







学习目标
笔记
1 超参数调整
1.1 超参数调整过程
调整的参数:(按照重要性排序)
(1)学习率
α
\alpha
α;
(2)
β
\beta
β,隐藏层的神经元数量,小批量的大小;
(3)隐藏层数量,学习率衰减。
选择最优的参数组合:
(1)当数据集很小时,可以用网格遍历的方式;
(2)当数据集较大时,用随机方式选择参数;
(3)一种对随机取值的改进(从粗到精的策略):先大范围粗略随机选值,根据结果缩小参数范围,在小范围中以更高的密度进行随机抽样取值。
两种调整参数的策略:
熊猫:仔细在一个模型上微调参数;
鱼子酱:在算力允许的情况下,在多个模型上尝试多种参数组合。
1.2 使用合适的标准选择超参数
1.2.1 学习率 α \alpha α的标准
当 α \alpha α的取值范围是0.0001~1时,采用均匀随机抽样就显得很不合适了,此时应该采用对数随机抽样。如下代码块所示,当r=-4时,a=0.0001,当r=0时,a=1。
import numpy as np
r = -4 * np.random.rand() #返回一个或一组服从0~1均匀分布的随机样本值。随机样本取值范围是[0,1)。
a = 10**r
1.2.2 指数加权平均 β \beta β的标准
β \beta β的取值范围一般在0.9~0.999之间,则 1 − β 1-\beta 1−β 在0.1~0.001之间,利用对数随机取值得到 1 − β 1-\beta 1−β的值。
2 批量归一化(Batch Normalization)
作用:使神经网络更稳健,从而对超参数的选择不那么敏感,使超参数的选择变得更简单,有利于训练更深的网络。
思路:类似于特征归一化作用于输入变量,批量归一化作用于隐藏层的 Z [ l ] Z^{[l]} Z[l]。
公式:
μ
=
1
m
∑
i
Z
[
l
]
(
i
)
\mu = \frac{1}{m} \sum\limits_{i}Z^{[l](i)}
μ=m1i∑Z[l](i)
σ
2
=
1
m
∑
i
(
Z
[
l
]
(
i
)
−
μ
)
2
\sigma^2 = \frac{1}{m} \sum\limits_{i}(Z^{[l](i)}-\mu)^2
σ2=m1i∑(Z[l](i)−μ)2
Z
n
o
r
m
(
i
)
=
Z
[
l
]
(
i
)
−
μ
σ
2
+
ϵ
Z_{norm}^{(i)} = \frac{Z^{[l](i)}-\mu}{\sqrt{\sigma^2+\epsilon}}
Znorm(i)=σ2+ϵZ[l](i)−μ
Z
~
[
l
]
(
i
)
=
γ
∗
Z
n
o
r
m
(
i
)
+
β
\widetilde{Z}^{[l](i)} = \gamma * Z_{norm}^{(i)} + \beta
Z
[l](i)=γ∗Znorm(i)+β
批量归一化与特征归一化不同的一点是,有时候我们并不希望归一化后的Z的均值为0、方差为1,通过修正均值和方差(
β
\beta
β和
γ
\gamma
γ)可以使我们更好地利用下一步激活函数的非线性特征。
注:在测试时,对单一样本进行预测,这就需要在训练过程中记录均值和方差的指数加权平均值,然后再用到测试中。
3 多分类回归——Softmax
3.1 Softmax计算
Softmax是Logistic回归在多分类问题中的推广。对于三个及以上的分类问题,要采用Softmax作为输出层的激活函数。
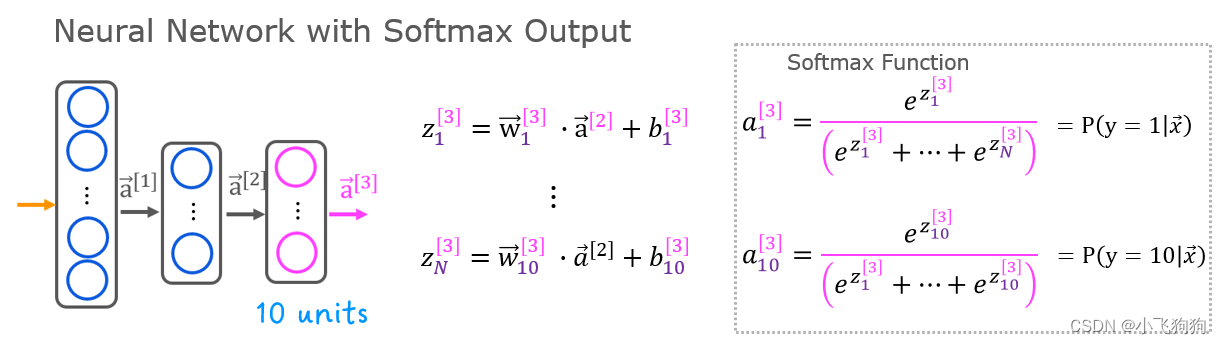
def softmax(z):
exp_sum = 0
for k in range(z.shape[0]):
exp_sum = exp_sum + np.exp(z[k])
a = np.exp(z)/exp_sum #按元素做除法
return a
3.2 Softmax实现
在具体的模型实现时,softmax搭配categorical_crossentropy函数使用,该函数公式如下:
 因为yi,要么是0,要么是1。而当yi等于0时,结果就是0,当且仅当yi等于1时,才会有结果。也就是说categorical_crossentropy只专注与一个结果,因而它一般配合softmax做单标签分类。
因为yi,要么是0,要么是1。而当yi等于0时,结果就是0,当且仅当yi等于1时,才会有结果。也就是说categorical_crossentropy只专注与一个结果,因而它一般配合softmax做单标签分类。
参考:损失函数:categorical_crossentropy
需要注意的地方
1.批量归一化的tensorflow实现;
2.熟悉tf的操作。















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









