









 本文详细介绍了图像分类的评价指标,如正确率、错误率、灵敏度、特效度、精度、召回率,并探讨了目标检测中的IoU、置信度以及PR图、AP、mAP等关键概念和计算方法,揭示了多目标跟踪中的MOTA和MOTP指标,为理解和评估视觉算法提供了全面指导。
本文详细介绍了图像分类的评价指标,如正确率、错误率、灵敏度、特效度、精度、召回率,并探讨了目标检测中的IoU、置信度以及PR图、AP、mAP等关键概念和计算方法,揭示了多目标跟踪中的MOTA和MOTP指标,为理解和评估视觉算法提供了全面指导。
目录
一.图像分类
评价指标
1)True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
2)False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
3)False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
4)True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
| Column 1 | 相关(Relevant),正类 | 无关(NonRelevant),负类 |
|---|---|---|
| 被检索到(Retrieved) | true positives(TP 正类判定为正类,例子中就是正确的判定"这位是女生") | false positives(FP 负类判定为正类,“存伪”,例子中就是分明是男生却判断为女生,当下伪娘横行,这个错常有人犯) |
| 未被检索到(Not Retrieved) | false negatives(FN 正类判定为负类,“去真”,例子中就是,分明是女生,这哥们却判断为男生–梁山伯同学犯的错就是这个) | true negatives(TN 负类判定为负类,也就是一个男生被判断为男生,像我这样的纯爷们一准儿就会在此处) |

1)正确率(accuracy)
正确率是我们最常见的评价指标,accuracy = (TP+TN)/(P+N),这个很容易理解,就是被分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好;
