






0.浅谈算法
(1)算法定义
- 算法(algorithm)是在有限时间内解决特定问题的一组指令或操作步骤,它具有以下特性。
- 1.问题是明确的,包含清晰的输入和输出定义。
- 2.具有可行性,能够在有限步骤、时间和内存空间下完成。
- 3.各步骤都有确定的含义,在相同的输入和运行条件下,输出始终相同。
(2)生活中常见的算法
例一:查字典
- 铺垫:在字典里,每个汉字都对应一个拼音,而字典是按照拼音字母顺序排列的。假设我们需要查找一个拼音首字母为 r 的字,通常会按照如图所示的方式实现。

- 具体做法:
- 1.翻开字典大约一半的页数,查看该页的首字母是什么,假设首字母为m。
- 2.因为字母表中,r位于m后面,所以排除字典前半部分,查找范围缩小到后半部分。
- 3.不断重复步骤1和步骤2的过程,直到找到字母为r的页码为止。
- 总结:查字典这个小学生必备技能,实际上就是著名的“二分查找”算法。从数据结构的角度,我们可以把字典视为一个已排序的“数组”;从算法的角度,我们可以将上述查字典的一系列操作看作“二分查找”。
例二:整理扑克
- 铺垫:我们在打牌时,每局都需要整理手中的扑克牌,使其从小到大排列。如图所示:

- 具体做法:
- 1.先摸上来第一张牌,此时无需做任何比较,直接放入。
- 2.继续摸第二张牌,从第二张牌开始往前比。
- 3.如果第二张牌比第一张牌小,则需要交换他们的位置。
- 4.再让第三张牌和前两张牌依次比较(从第二张牌开始对比),如果第三张牌比其中任何一张牌都要小,则同样需要交换位置。
- 5.以此类推,往后的每张牌都这样去比较然后进行排序。
- 总结:整理扑克牌的过程本质上是“插入排序”算法,它在处理小型数据集时非常高效。许多编程语言的排序库函数中都有插入排序的身影。
例三:找零钱
-
铺垫:假设我们在超市购买了 69 元的商品,给了收银员 100 元,则收银员需要找我们 31 元。现在收银台只有面额是1 元、5 元、10 元、20 元这四种,如何尽可能用大面额的货币去完成零钱兑换呢?
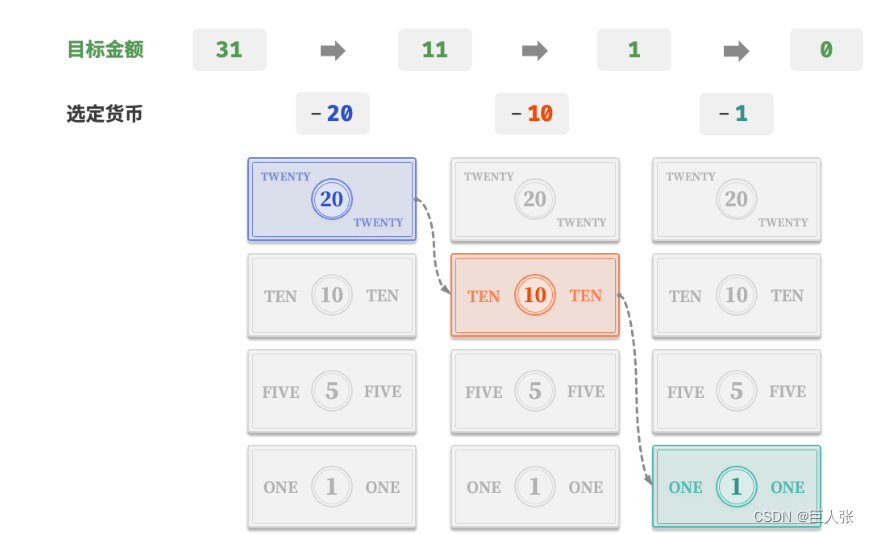
-
具体做法:
- 从可选项中拿出最大的 20 元,剩余 11 元。
- 从剩余可选项中拿出最大的 10 元,剩余 1 元。
- 从剩余可选项中拿出最大的 1 元,剩余 0 元。
- 完成找零,方案为 1+10+20 = 31 元。
- 总结:在以上步骤中,我们每一步都采取当前看来最好的选择(尽可能用大面额的货币),最终得到了可行的找零方案。从数据结构与算法的角度看,这种方法本质上是“贪心”算法。
(3)数据结构
数据结构(data structure)是组织和存储数据的方式,涵盖数据内容、数据之间关系和数据操作方法,它具有以下设计目标。
- 空间占用尽量少,以节省计算机内存。
- 数据操作尽可能快速,涵盖数据访问、添加、删除、更新等。
- 提供简洁的数据表示和逻辑信息,以便算法高效运行。
Python 中提供了多种内置的数据结构,这些数据结构根据存储的数据类型和访问方式的不同而有所区别。以下是一些主要的 Python 数据结构:
- 列表(List)
- 元组(Tuple)
- 集合(Set)
- 字典(Dictionary)
- 字符串(String)
- 其他数据结构:除了上述内置的数据结构外,Python 还支持其他更复杂的数据结构,如栈(Stack)、队列(Queue)、树(Tree)、图(Graph)等。
(4)数据结构与算法的关系
数据结构与算法高度相关、紧密结合,具体表现在以下三个方面。
- 数据结构是算法的基石。数据结构为算法提供了结构化存储的数据,以及操作数据的方法。
- 算法是数据结构发挥作用的舞台。数据结构本身仅存储数据信息,结合算法才能解决特定问题。
- 算法通常可以基于不同的数据结构实现,但执行效率可能相差很大,选择合适的数据结构是关键。
(5)算法复杂度
<1> 时间复杂度
- 定义:用来估计算法运行时间的一个式子。
- 一般来讲,时间复杂度高的算法比复杂度低的算法慢。
- 设输入数据大小为 n ,常见的时间复杂度类型如图所示(按照从低到高的顺序排列):

