






1、背景
车牌识别技术可以实现自动登记车辆“身份”,已经被广泛应用于各种交通 场合,对“平安城市”的建设有着至关重要的作。具体概括如下: (1)电子警察系统 电子警察系统作为一种抓拍车辆违章违规行为的智能系统,大大降低了交通 管理压力。电子警察系统大大节省警力,规范城市交通秩序,缓解 交通拥堵,减少交通事故。 (2)卡口系统 卡口系统对监控路段的机动车辆进行全天候的图像抓拍,自动识别车牌号码 (3)高速公路收费系统 高速公路收费系统已经基本实现自动化,当车辆在高速公路收费入口站时, 系统进行车牌识别,保存车牌信息,当车辆在高速公路收费出口站时,系统再次进 行车牌识别,与进入车辆的车牌信息进行比对,只有进站和出站的车牌一致方可 让车辆通行,自动收费系统可以有效地提高车辆的通行效率,并且可以有效地检 测出逃费车辆。
2、跨平台应用系统AIdlux
AIdlux主打的是基于ARM架构的跨生态(Android/鸿蒙+Linux)一站式AIOT应用开发平 台。用比较简单的方式理解,我们平时编写训练模型,测试模型的时候,常用的是 Linux/window系统。而实际应用到现场的时候,通常会以几种形态:GPU服务器、嵌入式设 备(比如Android手机、人脸识别闸机等)、边缘设备。GPU服务器我们好理解,而Android 嵌入式设备的底层芯片,通常是ARM架构。而Linux底层也是ARM架构,并且Android又是 基于Linux内核开发的操作系统,两者可以共享Linux内核。因此就产生了从底层开发一套应 用系统的方式,在此基础上同时带来原生Android和原生Linux使用体验。

3、课程准备
①下载数据集CCPD,官网链接是:https://github.com/detectRecog/CCPD
网站里包含了蓝牌和绿牌,这课程主要是使用蓝牌作为检测对象;因此,我们选择ccpd_blur、ccpd_challenge、ccpd_db、ccpd_fn、ccpd_weather五个数据集作为整体的数据集,共计84280张图片
②数据集转换,下载第三节课资源中的tools/ParaseData.py,,将所有标签直接转换成yolo格式保存。
③随机选择,代码文件中的tools/cp10000.py,从里面随机抽取1w张来做为训练集
④对车牌进行解析,在tools/ccpd2lpr.py文件下,将路径换成自己的路径,运行python ccpd2lpr.py
⑤将准备好的数据集以及下载的yolov5代码上传至服务器,这里我使用的是Nvidia的A40服务器。
4、服务器训练数据集
在目录下的tools文件夹下,修改其地址,运行 split_train_val.py
生成如下:
②配置data/ccpd.yaml

③修改train_yolov5中的配置参数
这里我出现的错误就是地址不对,进场使用/或者./来返回上一级目录,但很容易出错,所以直接绝对路径,不会出错。
运行train_yolov5.py,得到如下的结果,这里我们下载best.pt文件

④配置训练参数,train_lprnet.py ,主要修改训练和验证的文件夹目录,其他的参数按需修改,同上,之后运行python train_lprnet.py,在weights 文件夹下面会有lprnet_best.pth的权重文件
5、PC端推理实现
①运行python detect_yolov5.py ,得到结果, 同理修改test_lprnet.py中的配置路径,python test_lprnet.py

运行python detect_torch_pipeline测试车牌识别的整体效果(其中三个问号指中文乱码,这是因为cv2.putText()函数中只能显示英文,不能显示中文)。