2)错误率(error rate)
错误率则与正确率相反,描述被分类器错分的比例,error rate = (FP+FN)/(P+N),对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate;
3)灵敏度(sensitive)
sensitive = TP/P,表示的是所有正例中被分对的比例,衡量了分类器对正例的识别能力;
4)特效度(specificity)
specificity = TN/N,表示的是所有负例中被分对的比例,衡量了分类器对负例的识别能力;
5)精度(precision)
精度是精确性的度量,表示被分为正例的示例中实际为正例的比例,precision=TP/(TP+FP);
6)召回率(recall)
召回率是覆盖面的度量,度量有多个正例被分为正例,recall=TP/(TP+FN)=TP/P=sensitive,可以看到召回率与灵敏度是一样的。
7)其他评价指标
计算速度:分类器训练和预测需要的时间;
鲁棒性:处理缺失值和异常值的能力;
可扩展性:处理大数据集的能力;
可解释性:分类器的预测标准的可理解性,像决策树产生的规则就是很容易理解的,而神经网络的一堆参数就不好理解,我们只好把它看成一个黑盒子。
二.目标检测
1.基本概念
IoU(交并比)
交并比IoU衡量的是两个区域的重叠程度,是两个区域重叠部分面积占二者总面积(重叠部分只计算一次)的比例。如下图,两个矩形框的IoU是交叉面积(中间图片红色部分)与合并面积(右图红色部分)面积之比。
Confidence(置信度)
置信度是每个bounding box输出的其中一个重要参数,作者对他的作用定义有两重:
一重是:代表当前box是否有对象的概率 注意,是对象,不是某个类别的对象,也就是说它用来说明当前box内只是个背景(backgroud)还是有某个物体(对象);
另一重:表示当前的box有对象时,它自己预测的box与物体真实的box可能的I O U p r e d t r u t h
IOU^{truth}_{pred}IOU pred truth 的值,注意,这里所说的 物体真实的box实际是不存在的
,这只是 模型表达自己框出了物体的自信程度。
