






文章目录
前言
光照因素一直是影响成像质量的一个关键因素,夜间等光照环境较差的条件下的图片往往细节丢失、分辨不清,信噪比低下。低照度图像增强是指通过一系列算法和技术,增强在低照度或弱光条件下拍摄的图像的可视化质量。本文主要介绍一些传统的低照度图像增强算法,给出具体的实现代码,便于测试各类图片的增强效果和比较各个算法的性能。
一、基于直方图的算法
1.1直方图均衡化的增强算法
该算法通过对图像的直方图进行均衡化,使图像的灰度分布更加均匀,从而增强图像的亮度和对比度。但是该算法容易出现过度增强和噪声增加的问题。
- 代码:直接使用
cv2.equalizeHist()函数实现
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread("250114358f54e0bd46e0d0590d031e1.png")
B,G,R = cv2.split(img) #get single 8-bits channel
b=cv2.equalizeHist(B)
g=cv2.equalizeHist(G)
r=cv2.equalizeHist(R)
equal_img=cv2.merge((b,g,r)) #merge it back
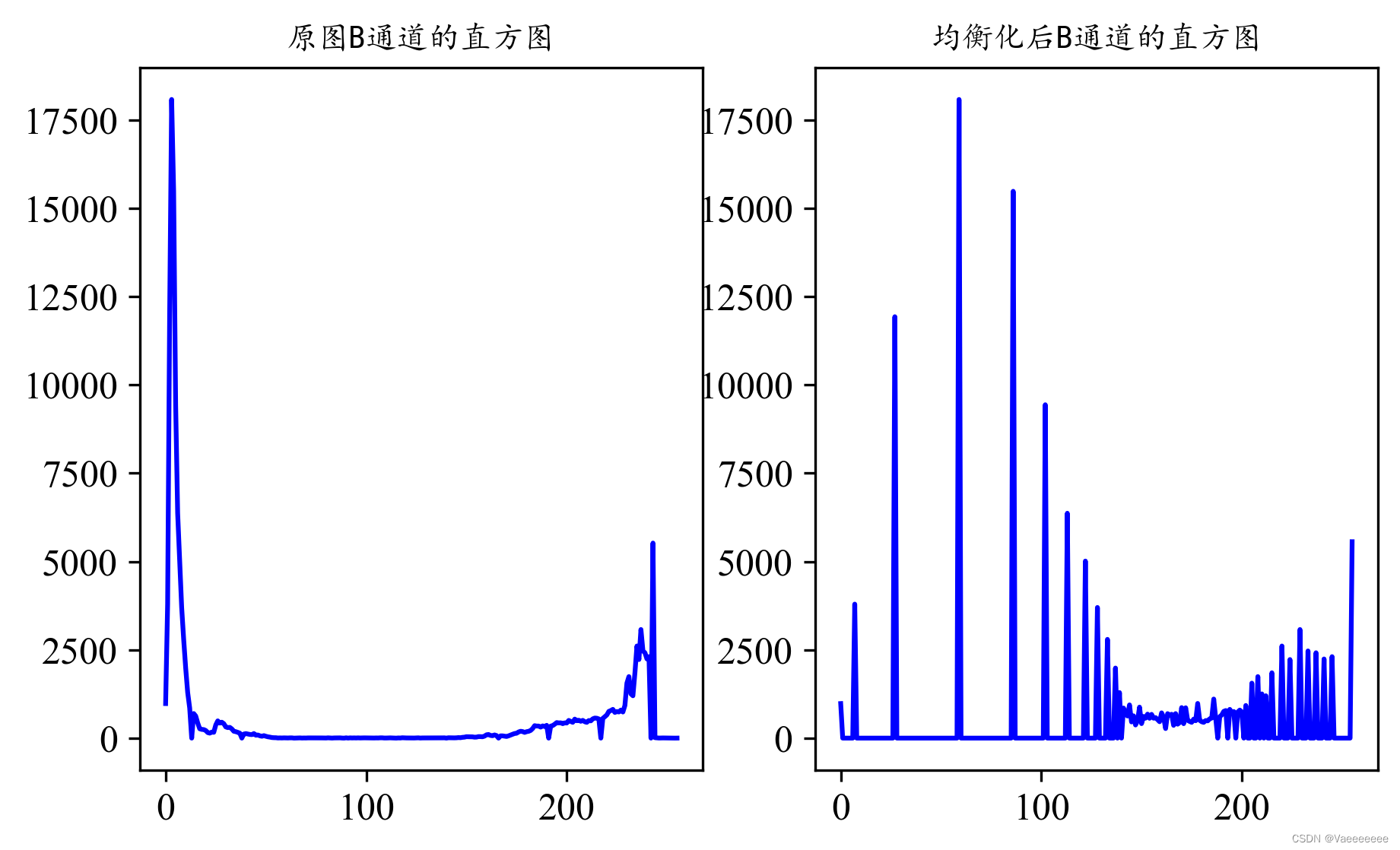
hist_b=cv2.calcHist([equal_img],[0],None,[256],[0,256])
hist_B=cv2.calcHist([img],[0],None,[256],[0,256])
plt.subplot(1,2,1)
plt.plot(hist_B,'b')
plt.title('原图B通道的直方图',fontdict={'family':'KaiTi', 'size':10})
plt.subplot(1,2,2)
plt.title('均衡化后B通道的直方图',fontdict={'family':'KaiTi', 'size':10})
plt.plot(hist_b,'b')
plt.show()
cv2.imshow("orj",img)
cv2.imshow("equal_img",equal_img)
cv2.waitKey(0)
-
增强效果
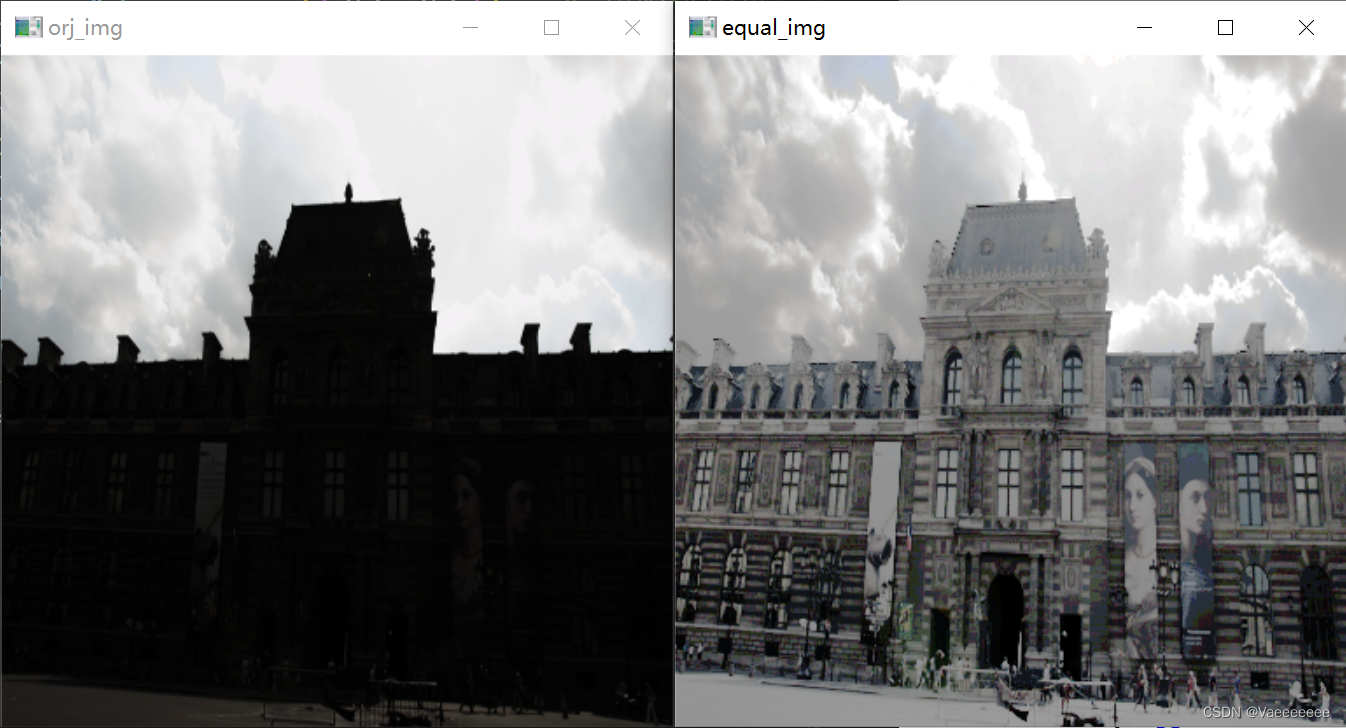
-
直方图变化
1.2直方图规定化的增强算法
该算法通过将低照度图像的直方图映射到高照度图像的直方图上,从而增强图像的亮度和对比度。但是该算法需要有高照度图像作为参考,且对图像的颜色信息敏感。
- 代码:(代码源自这篇文章:数字图像处理:直方图规定化的原理及Python实现)
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
img1 = np.array(Image.open('11.png')) # 读入原图像
img2 = np.array(Image.open('13.png')) # # 读入参考图像
plt.subplot(2,2,1)
plt.imshow(img1, cmap='gray')
plt.axis('off')
