







9.JUC
Semaphore
为什么需要用到Semaphore?
限流
Sdmaphore的场景?
秒杀商品的时候,不能够让那些没有秒杀成功的线程进入,只有占了坑位的才可以使用,这里可以用redis来记录这个Semaphre
Semaphore的原理?
AQS+state进行分析
定义
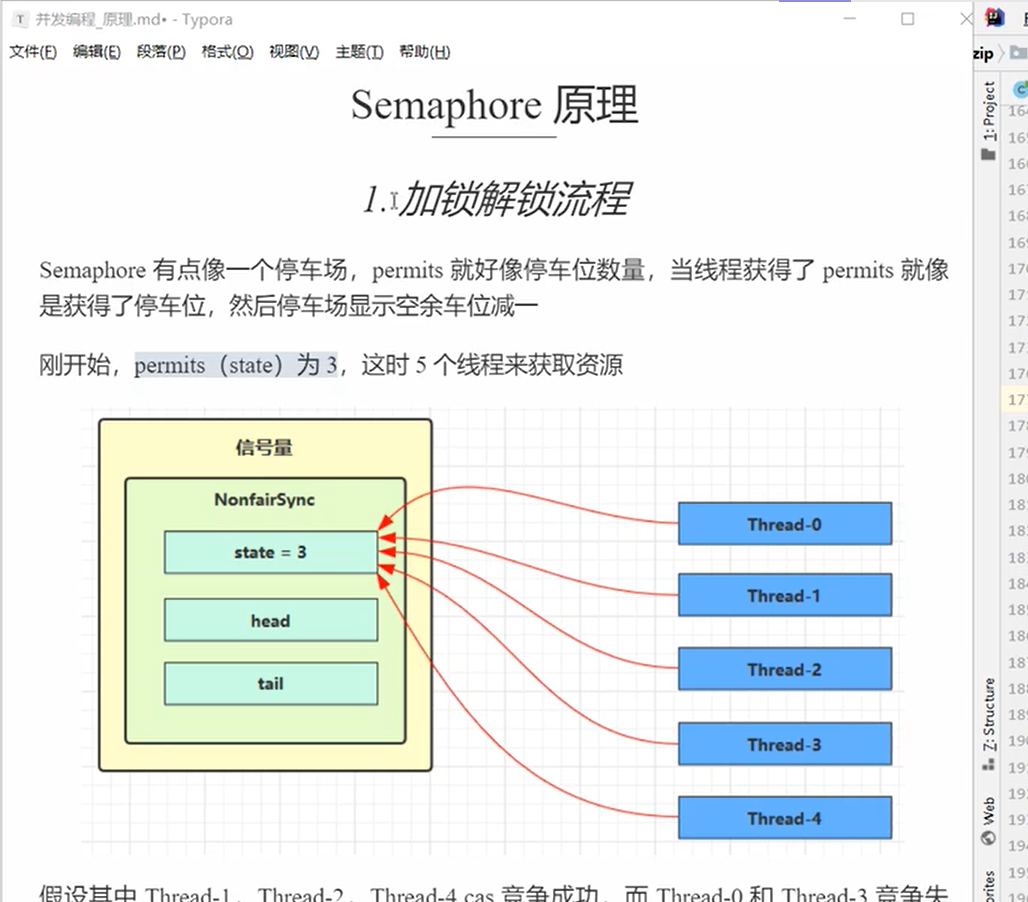
信号量,相当于就是停车位限制流量。
- acquire:拿到位置
- release:释放位置
@Slf4j(topic = "c.test")
public class MyTestSemaphore {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3);
for(int i=0;i<10;i++){
new Thread(()->{
try {
semaphore.acquire();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("running");
Sleeper.sleep(1);
log.debug("end");
semaphore.release();
}).start();
}
}
}
原理
其实都是AQS的原理
acquire
- acquire调用了sync(nonfairSync)的acquireSharedInterruptibly(1);尝试上锁tryAcquireShared(arg)
- 调用nonfairTryAcquireShared(int acquires),每次都是-1,直到信号量小于1的时候(相当于就是AQS的state==0的时候)直接返回这个remaining。
- 如果得到返回值是<0,那么就把对应线程送进阻塞队列。基本和lock操作一样。
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
static final class NonfairSync extends Sync {
private static final long serialVersionUID = -2694183684443567898L;
NonfairSync(int permits) {