yolov3 在网络最后的输出中,对于每个grid cell产生3个bounding box,每个bounding box的输出有三类参数:
一个是对象的box参数,一共是四个值,即box的中心点坐标(x,y)和box的宽和高(w,h);
一个是置信度,这是个区间在[0,1]之间的值;
最后一个是一组条件类别概率,都是区间在[0,1]之间的值,代表概率。
:
拿SSD为例:
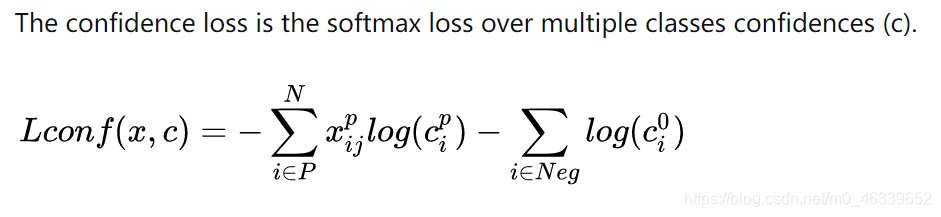
其中的 就是softmax,也就是我们可以根据网络前向计算得到的概率值处理下的结果。我觉得使用conf而不是简单的概率主要是针对多分类和剔除Neg Sample 的loss 的目的吧。。负样本我们没必要再去loss优化了。。。
2.评价指标
1.PR图
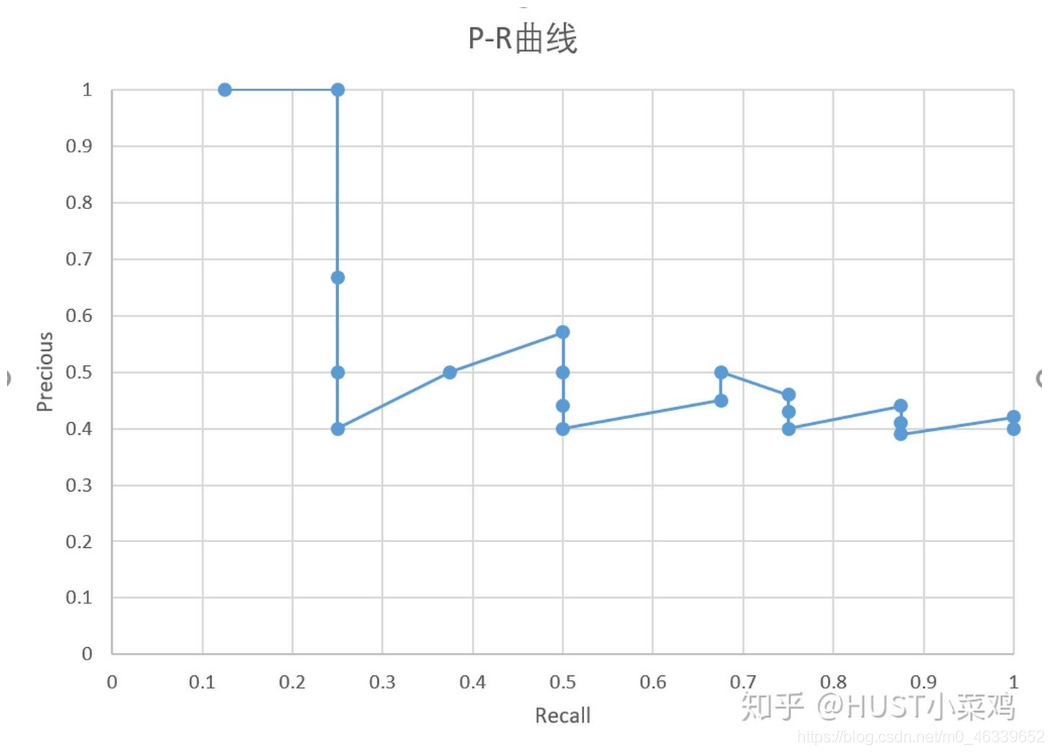
1、PR图
由上表以Recall值为横轴,Precision值为纵轴,我们就可以得到PR曲线。我们会发现,Precision与Recall的值呈现负相关,在局部区域会上下波动。
2.AP(Average Precision)
AP为平均精度,使用积分的方式来计算PR曲线与坐标轴围成的面积
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/b39ffc71a04398792ec64f94903c2793.png)
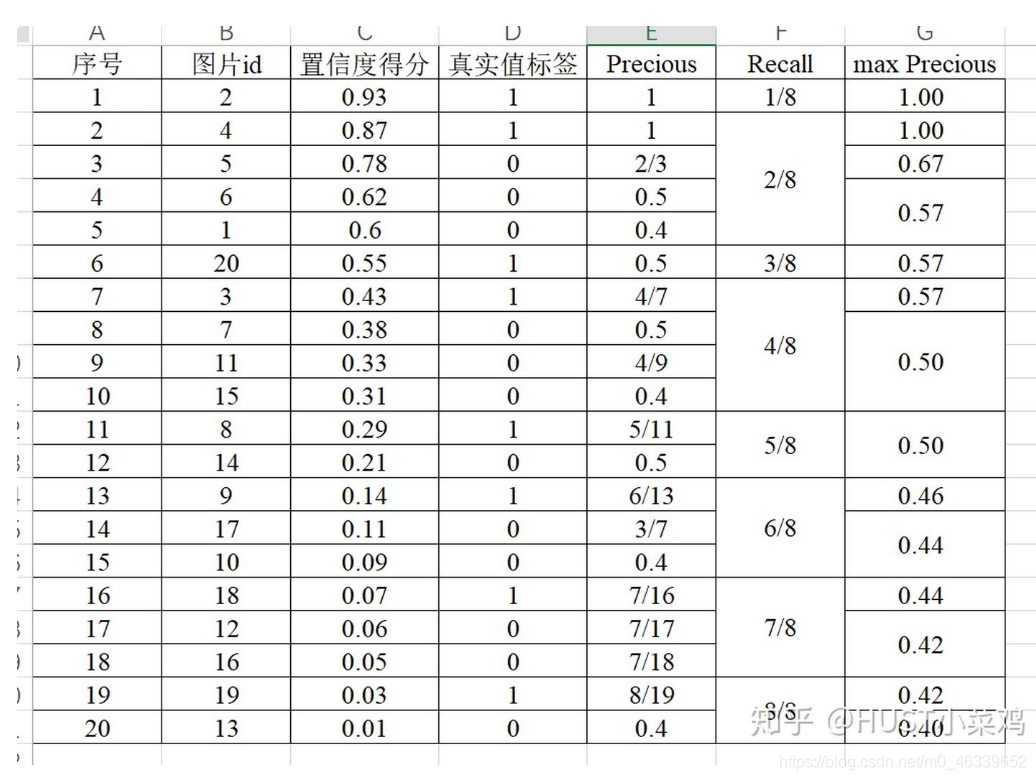
但是在实际应用中,我们不是去对其进行计算,而是对其平滑操作来简化计算,对PR曲线上的每个点,Precision的值取该点右侧最大的Precision的值,结果如下图所示:
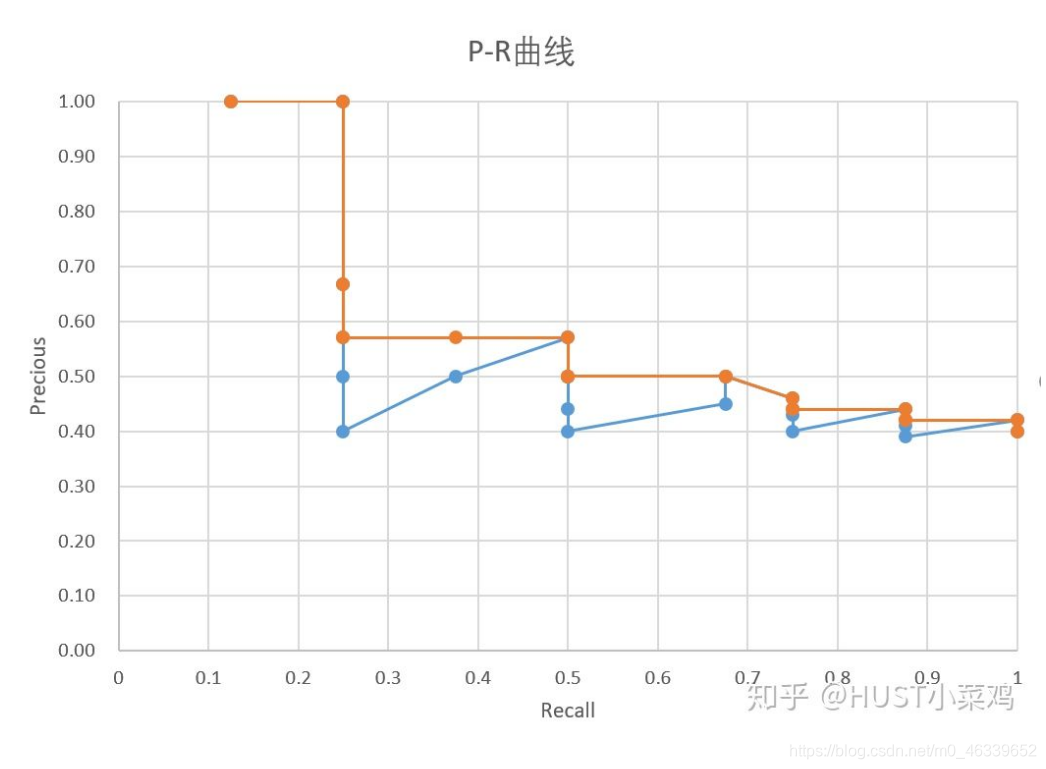
计算出AP之后,对所有的类别的AP求平均就可以得出整个数据集上的mAP。
3.MAP(Mean Average Precision)
不同的数据集给出不同的mAP的计算方法
检测出来的bbox包含score和bbox,按照score降序排序,所以每添加一个样本,就代表阈值降低一点(真实情况下score降低,iou不一定降低)。这样就是可以有很多种阈值,每个阈值情况下计算一个Precious和Recall。