plt.title('原图像',fontdict={'family':'KaiTi', 'size':10})
plt.subplot(2,2,2)
plt.imshow(img2, cmap='gray')
plt.axis('off')
plt.title('参考图像',fontdict={'family':'KaiTi', 'size':10})
# 计算原图像和参考图像的直方图
hist1, bins1 = np.histogram(img1.flatten(), 256, [0,256])
hist2, bins2 = np.histogram(img2.flatten(), 256, [0,256])
# 将直方图归一化
hist1 = hist1 / float(np.sum(hist1))
hist2 = hist2 / float(np.sum(hist2))
# 计算原图像和参考图像的累积分布函数(CDF)
cdf1 = hist1.cumsum()
cdf2 = hist2.cumsum()
# 将CDF归一化
cdf1 = cdf1 / float(cdf1[-1])
cdf2 = cdf2 / float(cdf2[-1])
# 创建新的图像数组
img3 = np.zeros_like(img1)
# 计算灰度值映射
lut = np.interp(cdf1, cdf2, np.arange(0, 256))
# 针对每个像素应用灰度映射
for i in range(256):
img3[img1 == i] = lut[i]
# 显示规定化后的图像
plt.subplot(2,2,3)
plt.imshow(img3, cmap='gray')
plt.axis('off')
plt.title('规定化后的图像',fontdict={'family':'KaiTi', 'size':10})
plt.show()
- 效果:
在这里插入图片描述
二、基于图像变换的算法
- 图像变换方法有很多,比如利用小波变换、傅里叶变换等等。这里主要介绍使用伽马变换实现亮度增强。原理很简单,就是通过非线性变换对过暗的图像进行校正。
y o u t = y i n p u t γ y_{out} = y_{input} ^{\gamma} yout=yinputγ输入图像首先需要进行归一化将像素取值范围映射到0~1,因此 γ > 1 \gamma>1 γ>1,图像整体变暗; γ < 1 \gamma<1 γ<1,图像整体变亮。我们可以取一个合适的 γ \gamma γ 值,来实现一个较好的增强效果。
代码:
import numpy as np
import matplotlib.pyplot as plt
import cv2
img = cv2.imread('11.png')
img = img.astype(np.float32) / 255.0
def gamma_correction(img, gamma):
return np.power(img, gamma)
gamma = 0.5
img_gamma = gamma_correction(img, gamma)
