







目录
sklearn转换器和估计器
转换器
特征工程的父类
- 实例化(实例化的是一个转换器类(Transformer))
- 调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
标准化:(x - mean)/ std
fit_transform()
fit() 计算每一列的平均值、标准差
transform()(x - mean)/ std进行最终的转换
估计器(sklearn机器学习算法的实现)
- 实例化一个estimator
- estimator.fit(x_train, y_train)计算,调用完毕,模型生成
- 模型评估
(1)直接比对真实值和预测值
y_predict = estimator.predict(x_test)
y_test == y_predict
(2)计算准确率
accuracy = estimator.score(x_test, y_test)
K-近邻算法
what?
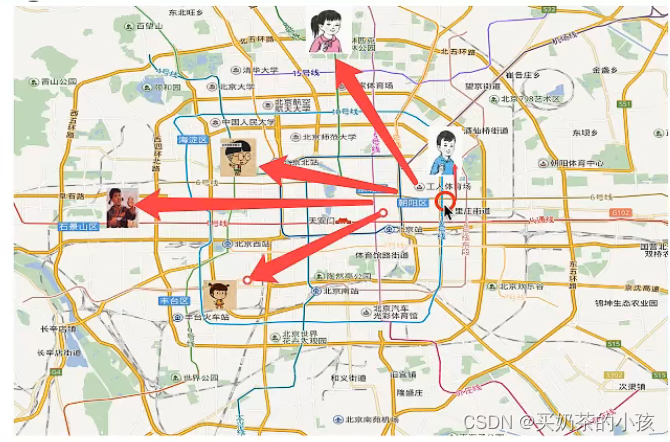
根据邻居推测出自己的类别
K-近邻算法(KNN)原理
如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别
k=1?容易受到异常点的影响
如何确定邻居?
计算距离
距离公式(欧式距离)
如a(a1,a2,a3),b(b1,b2,b3)
曼哈顿距离
明可夫斯基距离
电影类型分析
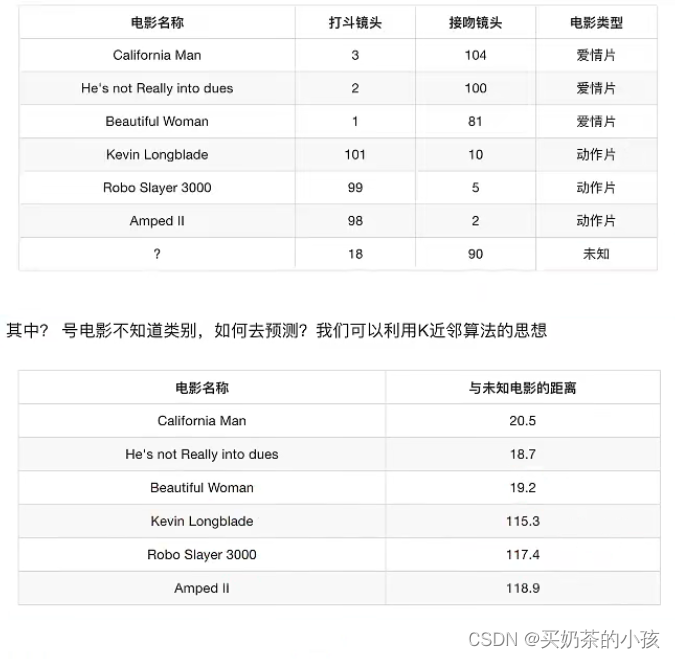
分析
| k = 1 | 爱情片 |
| k = 2 | 爱情片 |
| ... | ... |
| k = 6 | 无法确定 |
| k = 7(新加的一个动作片) | 动作片 |
k值取得过小,容易受到异常点的影响
k值取得过大,样本不均衡的影响
K-近邻算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:k值,int,可选(默认=5),k_neighbors查询默认使用的邻居数
- algorithm:{‘auto’,‘ball_tree’,'kd_tree',‘brute’},可选用于计算最近邻居的算法:‘ball_tree’将会使用BallTree,‘kd_tree’将使用KDTree。‘auto’将尝试根据传递给fit方法的值来决定最合适的算法。(不同实现方式影响效率)
案例1:鸢尾花种类预测
数据集介绍