使用区域选择算法得到候选区域
对候选区域,计算每一个候选区域和标定框(groud truth)的iou
设定一个iou阈值,大于这个的标为正样本,小于的标为负样本,由此得到一个类似于分类时的测试集。
将给定的测试集(正负样本),通过分类器,算出每一个图片是正样本的score
设定一个score阈值,大于等于此值的视作正样本,小于的作为正样本
根据上一步的结果可以算出准确率和召回率
调节score阈值,算出召回率从0到1时的准确率,通过计算所有类的AP就可以计算mAP了。
1、Interplolated AP(Pascal Voc 2008 的AP计算方式)
Pascal VOC 2008中设置IoU的阈值为0.5,如果一个目标被重复检测,则置信度最高的为正样本,另一个为负样本。在平滑处理的PR曲线上,取横轴0-1的10等分点(包括断点共11个点)的Precision的值,计算其平均值为最终AP的值。
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/ced0911700ccaf65e3ebe355447b1caa.png)
2、MS COCO mAP
对于coco数据集来说,使用的也是Interplolated AP的计算方式。与Voc 2008不同的是,为了提高精度,在PR曲线上采样了100个点进行计算。而且Iou的阈值从 0.5 - 0.95 的区间上每隔0.05计算一次mAP的值,取所有结果的平均值作为最终的结果。除了AP,还有 [公式] , [公式] 等值,分别代表了如下含义:
A P 50 AP_{50} AP50:阈值为0.5时的AP测量值
A P 75 AP_{75} AP75:IoU阈值为0.75时的测量值
A P S AP_{S} APS : 像素面积小于 3 2 2 32^2 322 的目标框的AP测量值(小尺度)
A P M AP_{M} APM : 像素面积在 3 2 2 32^2 322~ 9 6 2 96^2 962之间目标框的测量值(中等尺度)
A P L AP_{L} APL : 像素面积大于 9 6 2 96^2 962 的目标框的AP测量值(大尺度)