plt.subplot(1,2,1)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.title('原图像',fontdict={'family':'KaiTi', 'size':10})
plt.subplot(1,2,2)
plt.imshow(cv2.cvtColor(img_gamma, cv2.COLOR_BGR2RGB))
plt.title('伽马变换后图像',fontdict={'family':'KaiTi', 'size':10})
plt.show()
- 增强效果:
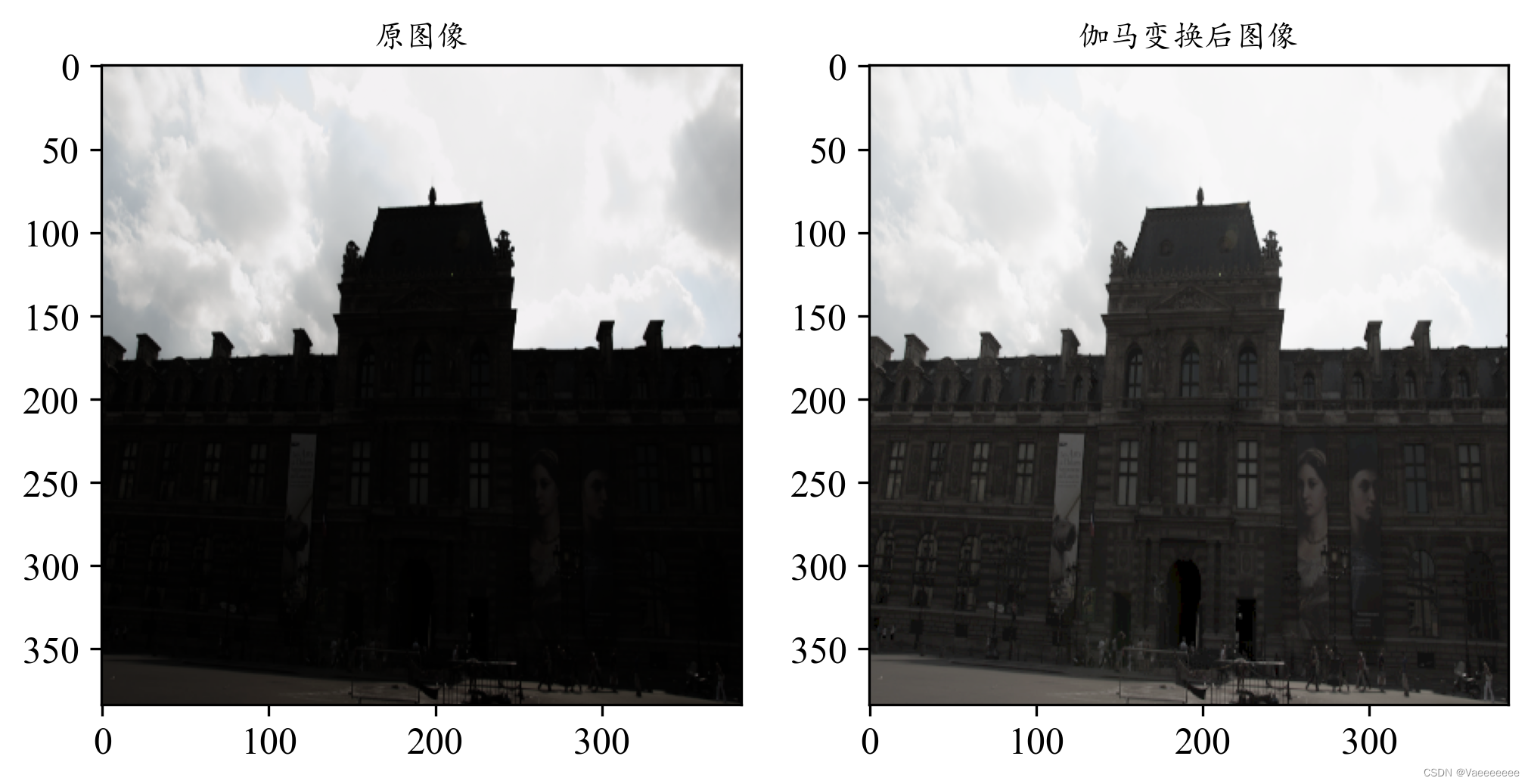
- γ \gamma γ不同的选择直接影响着增强效果,所以很容易想到使用自适应伽马变换的方法。
代码:
import cv2
import numpy as np
import matplotlib.pyplot as plt
def adaptive_gamma_correction(img, gamma=1.0, eps=1e-7):
img_float = img.astype(np.float32) / 255.0
img_max = np.max(img_float)
img_norm = img_float / img_max
img_log = np.log(img_norm + eps)
img_mean = np.exp(np.mean(img_log))
gamma_new = np.log(0.5) / np.log(img_mean)
gamma_corr = np.power(img_norm, gamma_new)
gamma_corr = np.uint8(gamma_corr * 255.0)
return gamma_corr
# 读取输入图片
img = cv2.imread('11.png')
# 进行自适应伽马校正
gamma_corr = adaptive_gamma_correction(img)
# 显示输入和输出图片
plt.subplot(121)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.title('原图像',fontdict={'family':'KaiTi', 'size':10})
plt.axis('off')
plt.subplot(122)
plt.imshow(gamma_corr, cmap='gray')
plt.title('自适应伽马变换后图像',fontdict={'family':'KaiTi', 'size':10})
plt.axis('off')
plt.show()
- 增强效果:

三、 基于Retinex理论的增强算法
该算法通过模拟人眼对光照变化的适应能力,将图像(
S
S
S)分解成反射分量(
R
R
R)和光照分量(
I
I
I),原理就是将
I
I
I去除,保留反映物体本质的量
R
R
R。
S
(
x
,
y
)
=
R
(
x
,
y
)
∗
I
(
x
,
y
)
S(x,y)=R(x,y)*I(x,y)
S(x,y)=R(x,y)∗I(x,y)
两边做对数变换:
l
o
g
(
R
(
x
,
y
)
)
=
l
o
g
(
S
(
x
,
y
)
)
−
