






《KGAT: Knowledge Graph Attention Network for Recommendation》
Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua
阅读报告
2022年9月10日
一 研究目的
本文主要利用协同过滤的思想,通过图神经网络的技术,研究了在推荐任务中通过knowledge graph和user-item graph结合起来,得到协同知识图CKG,捕捉高维连接,发掘高阶信息作为边信息,进而增强用户与物品的交互来预测用户偏好的问题,从而提供更加准确、更多样和更易于解释的推荐。
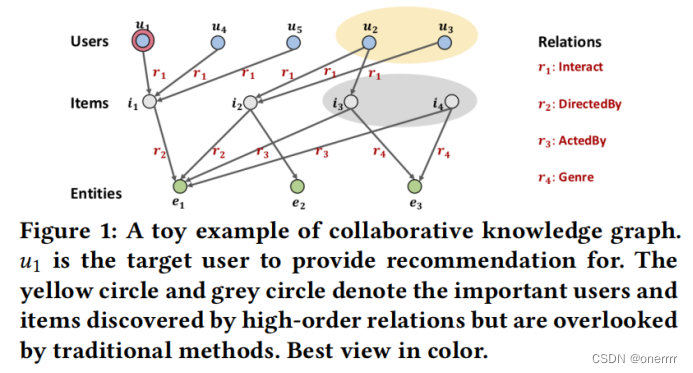
作者首先通过例子,说明将KG和user-item graph结合捕捉高维连接、协作信号的重要性。
CF协同过滤方法,强调寻找相似用户(共同交互某一item),因此通过i1,u1可以找到u4和u5;SL监督学习方法,强调寻找相似物品(具有相同属性),因此通过e1,i1找到i2。
上述方法无法找到u1和u2、u3有关,u1和i3、i4有关。知识图谱是一类能在异构图中学习到实体关系的方法。本文在二部图、知识图谱结合起来的协同知识图谱上学习每一个节点的表达,并基于这样的表达去做推荐预测。
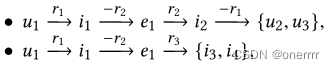
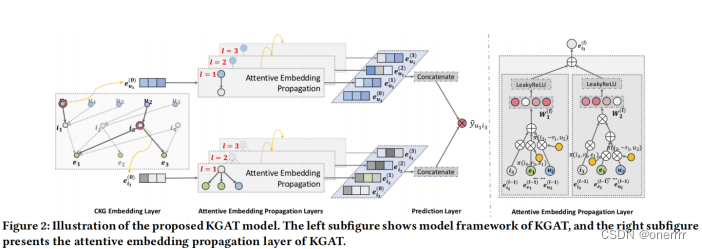
针对目前存在的问题,该研究提出了KGAT模型。其主要有两个特点:
1) 递归的Embedding传播机制
通过邻居节点来更新当前节点的表示,并且该算法能够在线性的时间复杂度上进行递归来捕获高阶连接性(high-order connectivities)。
2) 基于注意的聚合
利用注意力机制来学习传播过程中每个邻居的权重,使得这种权重可以揭示不同高阶连通的重要程度。
二 研究方法
KGAT模型如下图所示,主要包含三个部分:
1、Embedding Layer:通过保留CKG的结构将每个节点参数化为一个向量;
2、Attentive Embedding Propagation Layer:递归地传播节点邻居的Embedding信息以更新其表示,并利用知识感知的注意力机制在传播过程中学习每个邻居的权值;
3、Prediction Layer:集成来自所有传播层的用户和物品的表示,并输出相应的预测评分。
1. Embedding Layer
KGAT采用了广泛应用于知识图谱的TransR方法:
![]()
对于三元组(h, r, t)的似然得分如下(分数越低说明置信度越高,即两个实体之间更有关系):
![]()
通过有效三元组和无效三元组进行区分的思想,训练成对损失函数如下。该层相当于知识表示的regularizar,提升了模型的表示能力。
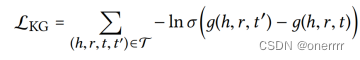
2. Attentive Embedding Propagation Layers
这个部分首先在单层上(如模型图中Attentive Embedding Propagation Layer部分是通过三个叠加layer组成,这里为了便于理解先从单层的角度出发)介绍其三个组成部分,再将其推广到多层上。
- Information Propagation