通常来说AP是在单个类别下的,mAP是AP值在所有类别下的均值。在这里,在coco的语境下AP便是mAP,这里的AP已经计算了所有类别下的平均值,这里的AP便是mAP。
三.目标跟踪
CLEAR MOT Metrics认为一个好的多目标跟踪器应该有如下三点特性:
1.所有出现的目标都要能够及时找到(检测的性能)
2.找到目标位置要尽可能可真实目标位置一致(检测的性能)
3.保持追踪一致性,避免跟踪目标的跳变 (匹配的性能)
所以可以看出,多目标跟踪和目标检测是密不可分的,检测的性能不可避免的会对跟踪的性能造成影响。
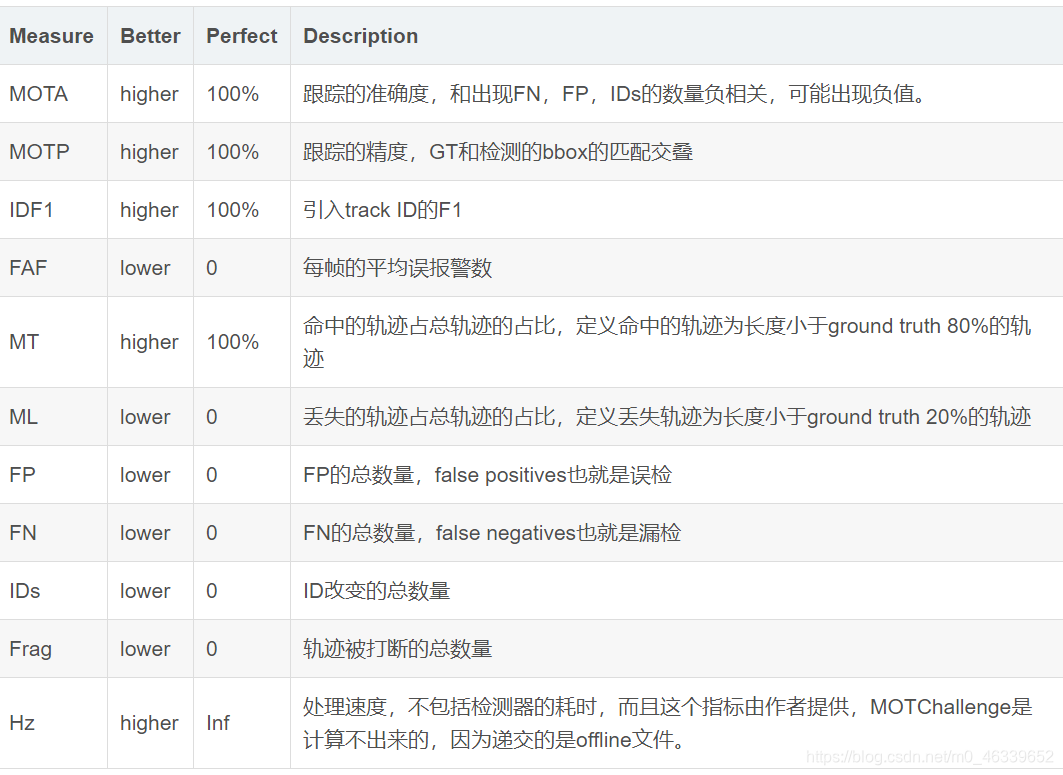
MOTA
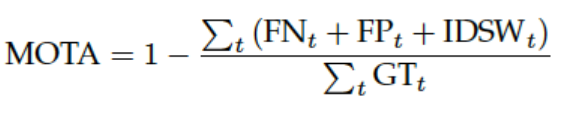
其中,FN为False Negative,FP为False Positive,IDSW为ID Switch,GT为Ground Truth 物体的数量。MOTA考虑了tracking中所有帧中对象匹配错误,主要是FN,FP,ID Switch。MOTA给出了一个非常直观的衡量跟踪器在检测物体和保持轨迹时的性能,与物体位置的估计精度无关。MOTA取值应小于100,当跟踪器产生的错误超过了场景中的物体,MOTA会为负数。需要注意的是,此处的MOTA以及MOTP是计算所有帧的相关指标再进行平均(既加权平均值),而不是计算每帧的rate然后进行rate的平均。
注意MOTA中的FN,FP是检测的结果,而不是跟踪的结果,也就是说MOTA中只有IDs是和跟踪有关系的,剩下的都是检测。MOTA相比于IDF1要更偏向与检测。
MOTP
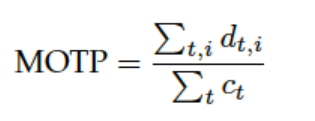
其中,d为检测目标i和给它分配的ground truth之间在所有帧中的平均度量距离,在这里是使用bounding box的overlap rate来进行度量(在这里MOTP是越大越好,但对于使用欧氏距离进行度量的就是MOTP越小越好,这主要取决于度量距离d的定义方式);而c为在当前帧匹配成功的数目。MOTP主要量化检测器的定位精度,几乎不包含与跟踪器实际性能相关的信息。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









