









目录
Flask菜鸟实战
pycharm文件开头设置
参考:pycharm的文件开头模板设置_许嵩66的博客-CSDN博客_pycharm开头怎么写
技术:flask + requests + mysql
利用(爬取)菜鸟python教程(https://www.runoob.com/python3/python3-tutorial.html)的数据建立一个网站
模型层面
在Flask中可以使用Flask-Migrate扩展,来实现数据迁移。并且集成到Flask-Script中,所有操作通过命令就能完成。
SQLAlchemy是一个功能强大的ORM映射器
pip install flask # flask 源码
pip install flask-migrate # 数据迁移
pip install flask_script # 指令封装的
pip install flask_sqlalchemy # 操作ORM
# pip install flask_script -i https://pypi.tuna.tsinghua.edu.cn/simple注意一点,这里安装flask-migrate版本可能会是3以上版本,会导致后面生成迁移文件时报错: cannot import name 'MigrateCommand' from 'flask_migrate',这是因为flask-migrate版本太高,MigrateCommand已经移除。
解决方法①:pip install flask-migrate==2.7.0
解决方法②:使用flask-cli
可能还会遇到一点:ModuleNotFoundError: No module named 'flask._compat'
解决方法①:降低flask版本,pip install flask==1.1.2
解决方法②:修改一下flask_script/__init__.py中from ._compat import text_type 改成 from flask_script._compat import text_type
2.1 数据库配置
from flask_migrate import Migrate, MigrateCommand
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_script import Manager
HOST = '127.0.0.1'
PORT = '3306'
DATABASE = 'learning_test' # 创建对应的数据库
USERNAME = 'root' # 对应的登录账号
PASSWORD = '123456' # 登录密码
DB_URI = "mysql+pymysql://{username}:{password}@{host}:{port}/{db}?charset=utf8".format(username=USERNAME,password=PASSWORD, host=HOST,port=PORT, db=DATABASE)
app = Flask(__name__)
class Config(object):
# 设置连接数据库的URL
app.config['SQLALCHEMY_DATABASE_URI'] = DB_URI
# 设置sqlalchemy自动更跟踪数据库
SQLALCHEMY_TRACK_MODIFICATIONS = True
# 设置密钥,用于csrf_token的加解密
app.config["SECRET_KEY"] = "xhosd6f982yfhowefy29f"
# 读取配置
app.config.from_object(Config)
# 创建数据库sqlalchemy工具对象
db = SQLAlchemy(app)
# 初始化 migrate
# 两个参数一个是 Flask 的 app,一个是数据库 db
migrate = Migrate(app, db)
# 初始化管理器
manager = Manager(app)
# 添加 db 命令,并与 MigrateCommand 绑定
manager.add_command('db', MigrateCommand)
# 标签表
class Tag(db.Model):
__tablename__ = 'tb_cat'
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
title = db.Column(db.String(150))
desc = db.Column(db.TEXT)
read = db.Column(db.Integer,default=0)
def __str__(self): # 设置查询时返回的内容,此处设置返回标题
return 'title:%s' %self.title
@app.route('/')
def index():
return 'hello world'
if __name__ == '__main__':
# 通过管理对象来启动flask
manager.run()这里在脚本中通过管理对象启动,是会失败的,因为正常是通过app.run()启动
manager.run()会报错:
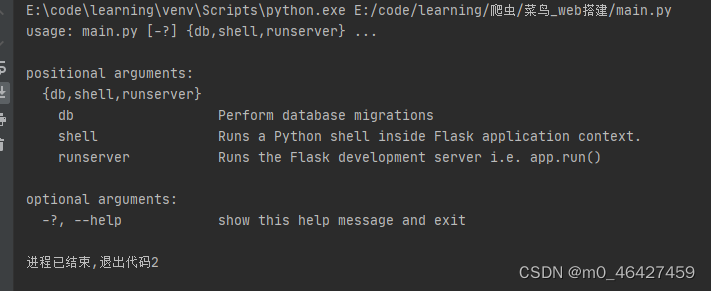
因此我们需要通过runserver去启动
方法①:在命令行中用:python main.py runserver
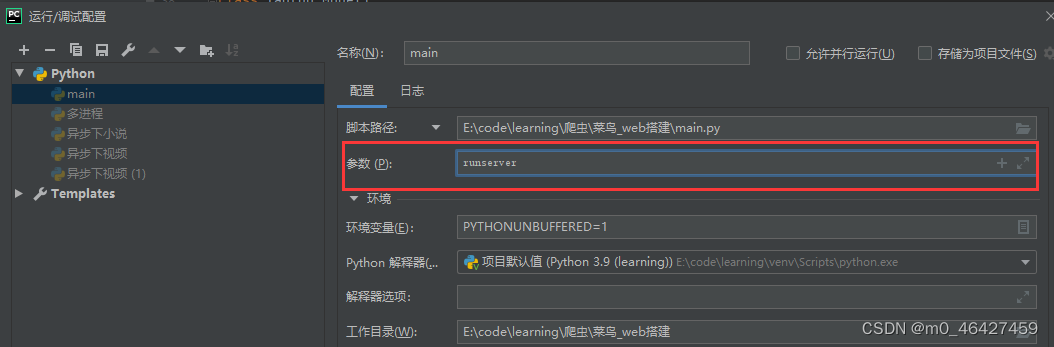
方法②:在pycharm中进行配置
先进入编辑配置,在参数中输入runserver即可。此时该脚本就会运行在runserver上。
2.1.1字段说明
| 数据类型 | 说明 |
|---|---|
| Integer | 整型 |
| String | 字符串 |
| Text | 文本 |
| DateTime | 日期 |
| Float | 浮点型 |
| Boolean | 布尔值 |
| PickleType | 存储一个序列化( Pickle )后的Python对象 |
| LargeBinary | 巨长度二进制数据 |
2.2 创建迁移仓库
# 这个命令会创建migrations文件夹,所有迁移文件都放在里面
python manage.py db init
# 执行迁移,此时数据库会生成alembic_version表,记录每个版本
python manage.py db migrate
# 函数把迁移中的改动应用到数据库中,此时会生成项目中定义的表
python manage.py db upgrade视图层面
3.1 视图编写
class IndexView(views.MethodView):
def __render(self, error=None):
return render_template('index.html', error=error)
def get(self):