- 常数阶 O(1)
- 常数阶的操作数量与输入数据大小 n 无关,即不随着 n 的变化而变化。在以下函数中,尽管操作数量 size 可能很大,但由于其与输入数据大小 n 无关,因此时间复杂度仍为 O(1) .
def constant(n):
"""常数阶"""
count = 0
size = 100000
for _ in range(size):
count += 1
return count
- 线性阶 O(n)
- 线性阶的操作数量相对于输入数据大小 n 以线性级别增长。线性阶通常出现在单层循环中,例如遍历数组的时间复杂度为 O(n) ,其中 n 为数组或链表的长度:
def array_traversal(nums)
"""线性阶(遍历数组)"""
count = 0
# 循环次数与数组长度成正比
for num in nums:
count += 1
return count
- 平方阶 O(n2)
- 平方阶的操作数量相对于输入数据大小 n 以平方级别增长。平方阶通常出现在嵌套循环中,外层循环和内层循环的时间复杂度都为 O(n) ,因此总体的时间复杂度为 O(n22).
def quadratic(n)
"""平方阶"""
count = 0
# 循环次数与数据大小 n 成平方关系
for i in range(n):
for j in range(n):
count += 1
return count
- 指数阶 O(2n)
- 生物学的“细胞分裂”是指数阶增长的典型例子:初始状态为 1 个细胞,分裂一轮后变为 2 个,分裂两轮后变为 4 个,以此类推,分裂 n 轮后有 2n 个细胞。
def exponential(n)
"""指数阶(循环实现)"""
count = 0
base = 1
# 细胞每轮一分为二,形成数列 1, 2, 4, 8, ..., 2^(n-1)
for _ in range(n):
for _ in range(base):
count += 1
base *= 2
# count = 1 + 2 + 4 + 8 + .. + 2^(n-1) = 2^n - 1
return count
- 对数阶 O(logn)
与指数阶相反,对数阶反映了“每轮缩减到一半”的情况。设输入数据大小为 n ,由于每轮缩减到一半,因此循环次数是 O( log 2 n \log_2n log2n) ,简记为 O(logn),典型的例子就是二分查找。
def logarithmic(n):
"""对数阶(循环实现)"""
count = 0
while n > 1:
n = n / 2
count += 1
return count
- 线性对数阶 O(n*logn)
线性对数阶常出现于嵌套循环中,两层循环的时间复杂度分别为 O(logn) 和 O(n) , 因此时间复杂度为 O(n*logn)。例如:
def linear_log_recur(n):
"""线性对数阶"""
if n <= 1:
return 1
count = linear_log_recur(n // 2) + linear_log_recur(n // 2)
for _ in range(n):
count += 1
return count
主流排序算法的时间复杂度通常为 O(n*logn)
,例如快速排序、归并排序、堆排序等。
- 阶乘阶 O(n!)
阶乘阶对应数学上的“全排列”问题。给定 n 个互不重复的元素,求其所有可能的排列方案,方案数量为:
n! = n * (n-1) * (n-2) * ...*2 * 1
def factorial_recur(n):
"""阶乘阶(递归实现)"""
if n == 0:
return 1
count = 0
# 从 1 个分裂出 n 个
for _ in range(n):
count += factorial_recur(n - 1)
return count
<2> 空间复杂度
- 定义:用来估计算法内存占用大小的一个式子。
- 空间复杂度的表示方式和时间复杂度一样。
- “空间换时间”
- 常数阶 O(1)
常数阶常见于数量与输入数据大小 n 无关的常量、变量、对象。
# 循环中的变量占用 O(1) 空间
for _ in range(n):
c = 0
- 线性阶 O(n)
线性阶常见于元素数量与 n 成正比的数组、链表、栈、队列等:
def store_in_array(data):
# 假设data是一个长度为n的列表
n = len(data)
# 创建一个新的数组来存储数据,空间复杂度为O(n)
arr = []
for i in data:
arr.append(i)
# 这里我们只是简单地将数据复制到了一个新数组,所以其他操作的空间复杂度为O(1)
return arr
# 使用示例
data = [1, 2, 3, 4, 5]
result = store_in_array(data)
print(result)
-
平方阶 O(n2)
-
指数阶 O(2n)
-
对数阶 O(logn)
1.枚举算法
- 枚举的定义:根据所需解决问题的条件,把该问题所有可能的解,一一列举出来,并逐个检验出问题真正解的方法。枚举法也称穷举法。
(1)判断水仙花数
水仙花数:指一个 n 位数(n≥3),它的每个位上的数字的 n 次幂之和等于它本身。例如,153是一个水仙花数,因为1^3 + 5^3 + 3^3 = 153。
题目:找出100~999整数中的所有水仙花数.
- 方法一:使用while循环
num = 100
while num < 1000:
a = num // 100
b = num % 100 // 10
c = num % 10
if a**3+b**3+c**3 == num:
print(num,'是一个水仙花数')
num += 1
#提示:“//”表示整除,“/”表示除法,“%”表示取余,“**”表示幂次方
- 方法二:使用for循环
for x in range(100,1000):
a = int(x/100) #百位数
b = int(x%100/10) #十位数
c = int(x%10) #个位数
if a**3+b**3+c**3==x:
print(x,'是一个水仙花数')
x+=1
结果:

(2)鸡兔同笼
有一个笼子,里面有鸡和兔子。我们知道总共有7个头和18只脚,我们要找出有多少只鸡和多少只兔子。
- 解法一:假设法
先假设它们全是鸡,每少2只脚就说明有一只兔被看成了鸡;将少的脚数量除以2,就可以算出共有多少只兔,我们称这种解题方法为假设法。解题步骤:
- 假设全部是鸡,此时总的脚数:7x2 = 14 只
- 一共被看少的脚数量:18-14 = 4 只
- 兔子的数量:4/2 = 2 只
- 鸡的数量:7-2 = 5 只
- 解法二:一元一次方程
设笼子里有 x 只鸡,那么兔子有:7-x 只。根据题目,我们可以建立以下方程:
脚的总数是 2x + 4*(7-x) = 18(鸡有2只脚,兔子有4只脚,总脚数就是2倍的鸡脚数加上4倍的兔脚数)。
现在我们要来解这个方程组,找出 x 的值。计算结果为:x = 5。所以,笼子里有 5 只鸡和 2 只兔子。
- 解法三:一元二次方程
设笼子里有 x 只鸡和 y 只兔子。根据题目,我们可以建立以下方程:
- 头的总数是 x + y = 7(鸡和兔子的头数加起来)。
- 脚的总数是 2x + 4y = 18(鸡有2只脚,兔子有4只脚,总脚数就是2倍的鸡脚数加上4倍的兔脚数)。
- 现在我们要来解这个方程组,找出 x 和 y 的值。计算结果为: {x: 5, y: 2}。所以,笼子里有 5 只鸡和 2 只兔子。
- 解法四:枚举算法
以上我们用的是数学中列举方程的形式求解,我们也可以利用枚举法,通过python代码帮我们计算最终的结果。
枚举的思路如图所示:一一列举,最终得到总的脚数量为18的组合,答案即为5 只鸡和 2 只兔子。