l
o
g
(
I
(
x
,
y
)
)
\\两边做对数变换:log(R(x,y))=log(S(x,y))-log(I(x,y))
两边做对数变换:log(R(x,y))=log(S(x,y))−log(I(x,y))
S
S
S 是输入的低照度图像,
R
R
R 是待输出的增强后图像。因此,该算法的关键就是如何得到这里的光照量
I
I
I,而
R
e
t
i
n
e
x
Retinex
Retinex 理论的提出者认为
S
S
S经过高斯滤波后就可以得到
I
I
I,即对图像作模糊或平滑处理。
- 算法流程图:

3.1 单尺度Retinex算法 (SSR算法)
import cv2
import torch
from torchvision import datasets,transforms
import numpy as np
from PIL import Image, ImageFilter
# S = I * R
# S:输入图片
# I:光照量;需要对图像进行高斯模糊得到
# R:增强后图片
torch.set_default_tensor_type('torch.cuda.FloatTensor')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.ToTensor()
GaussianBlur = transforms.GaussianBlur(3,sigma=(0.1,0.1)) #高斯模糊
to_pil = transforms.ToPILImage() #将Tensor转换成PIL格式
img_path = 'F:\Picture\低照度图片'
out_path = 'F:\SCI-main\传统增强算法\测试结果\SSR测试结果/'
img = datasets.ImageFolder(img_path,transform = transform)
def SSR(image):
img_S = image.cuda()
ln_S = torch.log((img_S + 0.001) / 255.0)
img_I = GaussianBlur(img_S)
ln_I = torch.log((img_I + 0.001) / 255.0)
ln_R = ln_S - ln_I * ln_S # 这里ln_S起到调节作用,不加的话效果很差
R = cv2.normalize(ln_R.cpu().numpy(), None, 0, 1, cv2.NORM_MINMAX)
final_image = to_pil(torch.tensor(R))
return final_image
for i in range(len(img.imgs)):
image = SSR(img[i][0])
image.save(out_path + str(i) + '.png')
几个注意点:
- ImageFolder使用方法:我们需要将所有图像按照文件夹保存,例如所有猫的图像放入到cat文件夹中,所有狗的图像放入到dog文件夹中,该函数就会自动识别类别,将图像所在的目录名称作为label。因此这里的输入图片路径结构如下:
