




 本文深入探讨了链表的三种主要类型:单链表、循环链表和双向链表,分析了它们的特性、优缺点以及在插入、删除操作上的效率差异。链表作为一种非连续存储结构,提供了灵活的数据组织方式,但在访问速度上相对较慢。相对于数组,链表在内存管理上有更大的灵活性,但可能带来额外的空间开销和较低的CPU缓存利用率。在实际应用中,应根据具体需求权衡选择数组或链表。
本文深入探讨了链表的三种主要类型:单链表、循环链表和双向链表,分析了它们的特性、优缺点以及在插入、删除操作上的效率差异。链表作为一种非连续存储结构,提供了灵活的数据组织方式,但在访问速度上相对较慢。相对于数组,链表在内存管理上有更大的灵活性,但可能带来额外的空间开销和较低的CPU缓存利用率。在实际应用中,应根据具体需求权衡选择数组或链表。
目录
本文是王争老师的《算法与数据结构之美》的学习笔记,详细内容请看王争的专栏 。
链表概念
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
指针:存储所指对象的内存地址。
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针,或者反过来说,指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
常见的链表分类
单链表
链表通过指针将一组零散的内存块串联在一起。其中链表的结点指的就是是内存块。
链表要将所有的结点串起来,所以结点要存储数据和下一个结点地址的指针(后继结点next)。
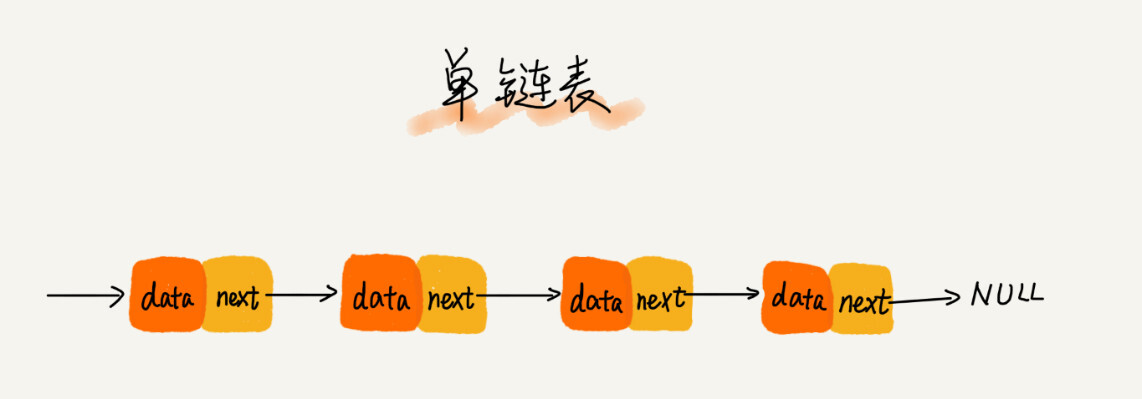
其中,第一个结点叫作头结点,其用来记录链表的基地址;
最后一个结点叫作尾结点,其指向一个空地址 NULL。
在链表中插入或者删除一个数据,并不像数组一样需要为了保持内存的连续性而搬移结点,因为链表的存储空间本身就不是连续的。所以只需要考虑相邻结点的指针改变,所以对应的时间复杂度是 O(1)。
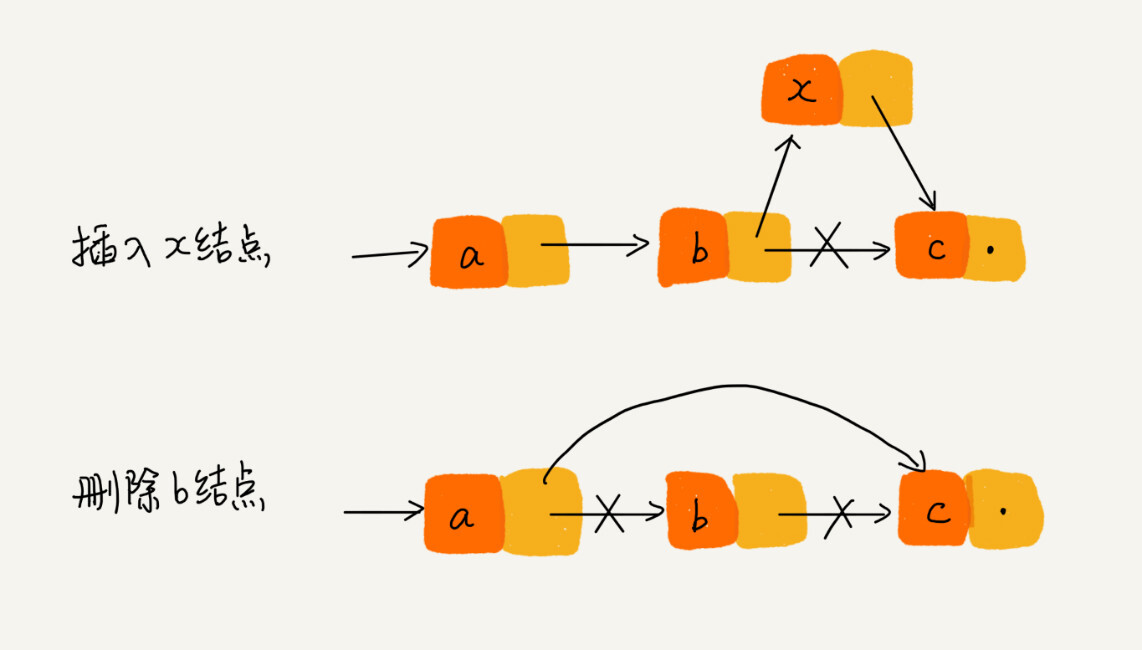
弊端:无法像数组那样,根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,而是需要根据指针一个结点一个结点地依次遍历,直到找到相应的结点。
循环链表
与单链表不同的是循环链表的尾结点指针是指向链表的头结点
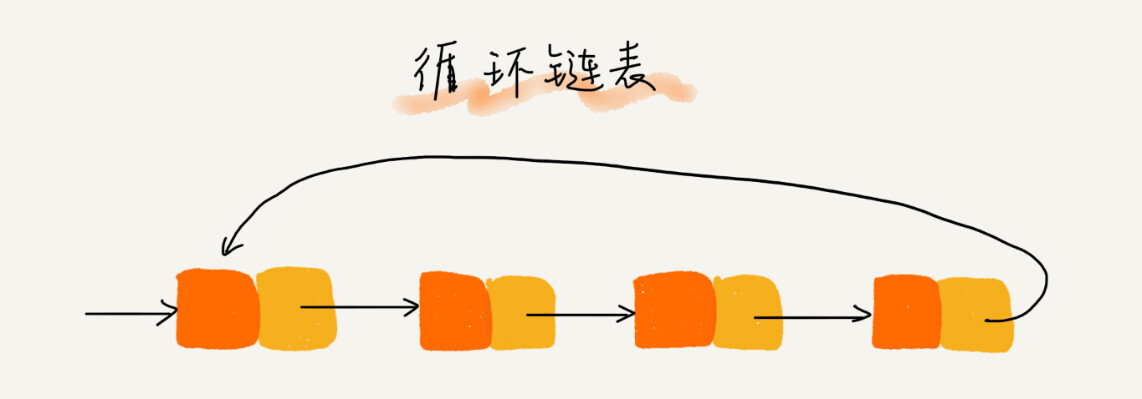
优点
从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表
双向链表
与单链表不同的是支持两个方向,每个结点不止有一个后继指针 next 指向后面的结点,还有一个前驱指针 prev 指向前面的结点。
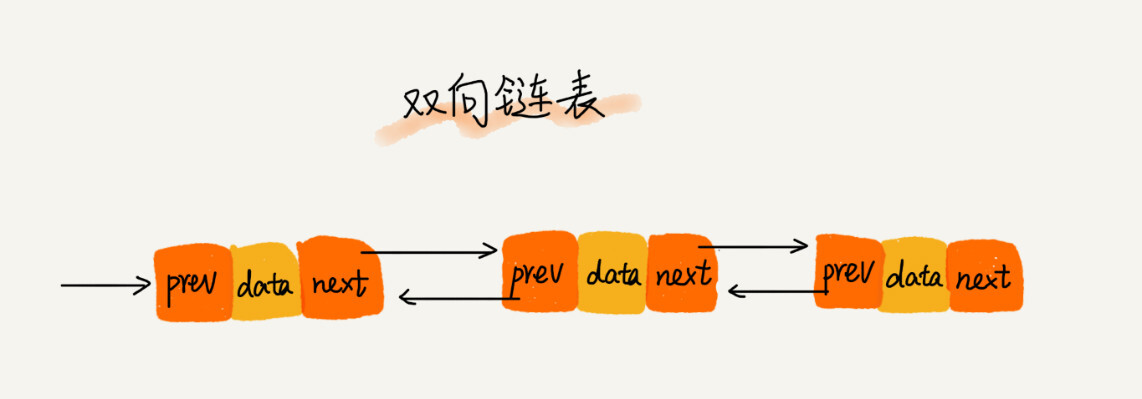
如图所示,弊端双向链表需要额外的两个空间来存储后继结点和前驱结点的地址;