super(permits);
}
//尝试获取锁
protected int tryAcquireShared(int acquires) {
return nonfairTryAcquireShared(acquires);
}
}
//非公平获取锁
final int nonfairTryAcquireShared(int acquires) {
for (;;) {
int available = getState();
int remaining = available - acquires;//直接就是-1
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
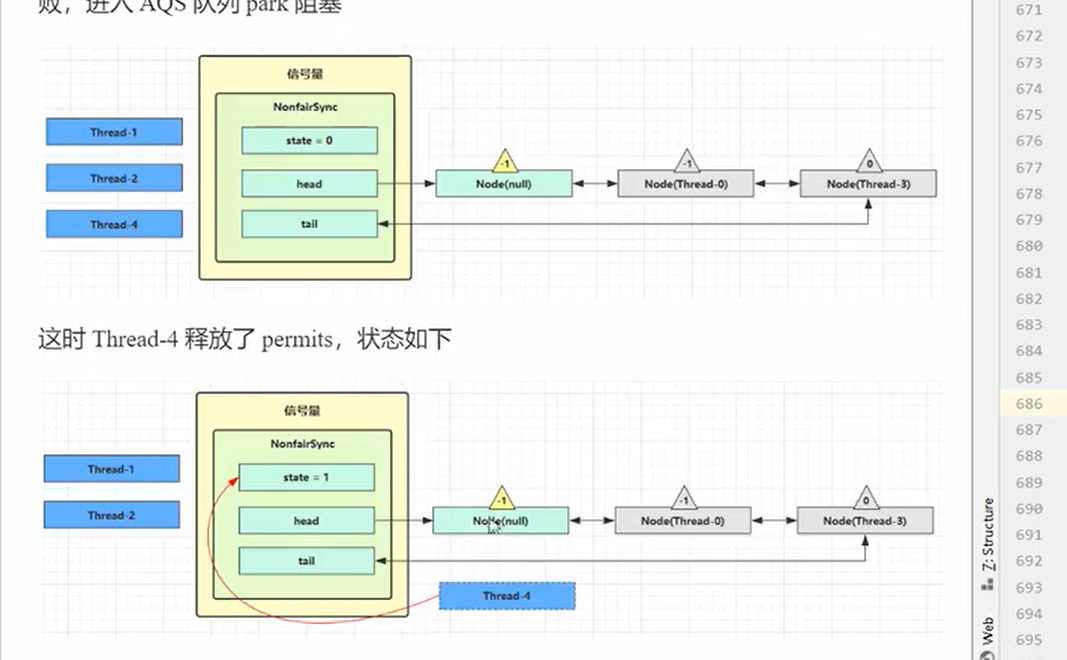
release
- release->调用releaseShare(包括了tryReleaseShared和doReleaseShared)
- 处理逻辑相似,但是tryReleaseShared是把state+1而不是-1,原因就是信号量的state的意思是有多少坑位可以使用,也就是只要有坑位,那么线程就能获取锁。(代码非常简洁)
protected final boolean tryReleaseShared(int releases) {
for (;;) {
int current = getState();
int next = current + releases;//坑位+1《释放了一个
if (next < current) // overflow
throw new Error("Maximum permit count exceeded");
if (compareAndSetState(current, next))
return true;
}
}
总结:acquire调用acquireSharedInterruptibly(可被中断)。然后就是模板tryAcquireShare和doAcquireSharedInterruptibly(和doAcquire差不多的逻辑,但是多了一个唤醒共享setHeadAndProgation)锁的方法(读锁)。
CountDownLatch
为什么需要用到CountDownLatch?
