







目录
C语言读取文件
FILE* file=fopen("file_path","r");
fscanf(file,"%d\n",&i);
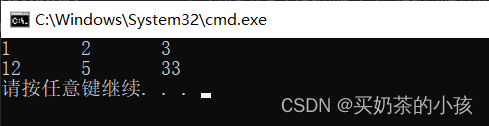
读a.txt文件

#include <stdio.h>
int main() {
int x,y,z;
FILE* file=fopen("./a.txt","r");
for(int s=0;s<2;s++){
fscanf(file,"%d%d%d",&x,&y,&z);
printf("%d\t%d\t%d\n",x,y,z);
}
} 
C语言写文件
FILE* file=fopen("file_path","w");
fprintf(file,"%d\n",i);
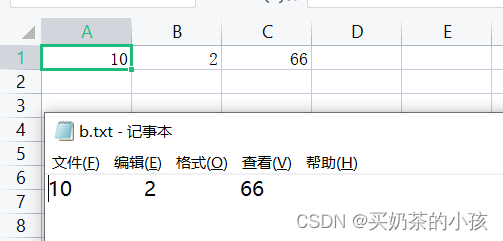
#include <stdio.h>
int main() {
// write
int a=10;
int b=2;
int c=66;
// 写入txt文件
FILE* file=fopen("./b.txt","w");
fprintf(file,"%d\t%d\t%d\n",a,b,c);
// 写入csv文件
// 注意:csv文件要用逗号分隔
file=fopen("./c.csv","w");
fprintf(file,"%d,%d,%d\n",a,b,c);
}
Python读文件
正常读
file = open('file_path','r')
flines = file.readlines()
file = open('./a.txt','r')
flines = file.readlines()
for line in flines:
print(line)
pandas读
import pandas as pd
# read_csv可以读txt文件也可以读csv文件
file = pd.read_csv(file_path)
import pandas as pd
# 直接读
data = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\a.txt')
# 默认读出来的数据是以逗号分隔的
# sep可以设置分隔符
data1 = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\a.txt',sep='\t')
# 默认会把第一行读出来的数据设置成表头
# header可以设置表头
data2 = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\a.txt',sep='\t',header=None)
# 读csv文件的时候分隔符是逗号
data3 = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\c.csv',header=None)
print("=====data======")
print(data)
print("=====data1======")
print(data1)
print("=====data2======")
print(data2)
print("=====data3======")
print(data3)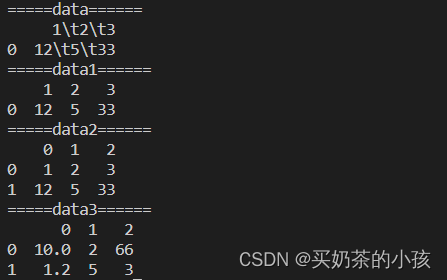
Python读不太正常的文件
缩进不正常

import pandas as pd
# 缩进不正常,有空格还有制表符的数据文件
data4 = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\a.txt',header=None)
# sep='\s+'表示分隔符为任意长度的空格
data5 = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\a.txt',sep='\s+',header=None)
print("=====data4======")
print(data4)
print("=====data5======")
print(data5)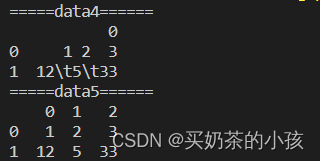
前几行的数据没用/不对

# 前几行的数据没用
# skiprows可以选择跳过几行,数值就是想跳几行
data6 = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\b.txt',header=None,skiprows=2)
print(data6)
读取文件的前几行
# 读数据文件的第一行
total = pd.read_csv(file_path,header=None,sep='\s+',nrows=1,names=['N'])Python将所有数据转换成元组列表
设置表头名称

# names可以设置表头名称
data7 = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\a.txt',names=['X','Y','Z'],sep='\s+',header=None)
print(data7)
将数据打包转换成元组列表
# names可以设置表头名称
data7 = pd.read_csv('F:\\vscode\\Python\\practice\\read_file\\a.txt',names=['X','Y','Z'],sep='\s+',header=None)
# print(data7)
# 将数据打包转换成元组列表
data7_list = list(zip(data7['X'],data7['Y'],data7['Z']))
print(data7_list)
Python写文件
info.to_csv(file_path)
写文件
# 写文件
data_list = [[1,2,3,4],[4,5,6,2]]
# DataFrame中传入列表
info = pd.DataFrame(data_list)
save_data = info.to_csv('F:\\vscode\\Python\\practice\\read_file\\d.txt',header=None,sep='\t')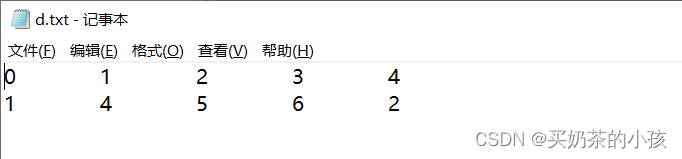
解决自动存索引
写文件的时候会自动把行索引也写进去
# 写文件
data_list = [[1,2,3,4],[4,5,6,2]]
info = pd.DataFrame(data_list)
# index设置索引
save_data = info.to_csv('F:\\vscode\\Python\\practice\\read_file\\d.txt',header=None,sep='\t',index=False)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









