源,每个数据源中使用UNION ALL连接两个表
*/
@Test
public void testShardingSelectAll(){
List<Order> orders = orderMapper.selectList(null);
orders.forEach(System.out::println);
}

通过SQL语句看出 是分别向两个数据源查询了数据
分表分片键查询测试
/**
* 水平分片:根据user_id查询记录
* 查询了一个数据源,每个数据源中使用UNION ALL连接两个表
*/
@Test
public void testShardingSelectByUserId(){
QueryWrapper<Order> orderQueryWrapper = new QueryWrapper<>();
orderQueryWrapper.eq("user_id", 1L);
List<Order> orders = orderMapper.selectList(orderQueryWrapper);
orders.forEach(System.out::println);
}
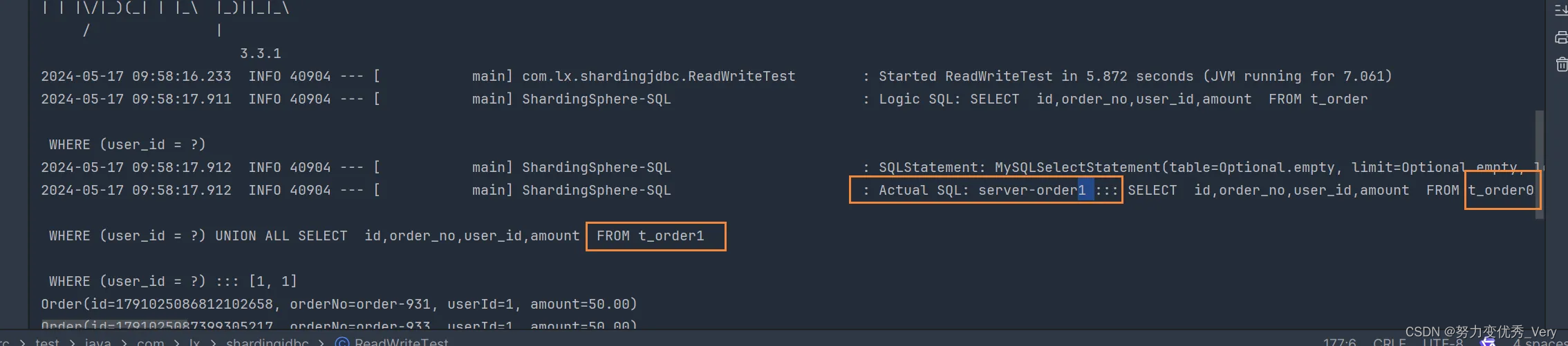
通过分片建查询 查询了一个数据源,每个数据源中使用UNION ALL连接两个表
通过分片键进行的分库,当然能通过分片键知道具体的实际数据源
分布式序列算法
水平分片需要关注全局序列,因为不能简单的使用基于数据库的主键自增。
这里有两种方案:一种是基于MyBatisPlus的id策略;一种是ShardingSphere-JDBC的全局序列配置。
基于MyBatisPlus的id策略:将Order类的id设置成如下形式
@TableId(type = IdType.ASSIGN_ID)
private Long id;
配置分布式序列算法
配置t_order逻辑数据源
rules:
sharding:
tables:
t_user:
actualDataNodes: server-user.t_user
t_order:
# 实际数据源
actualDataNodes: server-order$->{0..1}.t_order$->{0..1}
# 分库策略
databaseStrategy:
standard:
# 分片列名称 当user_id的值是偶数时 ,则路由到server-order0中,当user_id的值是奇数时,则路由到server-order1中
shardingColumn: user_id
# 分片算法名称
shardingAlgorithmName: myinlineuserid
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: hashmod
keyGenerateStrategy: # 分布式序列策略
column: id # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: mysnowflake # 分布式序列算法名称
此时,需要将实体类中的id策略修改成以下形式:
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
//当没有配置shardingsphere-jdbc的分布式序列时,自动依赖数据库的主键自增策略
@TableId(type = IdType.AUTO)
测试新增order 没问题
多表关联插入
创建关联表
在server-order0、server-order1服务器中分别创建两张订单详情表t_order_item0、t_order_item1
我们希望
同一个用户的订单表和订单详情表中的数据都在同一个数据源中,避免跨库关联,因此这两张表我们使用相同的分片策略。
那么在t_order_item中我们也需要创建order_no和user_id这两个分片键
CREATE TABLE t_order_item0(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
PRIMARY KEY(id)
);
CREATE TABLE t_order_item1(
id BIGINT,
order_no VARCHAR(30),
user_id BIGINT,
price DECIMAL(10,2),
`count` INT,
PRIMARY KEY(id)
);
创建实体类
package com.atguigu.shardingjdbcdemo.entity;
@TableName("t_order_item")
@Data
public class OrderItem {
//当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
@TableId(type = IdType.AUTO)
private Long id;
private String orderNo;
private Long userId;
private BigDecimal price;
private Integer count;
}
创建Mapper
@Mapper
public interface OrderItemMapper extends BaseMapper<OrderItem> {
}
t_order_item的分片表、分片策略、分布式序列策略和t_order一致,
t_order_item:
# 实际数据源
actualDataNodes: server-order$->{0..1}.t_order_item$->{0..1}
# 分库策略
databaseStrategy:
standard:
# 分片列名称 当user_id的值是偶数时 ,则路由到server-order0中,当user_id的值是奇数时,则路由到server-order1中
shardingColumn: user_id
# 分片算法名称
shardingAlgorithmName: myinlineuserid
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: hashmod
keyGenerateStrategy: # 分布式序列策略
column: id # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: mysnowflake # 分布式序列算法名称
测试插入数据
同一个用户的订单表和订单详情表中的数据都在同一个数据源中,避免跨库关联
/**
* 测试关联表插入
*/
@Test
public void testInsertOrderAndOrderItem(){
for (long i = 1; i < 3; i++) {
Order order = new Order();
order.setOrderNo("关联" + i);
order.setUserId(1L);
orderMapper.insert(order);
for (long j = 1; j < 3; j++) {
OrderItem orderItem = new OrderItem();
orderItem.setOrderNo("新增" + i);
orderItem.setUserId(1L);
orderItem.setPrice(new BigDecimal(10));
orderItem.setCount(2);
orderItemMapper.insert(orderItem);
}
}
for (long i = 5; i < 7; i++) {
Order order = new Order();
order.setOrderNo("关联" + i);
order.setUserId(2L);
orderMapper.insert(order);
for (long j = 1; j < 3; j++) {
OrderItem orderItem = new OrderItem();
orderItem.setOrderNo("新增" + i);
orderItem.setUserId(2L);
orderItem.setPrice(new BigDecimal(1));
orderItem.setCount(3);
orderItemMapper.insert(orderItem);
}
}
}
新增数据没问题
绑定表
需求 查询每个订单的订单号和总订单金额
创建VO对象
@Data
public class OrderVo {
private String orderNo;
private BigDecimal amount;
}
添加Mapper方法
@Mapper
public interface OrderMapper extends BaseMapper<Order> {
@Select({"SELECT o.order_no, SUM(i.price * i.count) AS amount",
"FROM t_order o JOIN t_order_item i ON o.order_no = i.order_no",
"GROUP BY o.order_no"})
List<OrderVo> getOrderAmount();
}
测试关联查询
/**
* 测试关联表查询
*/
@Test
public void testGetOrderAmount(){
List<OrderVo> orderAmountList = orderMapper.getOrderAmount();
orderAmountList.forEach(System.out::println);
}
实际查询SQL语句结果