6、模型轻量化
①模型移植到Android端的话,我们需要将模型转换成Android端适配的模型。一般android移动端需要轻量化模型,轻量化模型如ncnn,tflite, paddlelite等,这里我们选择的tflite模型,不过pytorch直接转tflite的工具不齐全,一般都会转成序列化成onnx,再轻量化模型, 以pytorch->onnx->tflite 方式
运行export_yolov5.py,生成onnx 在weights权重
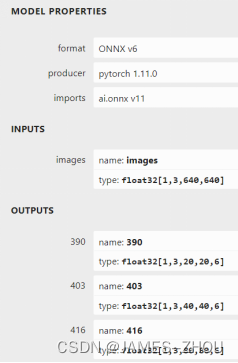
Netron可视化best.onnx的方法
浏览器中输入链接:https://lutzroeder.github.io/netron/,点击open model,打开best.onnx文件,点击右下角,出现如左图。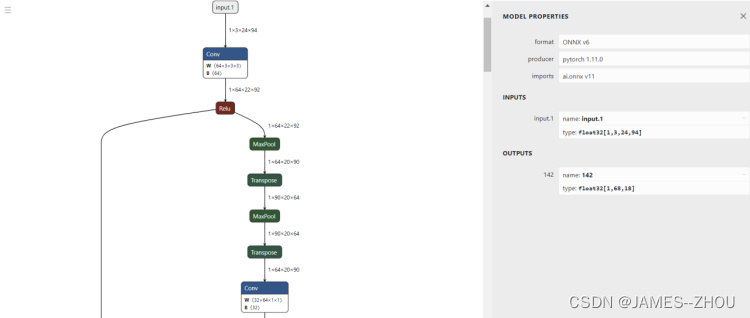
②导出onnx模型
导出onnx模型的主要步骤是:搭建算法网络→导入算法模型→确认输入输出维度→通过torch.onnx.export导出,打开export_lprnet.py。将模型的地址修改成自己对应的地址即可
运行export_lprnet.py,生成如下的结果

完成后,再运行一次python diff_onnx_pytorch.py,结果显示onnx模型推理和pytorch模型推理结果基本相等,则说明onnx模型转换的没有问题结果输出,结果如下:
③前向推理
模型的加载,之前的torch.load方式加载,这里是onnxruntime来加载;是为了剥离torch框架,需要将图像的前处理和结果的后处理部分中涉及到的torch部分都改成np的实现,detect_torch_pipeline.py中
改成detect_onnx_pipeline.py
同时用通过 detect_torch_pipeline.py 和detect_onnx_pipeline.py 运行同一张图片,结果显示如下:结果一致。
Onnx与torch运行出的结果


7、车牌检测+识别模型的tflite的轻量化
安装onnx-tensorflow环境框架
车辆检测模型的tflite轻量化:
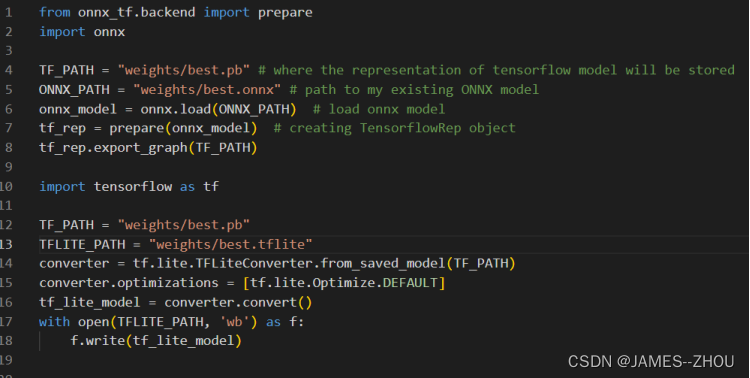
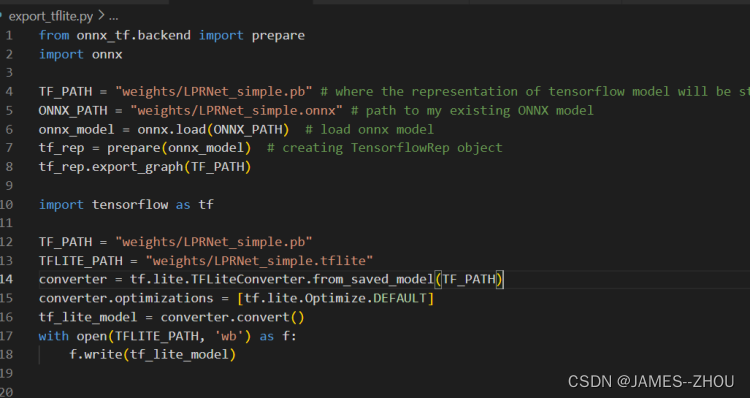
运行生成

