







学习目标
学会对特征变量进行缩放。
笔记
1 为什么进行特征缩放(Feature Scaling)
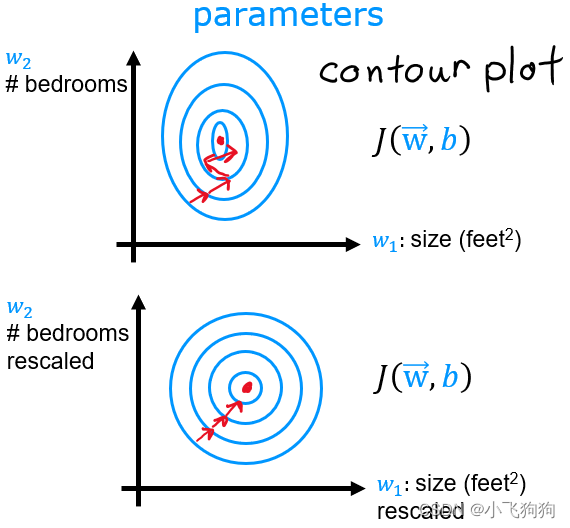
加快学习曲线(Loss-iterations)收敛,减少振荡。观察下面的损失等高线图(cost contour plot),中心是损失最低点。不对特征进行缩放时(上图),等高线图非常不对称;特征缩放后,等高线图更加对称,表明梯度下降可以使得每个参数都平等地靠近损失最低点,此时也可以使用更大的学习率。
2 特征缩放的四种方式
最早的方式:适用于较为简单的特征。 x i : = x i m a x x_i := \dfrac{x_i }{max} xi:=maxxi
通用方式:适用于任何特征。 x i : = x i − m i n m a x − m i n x_i := \dfrac{x_i - min}{max - min} xi:=max−minxi−min
均值标准化(Mean normalization):
x
i
:
=
x
i
−
μ
i
m
a
x
−
m
i
n
x_i := \dfrac{x_i - \mu_i}{max - min}
xi:=max−minxi−μi
Z标准化(Z-score normalization):将特征j的均值转化为0,标准差转化为1。其中,
μ
j
\mu_j
μj是特征j的均值,
σ
j
\sigma_j
σj是特征j的标准差。
x
j
(
i
)
=
x
j
(
i
)
−
μ
j
σ
j
x^{(i)}_j = \dfrac{x^{(i)}_j - \mu_j}{\sigma_j}
xj(i)=σjxj(i)−μj
需要注意的地方
在对training set的数据进行缩放时,要注意保存max、min、 μ \mu μ、 σ \sigma σ等值,因为模型训练好后对dev set进行预测时还要再次使用这些值对dev set的特征数据进行缩放。















 3134
3134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