优点但双向链表可以支持 O(1) 时间复杂度的情况下找到前驱结点,正是这样的特点,也使双向链表在某些情况下的插入、删除等操作都要比单链表简单、高效。
双向链表 vs 单链表
1.删除操作
在链表的删除操作有两种情况
-
删除结点中“值等于某个给定值”的结点;
-
删除给定指针指向的结点。
第一种情况,不管是单链表还是双向链表,为了查找到值等于给定值的结点,都需要从头结点开始一个一个依次遍历对比,直到找到值等于给定值的结点,然后再对指针操作将其删除。
尽管单纯的删除操作时间复杂度是 O(1),但遍历查找的时间是主要的耗时点,所以这种情况对应的链表操作的总时间复杂度为 O(n)。
第二种情况,已经找到了要删除的结点,但是删除某个结点 q 需要知道其前驱结点,而单链表并不支持直接获取前驱结点,所以,为了找到前驱结点,还是要从头结点开始遍历链表,直到 p->next=q,说明 p 是 q 的前驱结点。
但是对于双向链表来说,这种情况就比较有优势了。因为双向链表中的结点已经保存了前驱结点的指针,不需要像单链表那样遍历。所以,针对第二种情况,单链表删除操作需要 O(n) 的时间复杂度,而双向链表只需要在 O(1) 的时间复杂度内就搞定了!
2.插入操作
对于一个有序链表,双向链表的按值查询的效率也要比单链表高一些。因为,可以记录上次查找的位置 p,每次查询时,根据要查找的值与 p 的大小关系,决定是往前还是往后查找,所以平均只需要查找一半的数据。
总结