对于实体h(head entity),通过 Nh 表示三元组集合,称为ego-network。通过如下公式,这种线性组合的思想刻画了实体h的一阶连接结构。
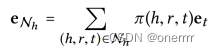
其中π(h,r,t)控制在关系(h,r,t)中实体间传播的衰减系数,其作用是:表示出通过关系r有多少信息能够从t传播到h。
(2) Knowledge-aware Attention
通过注意力机制对π(h,r,t)公式化如下。在relation上距离更近的实体间会传递更多的信息。
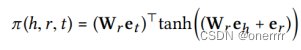
通过softmax函数对所有与h相连的三元组的系数进行归一化:
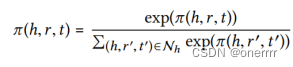
(3) Information Aggregation
该模块的作用:将前两层的结果(实体表示和ego-network表示)进行集成,作为实体h新的表示形式:
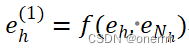
其中f()有三种不同的集成方式:
- GCN Aggregator:
![]()
- GraphSage Aggregator:
![]()
- Bi-Interaction Aggregator:(实验部分证明了该形式效果更好,由于其加入了feature-interaction,对实体间关系的敏感性更强)
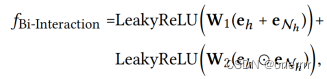
(4) High-order Propagation
通过多层传播可以捕获更多信息(多跳邻居所传播的)。在步骤l处,递归地将一个实体表示如下:
![]()
其中,
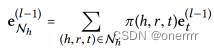
3. Model Prediction
预测评分:
![]()
其中,用户和物品表示是通过layer-aggregation机制,将不同层的输出所强调的连接信息进行集成:
![]()
4. Optimization
通过BPR损失函数对推荐模型进行优化,观察到的交互表示出用户的偏好,那么相应就应该有更高的预测评分。
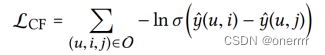
将该损失项与上述公式结合,定义最终的目标优化函数:
![]()
三 实验
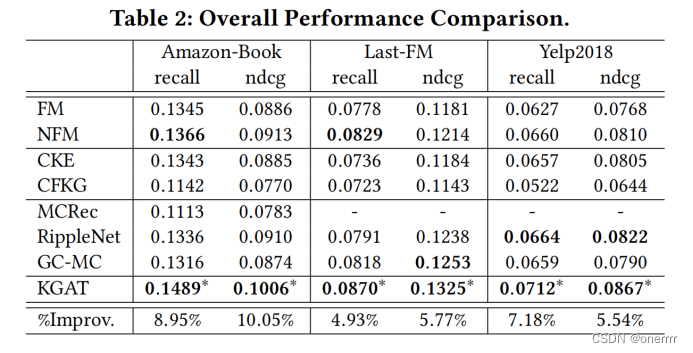
本文在三个数据集上比较了KGAT模型跟其它经典模型的recall值和ndcg值,结果如下表所示。
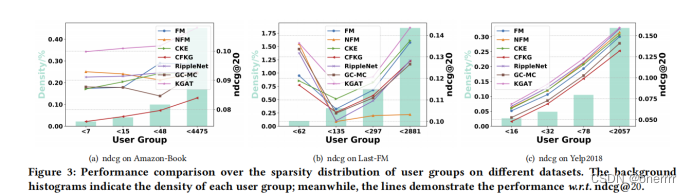
利用KG的一个动机是缓解稀疏性问题,这通常限制了推荐系统的表达能力。对于交互较少的非活动用户,很难建立最佳表示。在此,本文将研究利用连接信息是否有助于缓解此问题。
每个用户的交互次数将测试集分为四组,同时尝试保持不同的组具有相同的总交互。以Amazon图书数据集为例,每个用户的交互次数分别小于7、15、48和4475。下表显示了在不同数据集上不同用户组上的结果。















 2923
2923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