应用场景:一个线程需要等待多个线程结果的时候。或者需要等待其它线程运行完之后
定义
他就是一个倒计时锁,await之后需要等待countDown到0的时候才会解锁。
@Slf4j(topic = "c.test")
public class TestCountDownLock {
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(3);
new Thread(()->{
log.debug("begin1");
Sleeper.sleep(1);
log.debug("end2");
countDownLatch.countDown();
},"t1").start();
new Thread(()->{
log.debug("begin2");
Sleeper.sleep(1);
log.debug("end2");
countDownLatch.countDown();
},"t2").start();
new Thread(()->{
log.debug("begin3");
Sleeper.sleep(2);
log.debug("end3");
countDownLatch.countDown();
},"t3").start();
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("结束");
}
}
join同样可以完成功能,但是万一线程阻塞了,那么就会导致最后的join一直处于等待,需要进行特殊的处理。但是CountDownLatch能够进行倒计时,只要倒计时结束,那么就会结束主线程的阻塞
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(4);
CountDownLatch countDownLatch=new CountDownLatch(3);
service.submit(()->{
log.debug("begin1");
Sleeper.sleep(1);
log.debug("end1");
countDownLatch.countDown();
},"t1");
service.submit(()->{
log.debug("begin2");
Sleeper.sleep(1);
log.debug("end2");
countDownLatch.countDown();
},"t2");
service.submit(()->{
log.debug("begin3");
Sleeper.sleep(1);
log.debug("end3");
countDownLatch.countDown();
},"t3");
service.submit(()->{
log.debug("await");
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("解锁");
},"t4");
}
游戏案例
为什么加载的时候需要使用到countDownLock?
原因就是多方面,多文件需要加载,需要全部文件和配置初始化之后才能够进行开始,所以可以使用CountDown来记录最终需要等待的文件以及线程数。在谷粒商城的获取商品信息、快递信息的时候都会用到这种方式来提高访问的速度,并发执行,并且通过countDown来记录要执行完任务的个数才能够继续往下面执行。也可以使用join或者是future的getAll来进行阻塞。
public static void test6(){
String[] a=new String[10];
Random random = new Random();
ExecutorService service = Executors.newFixedThreadPool(10);
CountDownLatch countDownLatch=new CountDownLatch(10);
for(int j=0;j<10;j++){
int k=j;
service.submit(()->{
for(int i=0;i<=100;i++){
try {
Thread.sleep(random.nextInt(100));
} catch (InterruptedException e) {
e.printStackTrace();
}
a[k]=i+"%";
System.out.print("\r"+Arrays.toString(a));
}
countDownLatch.countDown();
},"t"+j);
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
log.debug("游戏开始");
}
商品问题如果并发执行完且获取结果再继续执行?
还是需要future的get处理。没有结果通常使用countdownlatch
那么CountDownLatch有什么问题?
问题就是它不能够重置countdown的数量,也就是多次循环的话每次都要new一个,而不能够重用对象。
解决办法就是CyclicBarrier,能够重用,而且可以执行最终的方法。
线程数有什么要求?
必须和循环任务数相同,不然就会多个任务被线程开启。假设3线程,3次循环,两个任务,那么就会取出第一次,第二次任务执行,还会取出循环的下一次任务执行。因为线程多。
@Slf4j(topic = "c.test")
public class TestCycleBarrier1 {
public static void main(String[] args) {
CyclicBarrier cyclicBarrier = new CyclicBarrier(2,()->{
log.debug("结束");
});
ExecutorService service = Executors.newFixedThreadPool(2);
for(int i=0;i<3;i++){
service.submit(()->{
log.debug("开始....");
Sleeper.sleep(1);
try {
cyclicBarrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},"t1") 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