- 在得到 l n R lnR lnR 时,注意直接使用 l n S − l n I lnS-lnI lnS−lnI得到的效果并不好,而是要在 l n I lnI lnI前面乘上一个系数,一般取 l n S lnS lnS ,或者乘上一个小于1的常数。
- 得到 l n R lnR lnR 后,并没有对其取指数,而是作归一化处理作为最终结果,否则效果也不好。😆
增强效果:(失真有些过重)



3.2 多尺度Retinex算法(MSR算法)
- 在SSR的基础上,对原图像进行3次SSR,然后对结果取平均作为最终增强图像。
代码:
import cv2
import torch
from torchvision import datasets,transforms
import numpy as np
from PIL import Image, ImageFilter
# S = I * R
# S:输入图片
# I:光照量;需要对图像进行高斯模糊得到
# R:增强后图片
torch.set_default_tensor_type('torch.cuda.FloatTensor')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.ToTensor()
GaussianBlur1 = transforms.GaussianBlur(3,sigma=(15,15)) #高斯模糊
GaussianBlur2 = transforms.GaussianBlur(3,sigma=(80,80)) #高斯模糊
GaussianBlur3 = transforms.GaussianBlur(3,sigma=(200,200)) #高斯模糊
to_pil = transforms.ToPILImage() #将Tensor转换成PIL格式
img_path = 'F:\Picture\低照度图片'
out_path = 'F:\SCI-main\传统增强算法\测试结果\MSR测试结果/'
img = datasets.ImageFolder(img_path,transform = transform)
def SSR(image,GaussianBlur):
img_S = image.cuda()
ln_S = torch.log((img_S + 0.001) / 255.0)
img_I = GaussianBlur(img_S)
ln_I = torch.log((img_I + 0.001) / 255.0)
ln_R = ln_S - ln_I * ln_S # 这里ln_S起到调节作用,不加的话效果很差
R = cv2.normalize(ln_R.cpu().numpy(), None, 0, 1, cv2.NORM_MINMAX)
return R
def MSR(image):
img1 = SSR(image,GaussianBlur1)
img2 = SSR(image,GaussianBlur2)
img3 = SSR(image,GaussianBlur3)
img = (img1 + img2 + img3) / 3
final_image = to_pil(torch.tensor(img))
return final_image
