







pandas数据清洗:drop函数、dropna函数、drop_duplicates函数详解
1 drop函数简介
drop函数:用来删除数据表格中的列数据或行数据
df.drop(labels=None,axis=0
,index=None
,columns=None
,inplace=False)
| 参数 | 简介 |
|---|---|
| labels | 以列表形式赋值,待删除的行名或列名,与axis参数一起使用 |
| axis | 确定删除行还是列,0为行,1为列 |
| index | 以列表形式赋值,删除第几行;不与labels和axis参数连用 |
| columns | 以列表形式赋值,删除第几列;不与labels和axis参数连用 |
| inplace | 是否用新生成的列表替换原列表 |
1.1 构建学习数据
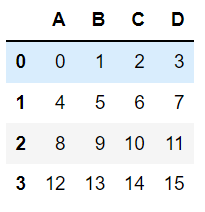
df = pd.DataFrame(np.arange(16).reshape(4, 4),
columns=['A', 'B', 'C', 'D'])
1.2 删除行两种方法
方法一:使用index参数 []内是索引名,不是序号,要注意!
df.drop(index=[0,1],inplace=False)
方法二:使用labels和axis参数
df.drop(labels=[0,1],axis=0,inplace=False)
两者效果一样

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