# 使用while循环求解
head = 7 #鸡和兔总的个数
foot = 18 #鸡和兔总的脚数量
chicken = 0
rabbit = 0
while True:
if 2*chicken + 4*rabbit == 18:
break
chicken += 1
rabbit = head-chicken
print(chicken,rabbit) #5 2
-----------------------------------
# 也可使用for循环求解
chicken = 1
rabbit = 6
for i in range(1, 7):
if 2*chicken + 4*rabbit == 18:
print(chicken, rabbit)
break
chicken += 1
rabbit = 7- chicken
(3)因式分解
题目:有两个两位数,他们的乘积等于1691,求这两个数分别是多少?
for i in range(10,100):
for j in range(10,100):
if i*j == 1691:
print(i,j)
break

思考:以上结果为何会输出两遍?代码能否进行优化呢?
代码优化:
for i in range(10,100):
for j in range(i,100):
if i*j == 1691:
print(i,j)
break

(4)找质数
题目:找出1到20内的所有质数
提示:质数是指大于1的自然数,除了1和它本身以外没有任何正因数(除了1和它本身外不能被其他整数整除)。换句话说,质数是只有两个正因数的数,这两个因数就是1和它自己。
for num in range(2, 21): # 起始值为2,对于范围在2到20的每一个数字
for i in range(2, num): # 对于从2到num-1的每一个数字
if num % i == 0: # 如果num能被i整除
break # 退出内层循环,说明num不是质数
else:
print(num) # 如果内层循环完整执行(即未中断),则说明num是质数,打印输出
# 结果:2、3、5、7、11、13、17、19
2.查找算法
(1)顺序查找
思路:
- 遍历列表。
- 找到跟目标值相等的元素,就返回他的下标。
- 遍历结束后,如果没有搜索到目标值,就返回-1。
第一种写法:
list = [5, 2, 9, 1, 3, 4]
L = len(list)
num = input('请输入您要查找的数字:')
num = int(num)
b = False
for i in range(0, L):
if num == list[i]:
print('您查找到的数字其索引值为:', i)
b = True
break
if b == False:
print('找不到该数字!')
第二种写法:
list = [5,2,9,1,3,4]
L = len(list)
num = input('请输入您要查找的数字:')
num = int(num)
for i in range(0,L):
if num==list[i]:
print('您查找到的数字其索引值为:',i)
break
else:
print('找不到该数字!')
注意:该else语句与for循环相关联,而不是与if语句相关联。如果for循环完成时没有遇到break,则意味着在列表中未找到该数字,else将会被执行。这个写法应该是 Python 特有的,与其他编程语言略有不同。
时间复杂度:O(n)
(2)二分查找
【注意】:二分查找的前提是数字是排序好的。
思路:
- 从数组的中间元素开始,如果中间元素正好是目标值,则搜索结束。
- 如果目标值大于或者小于中间元素,则在大于或小于中间元素的那一半数组中搜索。
动画演示:

list = [1, 2, 3, 4, 5, 9]
L = len(list)
left = 0
right = L-1
target = 9
while left<=right: #这里的判断是left<=right;避免查找的元素处于边缘位置,而没有查找到的情况。【例如:[1,2,3,4],找目标值4】
mid = (left+right)//2 #地板除:只保留整数
if list[mid]<target:
left = mid+1
elif list[mid]>target:
right = mid-1
else:
print('您查找的数字其索引值为:',mid)
break
else:
print('找不到该数字!')
时间复杂度:O(logn)
3. 排序算法
菜鸡三人组:
- 冒泡排序
- 选择排序
- 插入排序
牛逼三人组:
- 快速排序
- 堆排序(难)
- 归并排序(较难)
(1)冒泡排序
思路:
- 1.比较所有相邻的元素,如果第一个比第二个大,则交换他们。
- 2.一轮下来,可以保证最后一个数是最大的。
- 3.以此类推,执行n-1轮,就可以完成排序。
- 动画演示:

代码参考:
list = [6,5,4,1,3,2]
L = len(list)
def fn(list):
for i in range(0,L-1):
for j in range(0,L-1):
if list[j]>list[j+1]:
list[j],list[j+1] = list[j+1],list[j]
return list
print(fn(list))
- 思考:以上代码能否进行优化呢?内层循环需要每次都遍历0~len-1次吗??
- 回答:不需要,因为随着外层循环次数的增加,数组末尾的排序会依次确定好位置,例如,第一轮会确定6的位置,第二轮会确定5的位置。所以,内层循环不需要每次都遍历0~len-1次,只需要遍历len-1-i 次就够了。
优化后的代码:
list = [6,5,4,1,3,2]
L = len(list)
def fn(list):
for i in range(0,L-1):
for j in range(0,L-1-i):
if list[j]>list[j+1]:
list[j],list[j+1] = list[j+1],list[j]
return list
print(fn(list))
冒泡排序时间复杂度:O(n2)
(2)选择排序
思路:
- 1.找到数组中的最小值,把他更换到列表中的第一位。(具体做法:先假设第一数为最小值,记录它的索引值,将第一数和第二个数作比较,如果第一个数大于第二个数,将最小索引值记录为第二个数,依次循环比较,一轮比较下来,最小值所在的索引位置就会被找到,并且把他更换到最开头的位置。
- 2.接着找到第二小的值,把他更换到数组中的第二位。
- 3.以此类推,执行n-1轮,就可以完成排序。
- 动画演示:

参考代码:
list = [6,5,4,1,3,2]
L = len(list)
def fn(list):
for i in range(0,L-1):
min = i
for j in range(i,L-1):
if list[min]>list[j+1]:
min = j+1
list[min],list[i] = list[i],list[min]
return list
print(fn(list))
选择排序时间复杂度:O(n2)
(3)插入排序
插入排序(insertion sort)是一种简单的排序算法,它的工作原理与手动整理一副牌的过程非常相似。
基本思路:
- 在未排序区间选择一个基准元素,将该元素与其左侧已排序区间的元素逐一比较大小,并将该元素插入到正确的位置。
具体步骤:
- 从第二个元素开始,依次将元素插入已经排序好的部分。
- 遍历已排序好的部分,找到合适的插入位置。
- 将待排序的元素插入合适的位置。
- 将大于待排序元素的元素向后移动一个位置。
- 依次类推,完成插入排序。
例子:
插入排序的总体过程,类似我们打牌,摸牌后进行依次插入的过程:
举例:假如已经进行到31这个数了,31前面的数我们已经插入排序完毕了;那么对于31这个数,我们需要先将其与93比较,31<93,交换位置;接着比较31<77,交换位置;接着比较31<54,交换位置;接着比较31>26,不需要交换位置了,此时内层循环可以结束了。