步骤
- 获取数据
- 数据集划分
- 特征工程:标准化
- KNN预估器流程
- 模型评估
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
def knn_demo():
# 1.获取数据
iris = load_iris()
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 3.特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train, y_train)
# 5.模型评估
# 方法一:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法二:计算准确值
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
if __name__ == "__main__":
knn_demo()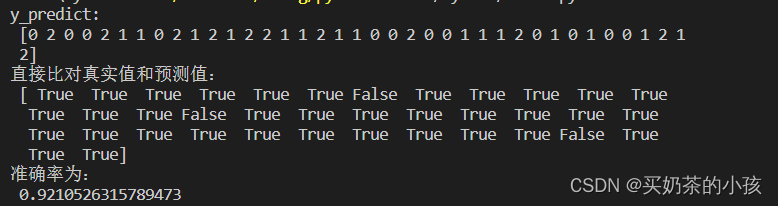 优点:简单,易于理解,易于实现,无需训练
优点:简单,易于理解,易于实现,无需训练
缺点:
- 必须指定K值,K值选择不当则分类精度不能保证
- 懒惰算法,对测试样本分类时的计算量大,内存开销大
使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
模型选择与调优
交叉验证


超参数搜索-网格搜索
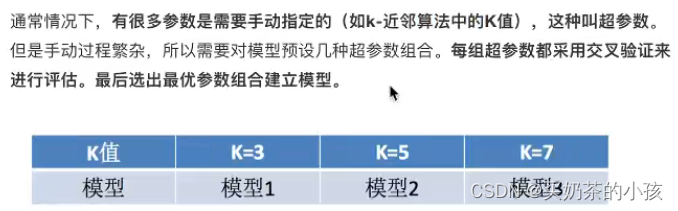
模型选择与调优API

鸢尾花案例增加K值调优
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
def knn_demo():
# 1.获取数据
iris = load_iris()
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=6)
# 3.特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
# 加入网格搜索与交叉验证
#参数准备
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10)
estimator.fit(x_train, y_train)
# 5.模型评估
# 方法一:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法二:计算准确值
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
# 交叉验证结果:vc_results_
print("交叉验证结果:\n", estimator.cv_results_)
if __name__ == "__main__":
knn_demo()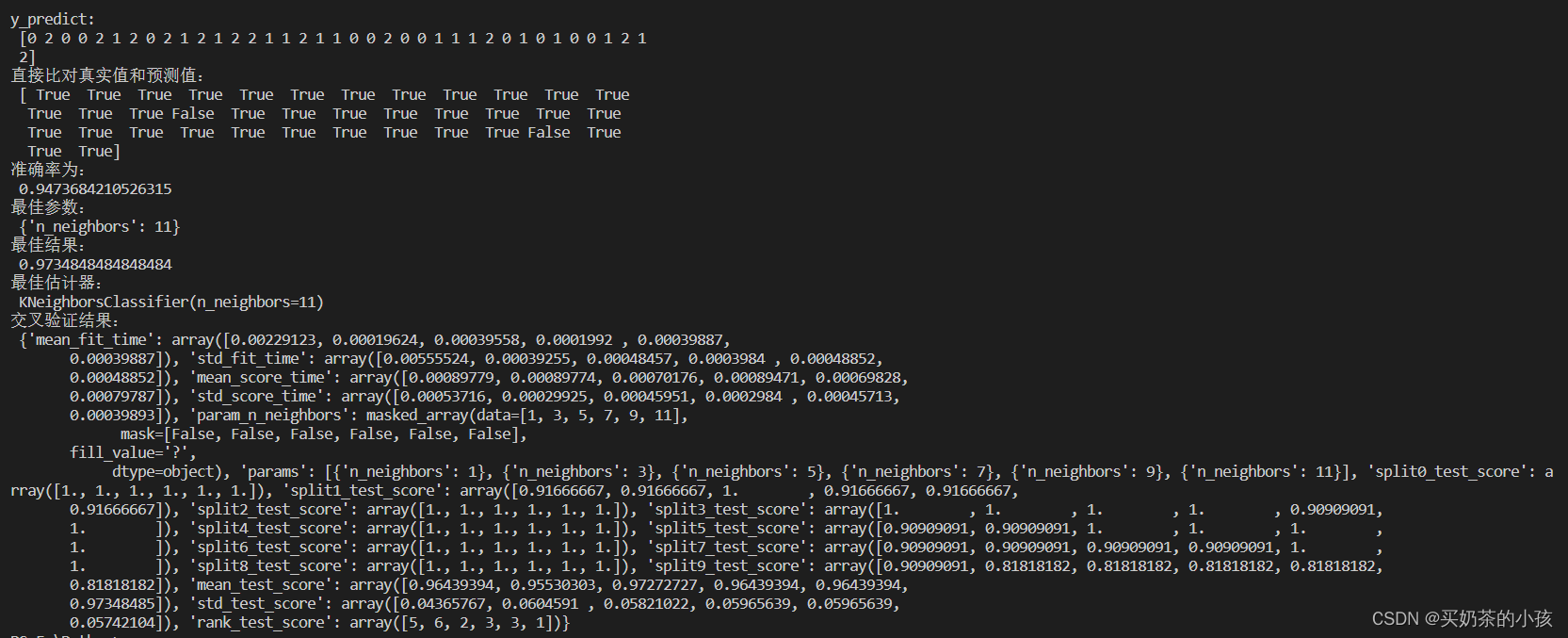
案例:预测facebook签到的位置