for i in range(len(img.imgs)):
image = MSR(img[i][0])
image.save(out_path + str(i) + '.png')
- 增强结果:

3.3 MSRCR算法(Multi-Scale Retinex with Color Restoration)
- 一种带色彩恢复因子的 M S R MSR MSR 算法,将颜色修正因子引入到 M S R MSR MSR 算法,可以调节 M S R MSR MSR 算法中由于噪声等因素导致色彩严重失真的缺陷,使得颜色可以保持地更好。
- 使用数学表达式表示为:
R M S R C R j ( x , y ) = C j ( x , y ) R M S R j ( x , y ) C j ( x , y ) = α log [ λ S j ( x , y ) / ∑ j = 1 3 S j ( x , y ) ] R_{MSRCR_{j}}(x,y) = C_{j}(x,y)R_{MSR_{j}}(x,y)\\C_j\big(x,y\big)=\alpha\log\bigg[\lambda S_j\big(x,y\big)/\sum\limits_{j=1}^3S_j\big(x,y\big)\bigg] RMSRCRj(x,y)=Cj(x,y)RMSRj(x,y)Cj(x,y)=αlog[λSj(x,y)/j=1∑3Sj(x,y)] R M S R j ( x , y ) R_{MSR_{j}}(x,y) RMSRj(x,y):MSR算法处理后的图像第 j j j个色彩分量,j=1,2,3,对应R、G、B;
C j ( x , y ) C_j\big(x,y\big) Cj(x,y):代表第 j j j 个色彩分量的颜色恢复系数;
α 、 λ \alpha、\lambda α、λ:常数;
S j ( x , y ) S_j\big(x,y\big) Sj(x,y):表示低照度图像的第 j j j 个颜色分量。
代码:在前面的代码基础上,将输出R乘上系数即可。
import cv2
import torch
from torchvision import datasets,transforms
import numpy as np
from PIL import Image, ImageFilter
# S = I * R
# S:输入图片
# I:光照量;需要对图像进行高斯模糊得到
# R:增强后图片
torch.set_default_tensor_type('torch.cuda.FloatTensor')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.ToTensor()
GaussianBlur1 = transforms.GaussianBlur(3,sigma=(15,15)) #高斯模糊
GaussianBlur2 = transforms.GaussianBlur(3,sigma=(80,80)) #高斯模糊
GaussianBlur3 = transforms.GaussianBlur(3,sigma=(200,200)) #高斯模糊
to_pil = transforms.ToPILImage() #将Tensor转换成PIL格式
