







标题:词法分析器
本人最近在学习编译原理,刚刚学到词法分析器,心想着挺好玩,就想着自己写一个,奈何一没有系统的学过c语言,只是粗略的看过一遍K&R的c语言书,所以水平尚浅,代码有许多冗长之处,二是刚学这一块,有些概念还不太清楚,本着练习c语言的目的将词法分析器写完。大家借鉴借鉴就好,如果有需要的小伙伴可自取自行修改。我看的编译原理是鲁斌的一本编译原理与实践(不建议小伙伴看,这本书代码很不全,而且有错误,但是本校还没发书,所以只好用这本),编写的是L语言----一种类Pascal语言。
废话不多说,上正题:
词法分析器,又称为扫描器,功能是输入源程序,进行词法分析,输出单词符号。
对于一个词法分析器来说,应该执行的功能为:
1:对源程序进行预处理工作,包括滤掉源程序中的无用程序,如注释,空格,换行,等不影响程序语法,语义的结构。(至少可以滤掉空格,其他可自行添加)
2:对源程序出现的非法字符进行检查
3:可建立符号表,用于记录源程序中的标识符和常数的信息,包括名称,各种属性等。
词法分析器主要依据语法规则进行工作,本篇用到的所有词法皆在L_Word.txt文件里,下面以图片形式给出。
描述词法分析器规则的有效工具主要是正规式和有限自动机(本人还没学到这,但写词法分析器也没用到)
实现的功能:
能够识别关键字,标识符,整数,浮点数,指数,一些运算符和界符。
能够对输入的源代码进行分析,输出各种标识符,及其他们的种别编码,及其在符号表中的地址(本篇输出的都是零,也就是word.addr,没有实现,小伙伴可自行实现)
注:
1:没有实现过滤注释的功能。
2:没有实现符号表
3:没有实现字符类型,布尔类型
另外注明一点:宏定义#define MAXWORD 100 处,如果将MAXWORD定义的小了,可能经词法分析器输出的要比源程序的词少,具体原因没有找(懒)
各种文件如下:
L_Word.txt文件如下:
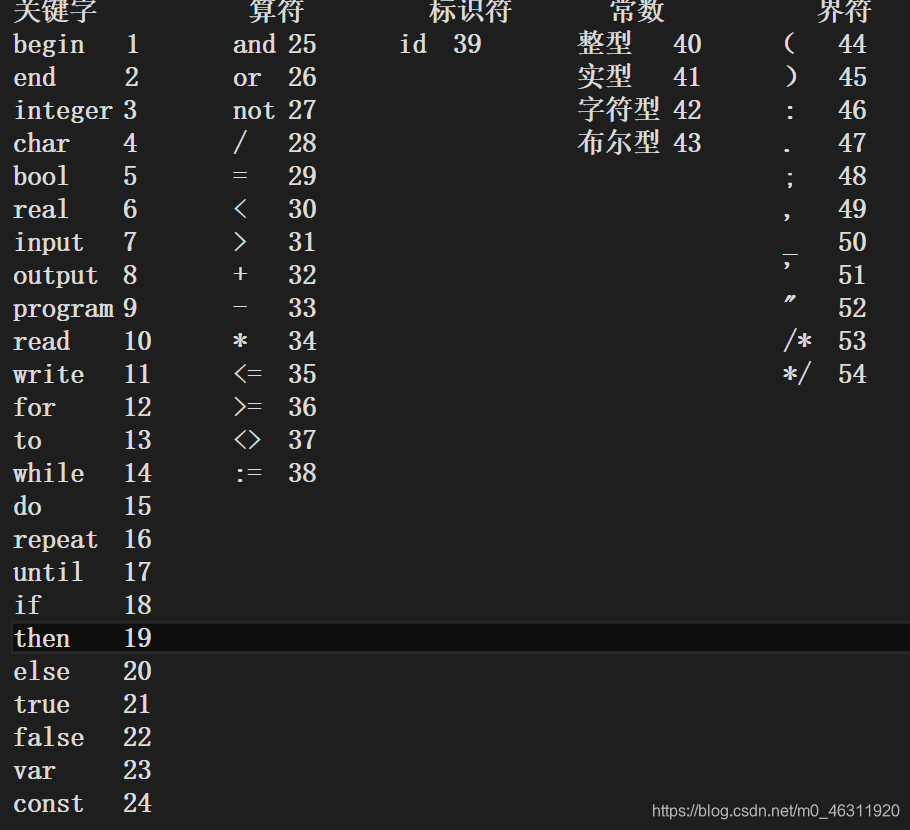
代码部分
代码分为三部分
第一部分为头文件
L_h文件,内有要用到的库函数及宏
#pragma once
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100 //定义最长的标识符不可以超过100
/*token结构,词法分析器识别出的信息用此结构标识*/
typedef struct WordToken {
int code; //单词种别编码,L语言编码在L_Word.txt文件中
int addr; //单词在符号表中登记项的指针,仅用于标识符和常数,其他情况下是零
}WT;
/*L语言关键字*/
extern char Keywordtab[27][10];
void sort(char ch[]);
int reserve(char str[]);
代码所用关键字为Key.cpp,内含关键字和三种运算符and or not
#pragma once
char Keywordtab[27][10] = { "begin","end", "integer", "char", "bool","real","input", "output",
"program","read","write","for", "to", "while", "do", "repeat","until", "if", "then", "else",
"true","false","var","const","and","or","not" };
主要代码文件为sort.cpp
#pragma once
#include "L.h"
/*用来识别不同类型单词符号*/
void sort(char ch[]) {
int reserve(char str[]);
int p = 0;
while (ch[p] != '\0') {
while (ch[p] == ' ')
p++;
int i = 0;
char str[MAXWORD] = {};
WT word;
word.addr = 0;
if (isalpha(ch[p])) { //如果首字符是字母
WT word;
word.addr = 0;
do {
str[i++] = ch[p++];
} while (isalpha(ch[p]) || isdigit(ch[p]));
str[i] = '\0';
word.code = reserve(str); //是-1没找到关键字
if (word.code == -1)
word.code = 39;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
}
else if (isdigit(ch[p])) {
word.addr = 0;
do {
str[i++] = ch[p++];
} while (isdigit(ch[p])); //出循环时,ch[p]已不是数字
if (ch[p] == '.') { //判断如12.7型的浮点数
str[i] = ch[p];
i++, p++;
while (isdigit(ch[p]))
str[i++] = ch[p++];
str[i] = '\0';
word.code = 41;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
}
else if (ch[p] == 'e') {
str[i] = ch[p];
i++, p++;
if (ch[p] == '-') { //判断例如12e-7型的指数
str[i] = ch[p];
i++, p++;
while (isdigit(ch[p]))
str[i++] = ch[p++];
str[p] = '\0';
word.code = 41;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
}
else //判断例如2e3型的指数
{
while (isdigit(ch[p]))
str[i++] = ch[p++];
str[i] = '\0';
word.code = 41;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
}
}
else //判断例如148型的整数
{
str[i] = '\0';
word.code = 40;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
}
}
/*有争议的字符*/