流程分析
- 获取数据
- 数据处理
目的:
特征值 x,目标值 y
a.缩小数据范围
2 < x < 2.5
1.0 < y < 1.5
b.time --> 年月日时分秒
c.过滤签到次数少的地点
- 特征工程:标准化
- KNN算法预估流程
- 模型选择与调优
- 模型评估
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
import pandas as pd
def knn_demo():
# 1.获取数据
data = pd.read_csv("train.csv")
# 2.基本的数据处理
# 缩小数据范围
data.query("x < 2.5 & x > 2 & y > 1.0")
# 处理时间特征
time_value = pd.to_datetime(data["time"], unit="s")
date = pd.DatetimeIndex(time_value)
data["day"] = date.day
data["weekday"] = date.weekday
data["hour"] = date.hour
# 3.过滤签到次数少的地点
place_count = data.groupby("place_id").count()["row_id"]
data_final = data[data["place_id"].isin(place_count[place_count > 3].index.values)]
# 筛选特征值和目标值
x = data_final[["x", "y", "accuracy", "day", "weekday", "hour"]]
y = data_final["place_id"]
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y)
# 3.特征工程:标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.KNN算法预估器
estimator = KNeighborsClassifier(n_neighbors=3)
# 加入网格搜索与交叉验证
#参数准备
param_dict = {"n_neighbors": [3, 5, 7, 9]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
estimator.fit(x_train, y_train)
# 5.模型评估
# 方法一:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法二:计算准确值
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 最佳参数:best_params_
print("最佳参数:\n", estimator.best_params_)
# 最佳结果:best_score_
print("最佳结果:\n", estimator.best_score_)
# 最佳估计器:best_estimator_
print("最佳估计器:\n", estimator.best_estimator_)
# 交叉验证结果:vc_results_
print("交叉验证结果:\n", estimator.cv_results_)
if __name__ == "__main__":
knn_demo()朴素贝叶斯算法
概率基础