动画演示:

代码参考:

插入排序的外层循环为for循环 + 内层循环为while循环,所以时间复杂度为 O(n2)
(4)快速排序

- 第一轮排序的代码:
def partition(list,left,right):
tmp = list[left]
while left < right:
while left < right and list[right] >= tmp: # 从右边找出比tmp小的数
right -= 1 # 往左移动一步
list[left] = list[right] # 把右边的值给到左边的空缺位置
print(list)
while left < right and list[left] <= tmp:
left += 1
list[right] = list[left]
print(list)
list[left] = tmp # 将tmp进行归位
list = [5,7,4,6,3,1,2,9,8]
print(list)
partition(list, 0, len(list)-1)
print(list)
结果:

问题解析:
问: 为何是先从右往左进行查找?
答: 因为左边空出了位置, 从右往左找出比tmp小的数字, 可以放到left指针所在的位; 如果一开始从左往右查找, 右边并没有空余位置。
代码解析1:
while left < right and list[right] >= tmp:
问: 以上这行代码为何添加条件判断 left < right
答: 因为如果不添加, right可能会跑到left的左边, 比如5 6 7,right指针最终会移动到5所在位置的左边
# 代码解析2:
while left < right and list[right] >= tmp:
问: 以上这行代码为何是 list[right] >= tmp, 不能是list[right] > tmp:
答: 因为如果是list[right] > tmp, 假如列表为5 6 5 7, right指针移动到5所在位置就会停止了, 此时
列表的顺序为: 5 6 5 7, left指针也会一直停留在左边5的位置, 循环无法跳出来.
- 添加递归函数,实现左右两边也进行快速排序,最终版代码:
def quick_sort(list,left,right):
if left < right: # 至少存在两个元素
mid = partition(list,left,right)
quick_sort(list,left,mid-1)
quick_sort(list,mid+1,right)
def partition(list, left, right):
tmp = list[left]
while left < right:
while left < right and list[right] >= tmp: # 从右边找出比tmp小的数
right -= 1 # 往左移动一步
list[left] = list[right] # 把右边的值给到左边的空缺位置
while left < right and list[left] <= tmp:
left += 1
list[right] = list[left]
list[left] = tmp # 将tmp进行归位
return left;
list = [5, 7, 4, 6, 3, 1, 2, 9, 8]
quick_sort(list, 0, len(list)-1)
print(list)
结果:
快速排序时间复杂度:O(nlogn)
4.栈
- 定义:栈是一个数据集合,可以理解为只能在一端进行插入或者删除操作的列表。
- 特点:后进先出
- 基本操作:
- 进栈:append
- 出栈:pop
- 取栈顶:list[-1]
class Stack:
def __init__(self):
self.stack = []
def append(self,element):
self.stack.append(element)
def pop(self):
return self.stack.pop()
def get_top(self):
if len(self.stack)>0:
return self.stack[-1]
else:
return None
stack = Stack()
stack.append(1)
stack.append(2)
stack.append(3)
print(stack.stack) #[1,2,3]
print(stack.pop()) #3
题目:有效的括号
5.队列
- 队列是一个数据集合,仅允许在列表的一端进行插入,另一端进行删除。
- 进行插入的一端为队尾,插入动作称为进队或入队。
- 进行删除的一端为队头,删除动作称为出队。
- 队列的性质:先进先出。
在这里插入代码片
6.链表
7.二叉树
8.深度优先搜索
9.广度优先搜索
10.图
11.贪心算法
12.动态规划
(1)动态规划算法介绍
LeetCode简单的动态规划题:
LeetCode较难的动态规划题:
总结:
动态规划与其说是一个算法,不如说是一种方法论。
该方法论主要致力于将“合适”的问题拆分成三个子目标一一击破:
- 1.建立状态转移方程
- 2.缓存并复用以往结果
- 3.按顺序从小往大算
(2)01背包”问题
概念:有N件物品和一个最多能装重量为W 的背包。第i件物品的重量是weight[i],价值是value[i]。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。