出现了笛卡尔积
配置绑定表bindingTables
在原来水平分片配置的基础上添加如下配置:
t_order_item:
# 实际数据源
actualDataNodes: server-order$->{0..1}.t_order_item$->{0..1}
# 分库策略
databaseStrategy:
standard:
# 分片列名称 当user_id的值是偶数时 ,则路由到server-order0中,当user_id的值是奇数时,则路由到server-order1中
shardingColumn: user_id
# 分片算法名称
shardingAlgorithmName: myinlineuserid
tableStrategy:
standard:
shardingColumn: order_no
shardingAlgorithmName: hashmod
keyGenerateStrategy: # 分布式序列策略
column: id # 自增列名称,缺省表示不使用自增主键生成器
keyGeneratorName: mysnowflake # 分布式序列算法名称
t_dict:
actualDataNodes: server-order$->{0..1}.t_dict,server-user$->{0..1}.t_dict
bindingTables:
- t_order,t_order_item
再次执行testGetOrderAmount

配置完绑定表后再次进行关联查询的测试:
● 如果不配置绑定表:测试的结果为8个SQL。多表关联查询会出现笛卡尔积关联。
● 如果配置绑定表:测试的结果为4个SQL。 多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
绑定表:指分片规则一致的一组分片表。 使用绑定表进行多表关联查询时,必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响查询效率。 分片键不一样时 及时配置了 绑定表 也不会生效
广播表
指所有的分片数据源中都存在的表,表结构及其数据在每个数据库中均完全一致。 适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
广播具有以下特性:
(1)插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
(2)查询操作,只从一个节点获取
(3)可以跟任何一个表进行 JOIN 操作
在server-order0、server-order1和server-user服务器中分别创建t_dict表
CREATE TABLE t_dict(
id BIGINT,
dict_type VARCHAR(200),
PRIMARY KEY(id)
);
配置广播表
bindingTables:
- t_order,t_order_item
broadcastTables:
- t_dict
数据节点可不配置,默认情况下,向所有数据源广播
t_dict: actualDataNodes: server-order$->{0..1}.t_dict,server-user$->{0..1}.t_dict
测试新增广播表
@Autowired
private DictMapper dictMapper;
/**
* 广播表:每个服务器中的t_dict同时添加了新数据
*/
@Test
public void testBroadcast(){
Dict dict = new Dict();
dict.setDictType("type1");
dictMapper.insert(dict);
}
测试结果是每个服务器都插入了数据,而且id都是相同的
测试查询广播表
/**
* 查询操作,只从一个节点获取数据
* 随机负载均衡规则
*/
@Test
public void testSelectBroadcast(){
List<Dict> dicts = dictMapper.selectList(null);
dicts.forEach(System.out::println);
}
可关注公众号 佳哇程序员
或直接扫码关注
















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