img_path = 'F:\Picture\低照度图片'
out_path = 'F:\SCI-main\传统增强算法\测试结果\MSRCR测试结果/'
img = datasets.ImageFolder(img_path,transform = transform)
def SSR(image,GaussianBlur):
img_S = image.cuda()
ln_S = torch.log((img_S + 0.001) / 255.0)
img_I = GaussianBlur(img_S)
ln_I = torch.log((img_I + 0.001) / 255.0)
ln_R = ln_S - ln_I * ln_S # 这里ln_S起到调节作用,不加的话效果很差
R = cv2.normalize(ln_R.cpu().numpy(), None, 0, 1, cv2.NORM_MINMAX)
return R
def MSR(image):
img1 = SSR(image,GaussianBlur1)
img2 = SSR(image,GaussianBlur2)
img3 = SSR(image,GaussianBlur3)
img = (img1 + img2 + img3) / 3
# final_image = to_pil(torch.tensor(img))
# return final_image
return torch.tensor(img)
def MSRCR(image,alpha = 0.225,lambd = 0.2):
img = MSR(image)
image_sum = torch.sum(image.cuda())
for i in range(3):
img[i,:,:] = alpha * torch.log10((lambd * image[i,:,:].cuda())/image_sum) * img[i,:,:]
final_image = to_pil(torch.tensor(img))
return final_image
for i in range(len(img.imgs)):
image = MSRCR(img[i][0])
image.save(out_path + str(i) + '.png')
- 增强效果:这里效果其实并不是很好,而有些图片偏色现象很严重。主要原因猜测是因为这里的两个常数
α
、
β
\alpha 、\beta
α、β 取值的问题(也有可能是代码的问题😆),虽然我试了各种数字,但是也一直没有得到很好的增强效果。
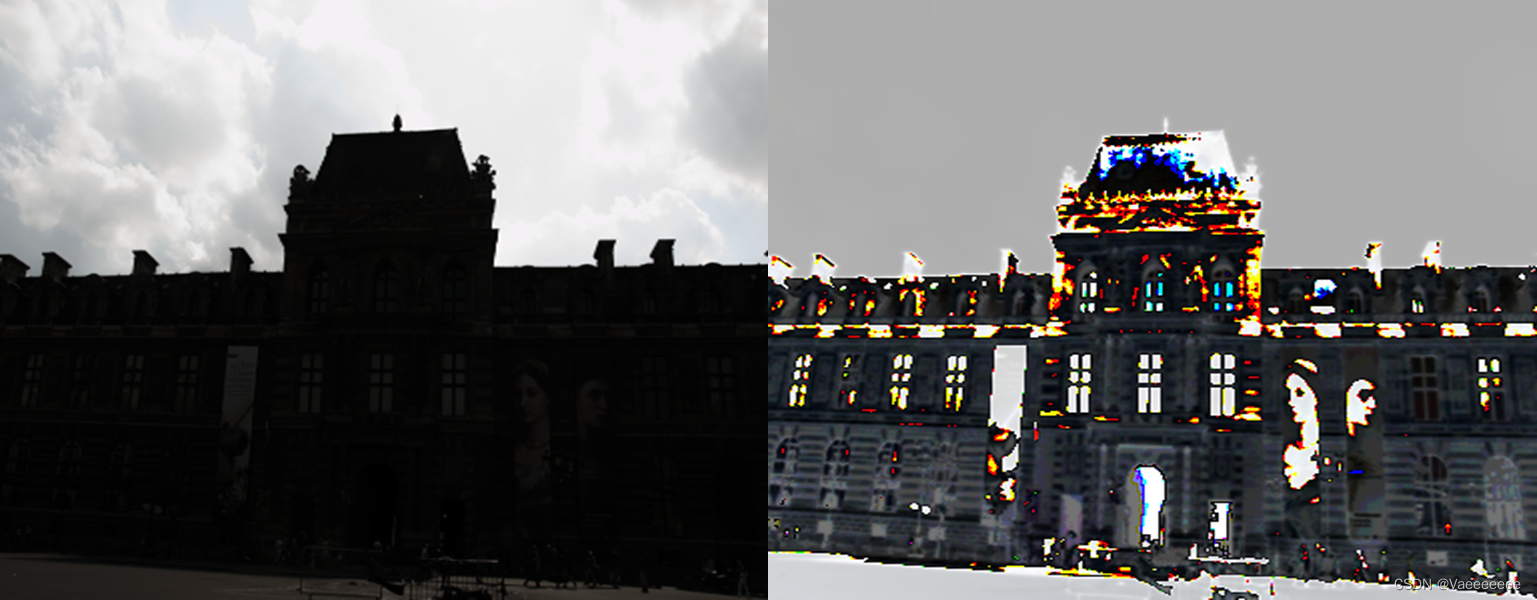
总结
- 以上几种经典的低照度图像增强算法,各自具有不同的优缺点,在实际应用中需要综合考虑图像的特点以及对图像质量的要求。同时需要注意的是,这些算法都是在同一场景下进行处理,如果场景发生了变化,也需要进行相应的算法调整。
- 存在问题和不足之处,欢迎大家一起交流!📖














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