通过netron软件打开yolov5.tflite模型,发现输出output的顺序是40,20,80;而onnx模型的顺序20,40,80,因此要修改tflite输出的代码,将输出顺序重排:
运行结果

问题解决:
通过导入PIL来对中文字符进行输入,因为cv2.puttext()函数中只能显示英文,不能显示中文,所以在/home/code_plate_detection/recognization/aidlux/utils.py中修改plot_one_box_class()函数
在这from PIL import Image, ImageDraw, ImageFont
def plot_one_box_class(x, img, color=None, label=None, line_thickness=None):
#使用PIL方法对检测框中的数据进行显示
cv2img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_PIL = Image.fromarray(cv2img)
#使用ttf字体文件,并设置字体的大小是20,先下载simhei.ttf字体
font = ImageFont.truetype('/home/code_plate_detection_recognization/fontdata/simhei.ttf', 20)
# Plots one bounding box on image img,其中image.shape[0]代表图像的垂直高度,img.shape[1]代表的图像的水平宽度,image.shape[2]代表图像的通道数,image[:2]表示取图像的长宽,image[:3]表示取图像的长宽通道
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [np.random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
draw = ImageDraw.Draw(img_PIL)
text_size = draw.textsize(label, font)
draw.text((c1[0], c1[1]-16), label, (255, 0, 255), font=font)
# draw.text((c1[0], c1[1]-16), label, fill=(0, 0, 0), font=font)
#draw.rectangle(shape,fill=填充的颜色,outline = 边框的颜色)
draw.rectangle((c1, c2), fill= None, outline = "green")
image = cv2.cvtColor(np.array(img_PIL), cv2.COLOR_RGB2BGR)
return image
8、运行自己拍摄的视频结果
①拍摄相机与车牌形成一定的夹角检测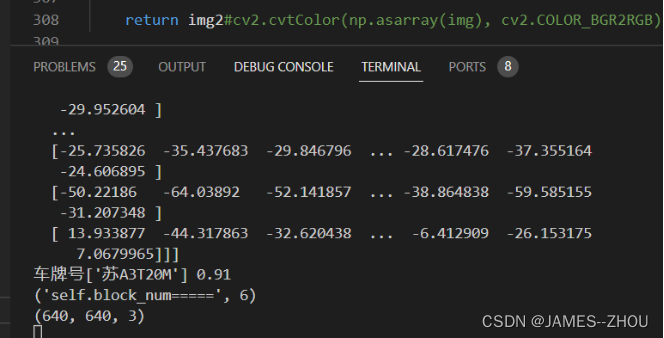

②平行面检测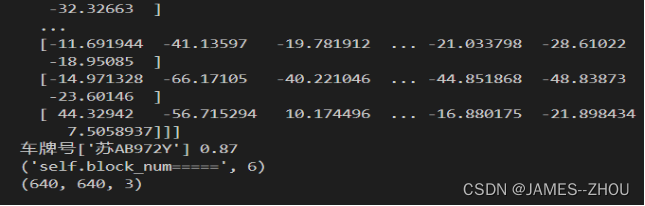

9、总结
通过本次的案例学习,非常感谢老师的讲解,学会了通过手机端的Aidlux平台来尝试AI智能场景的部署,进一步加深了对深度学习以及分布式AIOT开发的了解,在今后的学习中会继续了解与学习这方面的知识。














 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