return self.__render()
# 路由注册
app.add_url_rule('/', view_func=IndexView.as_view('/'))3.2 首页编写
class IndexView(views.MethodView):
def __render(self, error=None):
obj = Tag.query.all()
tag_id = int(request.args.get('c_id', 1))
text = Tag.query.filter_by(id=tag_id).first()
context = {
'title':obj,
'text':text
}
return render_template('index.html', error=error,objs = context)
def get(self):
return self.__render()
app.add_url_rule('/', view_func=IndexView.as_view('index'))3.3 跳转页视图
class QueryView(views.MethodView):
def get(self,c_id):
tag_id = c_id
obj = Tag.query.all()
text = Tag.query.filter_by(id=tag_id).first()
context = {
'text': text,
'read':text.read,
'title': obj,
'id': tag_id,
}
return render_template('index.html', objs=context)
app.add_url_rule('/<c_id>', view_func=QueryView.as_view('id'))
index.html这个地方的a标签href就是跳转页发送get请求的地方,点击了之后就会触发get请求http:/localhost/12,因此QueryView就能接收到
模板层
首页Html文本
在bootstrap用模板进行改写。在项目根目录生成templates文件夹,里面加入index.html,内容如下
bootstrap模板文件可以参考:https://v3.bootcss.com/getting-started/在网站最下面
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>python3教程</title>
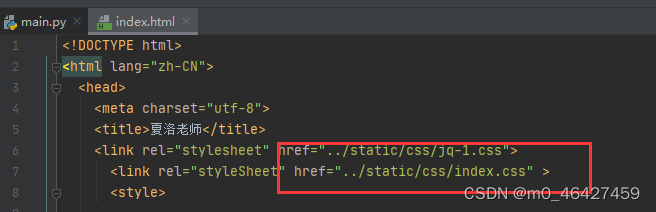
<link rel="stylesheet" href="../static/css/jq-1.css">
<link rel="styleSheet" href="../static/css/index.css" >
<style>
.navbar-brand{
float: left;
width: 170px;
height: 50px;
}
.navbar-brand img{
width: 100%;
height: 100%;
}
</style>
{# <link rel="stylesheet" href="https://www.baidu.com/wp-content/themes/runoob/style.css?v=1.165">#}
</head>
<body>
<!-- 头部信息开始 -->
<nav class="navbar navbar-inverse navbar-fixed-top" style="background-color:#96b97d;">
<div class="container-fluid w">
<div class="navbar-header">
<!--
<a class="navbar-brand" style="color: #fff0f0" href="#"><img src="../static/images/tl.png" alt=""></a>
-->
<a class="navbar-brand" style="color: #fff0f0;font-size: 24px;line-height: 50px" href="#">菜鸟教程_python</a>
</div>
<div id="navbar" class="navbar-collapse collapse">
<ul class="nav navbar-nav navbar-right">
<li><a href="#" target="_blank">登录</a></li>
<li><a href="javascript:void(0);" id="exit">退出</a></li>
<li><a href="#">隐私空间</a></li>
<li><a href="#">帮助</a></li>
</ul>
</div>
</div>
</nav>
<!-- 头部信息结束 -->
<div class="container-fluid w">
<div class="row">
<div class="col-sm-3 col-md-2 sidebar">
<ul class="nav nav-sidebar" id="xxx">
<li class="active"><a href="#" style="color: #0f0f0f;font-size: 18px;background-color:darkseagreen">Python3 教程</a></li>
{% for i in objs.title %}
<li {% if i.id == objs.text.id %} class="active" {% endif %}>
<a href="{{ i.id }}" data-id="{{ i.id }}" id="num">{{ i.title }}</a>
</li>
{% endfor %}
</ul>
</div>
<div class="col-sm-9 col-sm-offset-3 col-md-10 col-md-offset-2 main">
<div class="box">
<button type="submit" class="btn btn-success">学习</button>
</div>
<h3 class="sub-header" style="color: coral">人生苦短、我用Python</h3>
<p >阅读:<em id="read" style="color: coral; font-size: 20px; font-family: Arial">{{ objs.read }}</em></p>
<div class="table-responsive">
{# safe用于过滤标签信息#}
{{ objs.text.desc | safe }}
</div>
<h3>关于作者</h3>