else if (ch[p] == '/')
{
if (ch[p + 1] == '*') {
str[0] = ch[p];
str[1] = ch[p+1];
str[2] = '\0';
word.code = 53;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p = p + 2;
}
else
{
str[0] = ch[p];
str[1] = '\0';
word.code = 28;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p++;
}
}
else if (ch[p] == '*')
{
if (ch[p + 1] == '/') {
str[0] = ch[p];
str[1] = ch[p+1];
str[2] = '\0';
word.code = 54;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p = p + 2;
}
else
{
str[0] = ch[p];
str[1] = '\0';
word.code = 34;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p++;
}
}
else if (ch[p] == '<')
{
if (ch[p + 1] == '=') {
str[0] = ch[p];
str[1] = ch[p+1];
str[2] = '\0';
word.code = 35;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p = p + 2;
}
else if (ch[p + 1] == '>')
{
str[0] = ch[p];
str[1] = ch[p+1];
str[2] = '\0';
word.code = 37;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p = p + 2;
}
else
{
str[0] = ch[p];
str[1] = '\0';
word.code = 30;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p++;
}
}
else if (ch[p] == '>')
{
if (ch[p + 1] == '=') {
str[0] = ch[p];
str[1] = ch[p+1];
str[2] = '\0';
word.code = 36;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p = p + 2;
}
else
{
str[0] = ch[p];
str[1] = '\0';
word.code = 31;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p++;
}
}
else if (ch[p] == ':')
{
if (ch[p + 1] == '=') {
str[0] = ch[p];
str[1] = ch[p+1];
str[2] = '\0';
word.code = 38;
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p = p + 2;
}
else
{
word.code = 46;
printf("%c\t%d\t%d\n", ch[p], word.code, word.addr);
p++;
}
}
/*无争议字符*/
else {
switch (ch[p])
{
case '=': word.code = 29; str[0] = ch[p]; str[1] = '\0'; break;
case '-': word.code = 33; str[0] = ch[p]; str[1] = '\0'; break;
case '+': word.code = 32; str[0] = ch[p]; str[1] = '\0'; break;
case '(': word.code = 44; str[0] = ch[p]; str[1] = '\0'; break;
case ')': word.code = 45; str[0] = ch[p]; str[1] = '\0'; break;
case '.': word.code = 47; str[0] = ch[p]; str[1] = '\0'; break;
case ';': word.code = 48; str[0] = ch[p]; str[1] = '\0'; break;
case ',': word.code = 49; str[0] = ch[p]; str[1] = '\0'; break;
case '_': word.code = 50; str[0] = ch[p]; str[1] = '\0'; break;
case '\'': word.code = 51; str[0] = ch[p]; str[1] = '\0'; break;
case '\"': word.code = 52; str[0] = ch[p]; str[1] = '\0'; break;
}
printf("%s\t%d\t%d\n", str, word.code, word.addr);
p++;
}
}
}
int reserve(char str[])
{
for (int i = 0; i<27; i++)
{
if (strcmp(str, Keywordtab[i]) == 0)
{
return i + 1; //关键字的种别码为i+1 的值
}
}
return -1; //没有找到关键字
}
主函数如下:
#pragma once
#include "L.h"
int main()
{
char ch[] = "var x , y , z : real; x := y + z * 60;";
printf("经词法分析器分析结果后如下:\n");
sort(ch);
}
结果如下:

上述代码在vs2015上运行
本人写博客目的只为加深对词法分析器的理解,代码或有错误,感兴趣的小伙伴可自行下载。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