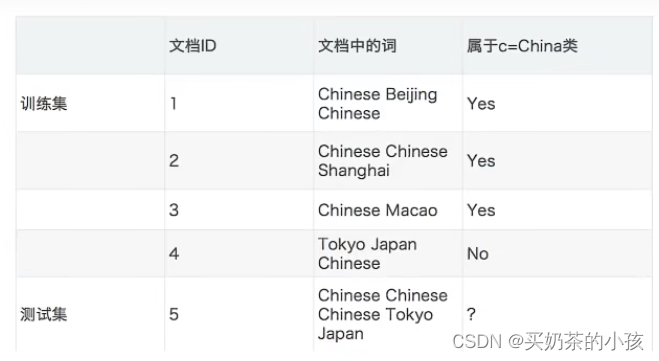


拉普拉斯平滑系数


API
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
案例:20类新闻分类
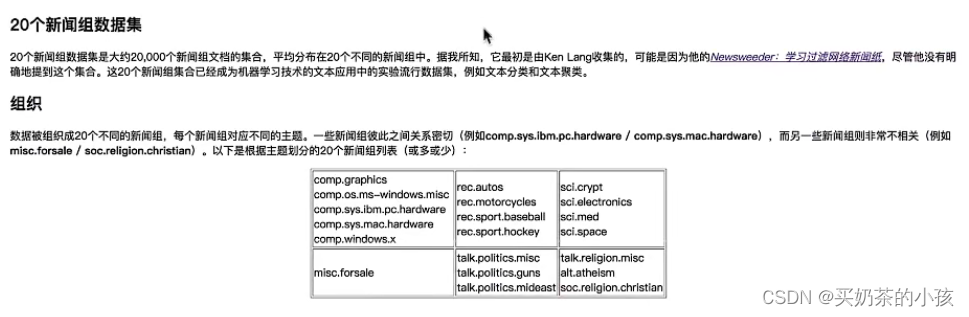
流程分析
- 获取数据
- 划分数据集
- 特征工程:文本特征抽取
- 朴素贝叶斯预估器流程
- 模型评估
优点
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类
- 分类准确度高,速度快
缺点
- 由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from torch import multinomial
def nb_demo():
# 1.获取数据
news = fetch_20newsgroups()
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3.特征工程:文本特征抽取
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.朴素贝叶斯预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5.模型评估
# 方法一:直接对比真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("真实值和预测值对比:\n", y_test == y_predict)
# 方法二:计算准确值
score = estimator.score(x_test, y_test)
print("准确值:\n", score)
if __name__ == "__main__":
nb_demo()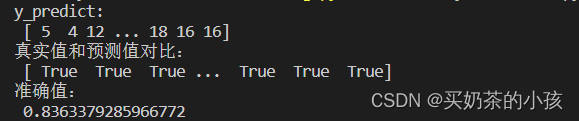
决策树
信息熵

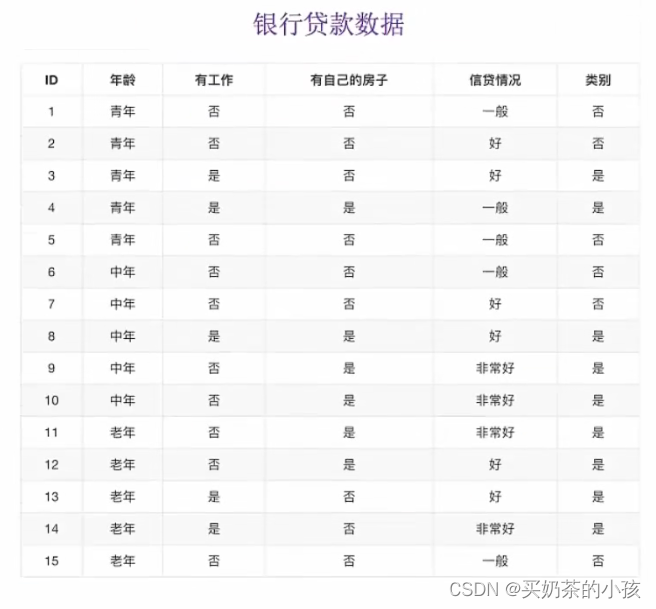
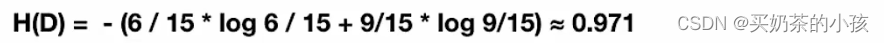
决策树的划分依据之一——信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D和信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
g(D,A)= H(D)- H(D|A)