<p><a href="http://www.baidu.com">百度</a>aaa<a href="http://www.baidu.com">Python高级技术</a>bnbb</p>
<!-- 评论 -->
{% include 'common.html' %}
<!--
<div><img src="../static/images/wx.png" alt=""></div>
<p>使用窄屏手机的童鞋,请点击左上角“目录”查看教程:</p>
-->
</div>
</div>
</div>
<!-- Bootstrap core JavaScript
================================================== -->
<!-- Placed at the end of the document so the pages load faster -->
<script src="https://cdn.bootcss.com/jquery/1.12.4/jquery.min.js"></script>
<script src="https://cdn.bootcss.com/bootstrap/3.3.7/js/bootstrap.min.js"></script>
<script>
$("#exit").on("click",function(){ //将退出按钮的id设置为exit,然后将这个函数在公共文件里面即可
console.log('abcd');
window.location.href = '/clear'
})
</script>
<script>
var $lis = $('.nav-sidebar li');
$lis.click(function () {
$(this).addClass('active').siblings('li').removeClass('active');
});
</script>
<script>
$('.box button').click(function () {
window.location.href = 'https://mmzztt.com/'
})
</script>
</body>
</html>项目结构
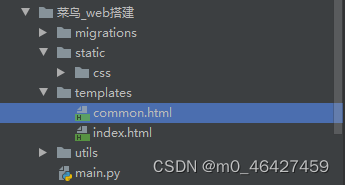
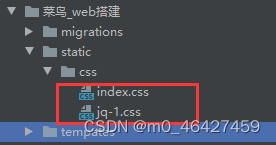
对于index.py涉及到的一些js、css,在项目根目录下新建文件夹static
数据层
技术:使用python爬虫抓取,requests + myqsl
抓取地址:Python3 教程 | 菜鸟教程
抓取内容:分类、明细
示例code
import traceback
import pymysql
import requests
def get_conn():
conn = pymysql.connect(host='127.0.0.1',port=3306,user='root',password='',db='a_xls',charset='utf8')
course =conn.cursor()
return conn,course
def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
url = 'https://www.runoob.com/python3/python3-interpreter.html'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
from lxml import etree
from pyquery import PyQuery as pq
def crawl():
res = requests.get(url,headers=headers)
html = etree.HTML(res.text)
maps = lambda x: x[0] if x else ''
for i in html.xpath('//div[@id="leftcolumn"]/a'):
src = maps(i.xpath('./@href'))
if not src.startswith('/'):
src = '/python3/' + src
title = maps(i.xpath('./@title'))
c_url = 'https://www.runoob.com' + src
res1 = requests.get(c_url,headers=headers)
content = pq(res1.text)
body = content('.article-intro')
print('*'*50)
# print(c_url)
# print(body)
save(title,body)
def save(title,body):
'''保存模块 '''
try:
import datetime
item = (title,body,0)
print(item)
conn, cursor = get_conn()
sql = """insert into tb_cat (title,`desc`,`read`) values (%s,%s,%s)"""
# for i in item:
cursor.execute(sql,item)
conn.commit()
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
if __name__ == '__main__':
crawl()Selenium自动化
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬。对于一些 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。
1、 准备工作
本节以 Chrome 为例来讲解 Selenium 的用法。在开始之前,请确保已经正确安装好了 Chrome 浏览器并配置好了 ChromeDriver。另外,还需要正确安装好 Python 的 Selenium 库
pip install selenium
安装驱动
官网:http://chromedriver.storage.googleapis.com/index.html
安装后解压放到python安装包的根目录,这样解释器可以直接找到驱动
注意:
-
驱动要对应浏览器版本,否者会无法启动
-
禁止浏览器更新 services.msc 找到Google更新服务给禁止自动更新,可以让驱动用的更久,否则chrome更新后驱动也要对应更新
2、 声明浏览器对象
Selenium 支持非常多的浏览器,如 Chrome、Firefox、Edge 等,还有 Android、BlackBerry 等手机端的浏览器。另外,也支持无界面浏览器 PhantomJS。