对于执行较慢的程序,可以通过消耗更多的内存(空间换时间)来进行优化;(双向链表)
而消耗过多内存的程序,可以通过消耗更多的时间(时间换空间)来降低内存的消耗。(单链表)
链表 VS 数组
1.底层的存储结构分析
数组需要一块连续的内存空间来存储,对内存的要求比较高,在内存不足时,可能会请求内存失败。
而链表恰恰相反,它并不需要一块连续的内存空间,它通过“指针”将一组零散的内存块串联起来使用。
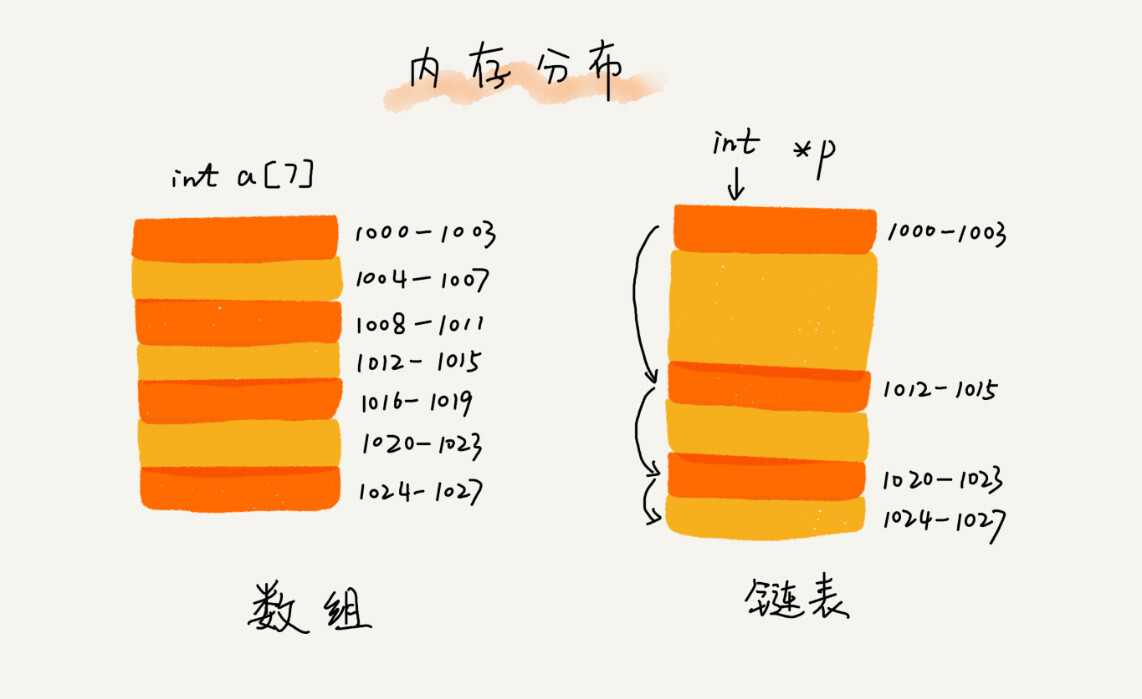
2.性能方面
它们插入、删除、随机访问操作的时间复杂度正好相反。
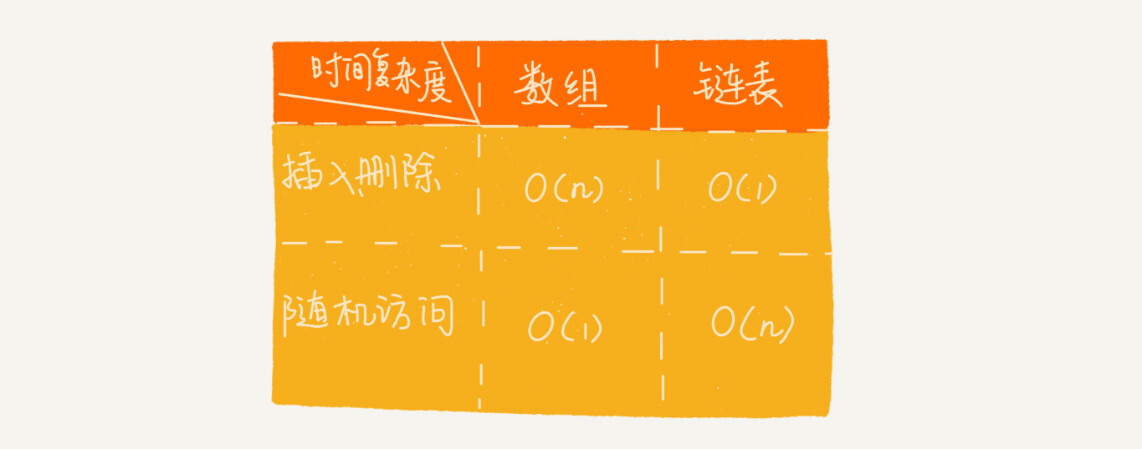
不过,数组和链表的对比,并不能局限于时间复杂度。
数组简单易用,在实现上使用的是连续的内存空间,可以借助 CPU 的缓存机制,预读数组中的数据,所以访问效率更高。而链表在内存中并不是连续存储,所以对 CPU 缓存不友好,没办法有效预读。
除此,链表中的每个结点都需要消耗额外的存储空间去存储一份指向下一个结点的指针,所以内存消耗会翻倍。而且,对链表进行频繁的插入、删除操作,还会导致频繁的内存申请和释放,容易造成内存碎片。
总之,针对不同类型的项目,要根据具体情况,权衡究竟是选择数组还是链表。

















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