决策树API

from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
def tree_demo():
# 1.获取数据
iris = load_iris()
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3.决策树预估器
estimator = DecisionTreeClassifier(criterion='entropy')
estimator.fit(x_train, y_train)
# 4.模型评估
# 方法一:直接对比真实值与测试值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("真实值与预测值对比:\n", y_test == y_predict)
# 方法二:计算准确值
score = estimator.score(x_test, y_test)
print("准确值为:\n", score)
if __name__ == "__main__":
tree_demo()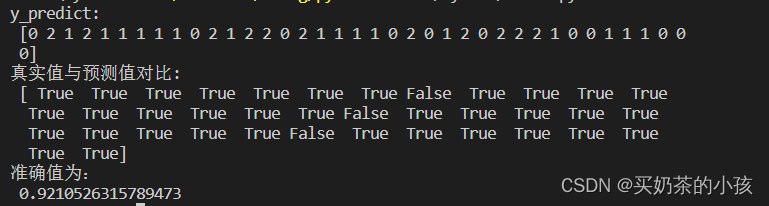
决策树可视化
1.保存树的结构到dot文件

2.把dot文件中的内容粘到网站中生成树的图像
Webgraphviz (我没有加载出来)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def tree_demo():
# 1.获取数据
iris = load_iris()
# 2.划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3.决策树预估器
estimator = DecisionTreeClassifier(criterion='entropy')
estimator.fit(x_train, y_train)
# 4.模型评估
# 方法一:直接对比真实值与测试值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("真实值与预测值对比:\n", y_test == y_predict)
# 方法二:计算准确值
score = estimator.score(x_test, y_test)
print("准确值为:\n", score)
# 决策树可视化
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
if __name__ == "__main__":
tree_demo()案例:泰坦尼克号乘客生存预测



流程分析:特征值 目标值
- 获取数据
- 数据处理:缺失值处理、特征值 --> 字典类型
- 准备好特征值 目标值
- 划分数据集
- 特征工程:字典特征抽取
- 决策树预估器流程
- 模型评估
from pandas import pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier, export_graphviz
def tree_demo():
# 1.获取数据
path = "http..."
titanic = pd.read_csv(path)
# 筛选特征值和目标值
x = titanic[["pclass", 'age', 'sex']]
y = titanic['survived']
# 2.数据处理
# (1)缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# (2)转换成字典
x.to_dict(orient='records')
# 3.数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4.字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 5.决策树预估器
estimator = DecisionTreeClassifier(criterion='entropy')
estimator.fit(x_train, y_train)
# 6.模型评估
# 方法一:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法二:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 可视化决策树
export_graphviz(estimator, out_file='titanic_tree.dot', feature_names=transfer.get_feature_names())
if __name__ == "__main__":
tree_demo()随机森林

原理过程

BootStrap抽样
训练集随机——N个样本中随机有放回的抽样N个
bootstrap 随机有放回抽样
[1,2,3,4,5]
新的树的训练集(不是固定的)
[2,2,3,1,5]
特征随机——从M个特征中随机抽取m个特征
M >> m 降维

API

from pandas import pd
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.feature_extraction import DictVectorizer
def tree_demo():
# 1.获取数据
path = "http..."
titanic = pd.read_csv(path)
# 筛选特征值和目标值
x = titanic[["pclass", 'age', 'sex']]
y = titanic['survived']
# 2.数据处理
# (1)缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# (2)转换成字典
x.to_dict(orient='records')
# 3.数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4.字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 5.加入网格搜索与交叉验证
# 参数准备
param_dict = {'n_estimators':[120,200,300,500,800,1200],'max_depth':[5,8,,15,25,30]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
estimator.fit(x_train, y_train)
# 6.模型评估
# 方法一:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法二:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
if __name__ == "__main__":
tree_demo()













 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