1. 假如现在只有吉他(G) , 这时不管背包容量多大,只能放一个吉他1500(G)
2. 假如有吉他和音响, 验证公式:v[1][1] =1500
(1). i = 1, j = 1
(2). w[i] = w[1] = 1 j = 1
v[i][j]=max{v[i-1][j], v[i]+v[i-1][j-w[i]]} :
v[1][1] = max {v[0][1], v[1] + v[0][1-1]} = max{0, 1500 + 0} = 1500
3. 假如有吉他/音响/电脑, 验证公式:v[3][4]
(1). i = 3;j = 4
(2). w[i] = w[3] =3 j = 4
j = 4 >= w[i] = 3 => 4 >= 3
v[3][4] = max {v[2][4], v[3] + v[2][1]} = max{3000, 2000+1500} = 2000+1500
归纳:
从表格的右下角开始回溯,如果发现前n个物品的最佳组合的价值和前n-1个物品最佳组合的价值一样,说明第n个物品没有被装入;否则,第n个物品被装入。
问题:背包容量为4时,能装入物品的最大价值是多少?
参考代码:
w = [1, 4, 3] # 物品重量
value = [1500, 3000, 2000] # 物品的价值
m = 4 # 背包容量
n = 3 # 物品的个数
# 初始化二维数组:4行5列
v = []
for i in range(4):
v.append([])
for j in range(5):
v[i].append(0)
for i in range(1, 4): # 先遍历物品
for j in range(1, 5): # 后遍历背包容量
if w[i-1] > j: # w[i - 1]是避免跳过第一个物品,同理else中的语句也是一样的
v[i][j] = v[i-1][j]
else:
v[i][j] = max(v[i - 1][j], value[i - 1] + v[i - 1][j - w[i - 1]])
print(v)
#结果:[
# [0, 0, 0, 0, 0],
# [0, 1500, 1500, 1500, 1500],
# [0, 1500, 1500, 1500, 3000],
# [0, 1500, 1500, 2000, 3500]
# ]
LeetCode中 “01背包” 题型汇总:
- 分割等和子集:转化后为0-1背包可行性问题。
- 目标和:转化问题以后为0-1背包方案数问题。
- 最后一块石头的重量 II:转化后为0-1背包最小值问题。
- 474. 一和零:两个维度的01背包
(3)完全背包”问题
概念:有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],价值是value[i]。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。
完全背包和01背包问题唯一不同的地方就是,每种物品有无限件。
w = [1, 4, 3] # 物品重量
value = [1500, 3000, 2000] # 物品的价值
m = 4 # 背包容量
n = 3 # 物品的个数
# 初始化二维数组:4行5列
v = []
for i in range(4):
v.append([])
for j in range(5):
v[i].append(0)
for i in range(1, 4): # 先遍历物品
for j in range(1, 5): # 后遍历背包容量
for k in range(j//w[i-1]+1):
if w[i-1] > j: # w[i - 1]是避免跳过第一个物品,同理else中的语句也是一样的
v[i][j] = v[i-1][j]
else:
v[i][j] = max(v[i - 1][j], k*value[i - 1] +
v[i][j - k*w[i - 1]])
print(v)
# 结果:[
# [0, 0, 0, 0, 0],
# [0, 1500, 3000, 4500, 6000],
# [0, 1500, 3000, 4500, 6000],
# [0, 1500, 3000, 4500, 6000]
# ]
LeetCode中 “完全背包” 题型汇总:
(4) “打家劫舍”系列
(5)“股票”系列【大多可用“贪心”思维】

(6) “子序列”系列
- 最大子序和
- 最长连续递增序列
- 最长递增子序列【较难】
- 最长递增子序列的个数
【难】
以下标黄题目思路基本一致:
==最长重复子数组==【较难】
==最长公共子序列==【较难】
==不相交的线==【较难】
不同的子序列【困难】
编辑距离【困难】
回文子串【较难】
最长回文子串【较难】















 8886
8886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