此外,我们可以用如下方式初始化:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()这样就完成了浏览器对象的初始化并将其赋值为 browser 对象。接下来,我们要做的就是调用 browser 对象,让其执行各个动作以模拟浏览器操作。
3、基本使用
运行代码后发现,会自动弹出一个 Chrome 浏览器。浏览器首先会跳转到百度,然后在搜索框中输入 Python,接着跳转到搜索结果页
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
browser.find_element_by_id('su').click()
# 提取页面
print(browser.page_source.encode('utf-8','ignore'))
# 提取cookie
print(browser.get_cookies())
# 提取当前请求地址
print(browser.current_url)
browser.close()from selenium import webdriver
options = webdriver.ChromeOptions()
# 禁止图片,加快页面加载速度
prefs = {"profile.managed_default_content_settings.images": 2}
options.add_experimental_option("prefs", prefs)
# 无头模式
option.add_argument("-headless")
# 通过设置user-agent
user_ag='MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; '+
'CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1'
options.add_argument('user-agent=%s'%user_ag)
#隐藏"Chrome正在受到自动软件的控制"
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option('excludeSwitches', ['enable-automation'])
#设置代理,可以翻墙
options.add_argument('proxy-server=' +'192.168.0.28:808')
#将浏览器最大化显示
browser.maximize_window()
# 设置宽高
browser.set_window_size(480, 800)
# 通过js新打开一个窗口
driver.execute_script('window.open("https://www.baidu.com");')
browser = webdriver.Chrome(chrome_options=options)
# 执行完毕后退出浏览器,销毁进程
browser.quit()4、查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而 Selenium 提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 模拟键盘操作
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
s = browser.find_element(By.ID, "q")
s.send_keys('衣服')
s.send_keys(Keys.ENTER) # 回车 确定的意思这里列出所有获取单个节点的方法:(低版本的selenium,现在4.3版本都用By了)
find_element_by_id id
find_element_by_class_name 类名字
find_element_by_name 名称
find_element_by_xpath xpath
find_element_by_link_text 专门用来定位超链接文本(标签) 全匹配
find_element_by_partial_link_text 模糊匹配 登录 登(也可以)
find_element_by_tag_name 标签名字
find_element_by_css_selector CSS选择器节点提取
browser.get('https://www.taobao.com/')
# ID选折起定位
s = browser.find_element_by_id('q')
s.send_keys('衣服')
# CSS 选折起定位,class=search-combobox-input-wra的div下的input节点
s = browser.find_element_by_css_selector('div.search-combobox-input-wrap>input')
s.send_keys('衣服')
# xpath 选择器定位
s = browser.find_elements_by_xpath('//div[@class="search-combobox-input-wrap"]/input')
s.send_keys('衣服')另外,Selenium 还提供了通用方法 find_element(),它需要传入两个参数:查找方式 By 和值。实际上,它就是 find_element_by_id() 这种方法的通用函数版本,比如 find_element_by_id(id) 就等价于 find_element(By.ID, id),二者得到的结果完全一致。我们用代码实现一下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID, 'q')
input_first.send_keys('衣服')
print(input_first)
browser.close()4.2 多个节点
如果查找的目标在网页中只有一个,那么完全可以用 find_element() 方法。但如果有多个节点,再用 find_element() 方法查找,就只能得到第一个节点了。如果要查找所有满足条件的节点,需要用 find_elements() 这样的方法。注意,在这个方法的名称中,element 多了一个 s,注意区分。
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements_by_css_selector('.service-bd li')
print(lis)
browser.close()可以看到,得到的内容变成了列表类型,列表中的每个节点都是 WebElement 类型。
也就是说,如果我们用 find_element() 方法,只能获取匹配的第一个节点,结果是 WebElement 类型。如果用 find_elements() 方法,则结果是列表类型,列表中的每个节点是 WebElement 类型。
这里列出所有获取多个节点的方法:
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector当然,我们也可以直接用 find_elements() 方法来选择,这时可以这样写:
lis = browser.find_elements(By.CSS_SELECTOR, '.service-bd li')5、节点交互
Selenium 可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。比较常见的用法有:输入文字时用 send_keys 方法,清空文字时用 clear 方法,点击按钮时用 click 方法。示例如下:
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
input.send_keys('iPhone')
time.sleep(1)
input.clear()
input.send_keys('iPad')
button = browser.find_element_by_class_name('btn-search')
button.click()通过上面的方法,我们就完成了一些常见节点的动作操作,更多的操作可以参见官方文档的交互动作介绍:7. WebDriver API — Selenium Python Bindings 2 documentation
6、动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。比如,对于输入框,我们就调用它的输入文字和清空文字方法;对于按钮,就调用它的点击方法。其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()首先,打开网页中的一个拖曳实例,然后依次选中要拖曳的节点和拖曳到的目标节点,接着声明 ActionChains 对象并将其赋值为 actions 变量,然后通过调用 actions 变量的 drag_and_drop() 方法,再调用 perform() 方法执行动作,此时就完成了拖曳操作
更多的动作链操作可以参考官方文档的动作链介绍:7. WebDriver API — Selenium Python Bindings 2 documentation
页面滚动
# 移动到元素element对象的“顶端”与当前窗口的“顶部”对齐
driver.execute_script("arguments[0].scrollIntoView();", element)
driver.execute_script("arguments[0].scrollIntoView(true);", element)
# 移动到元素element对象的“底端”与当前窗口的“底部”对齐
driver.execute_script("arguments[0].scrollIntoView(false);", element)
# 移动到页面最底部,一次下拉,输入x,y为参数
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
# 移动到指定的坐标(相对当前的坐标移动)
driver.execute_script("window.scrollBy(0, 700)")
# 结合上面的scrollBy语句,相当于移动到700+800=1600像素位置
driver.execute_script("window.scrollBy(0, 800)")
# 移动到窗口绝对位置坐标,如下移动到纵坐标1600像素位置
driver.execute_script("window.scrollTo(0, 1600)")
# 结合上面的scrollTo语句,仍然移动到纵坐标1200像素位置
driver.execute_script("window.scrollTo(0, 1200)")7、执行 JavaScript
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script() 方法即可实现,代码如下:
# document.body.scrollHeight 获取页面高度
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://36kr.com/')
# 下拉边框 一次性下拉
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# scrollTo 不叠加 200 200 scrollBy 叠加 200 300 500操作
# 慢慢的下拉
for i in range(1,9):
time.sleep(random.randint(100, 300) / 1000)
browser.execute_script('window.scrollTo(0,{})'.format(i * 700)) # scrollTo 不叠加 700 1400 2100这里就利用 execute_script() 方法将进度条下拉到最底部
所以说有了这个方法,基本上 API 没有提供的所有功能都可以用执行 JavaScript 的方式来实现了。
8、 获取节点信息
获取属性:使用 get_attribute() 方法来获取节点的属性,但是其前提是先选中这个节点
通过 get_attribute() 方法,然后传入想要获取的属性名,就可以得到它的值了
from selenium import webdriver
url = 'https://pic.netbian.com/4kmeinv/index.html'
browser.get(url)
src = browser.find_elements_by_xpath('//ul[@class="clearfix"]/li/a/img')
for i in src:
url = i.get_attribute('src')
print(url)获取 ID、位置、标签名、大小
另外,WebElement 节点还有一些其他属性,比如 id 属性可以获取节点 id,location 属性可以获取该节点在页面中的相对位置,tag_name 属性可以获取标签名称,size 属性可以获取节点的大小,也就是宽高,这些属性有时候还是很有用的
from PIL import Image
from io import BytesIO
url = 'https://pic.netbian.com/4kmeinv/index.html'
browser.get(url)
img = browser.find_element_by_xpath('//ul[@class="clearfix"]/li[1]/a/img')
location = img.location # 获取图片在页面的位置
size = img.size # 获取图片大小
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size['width']
screen = browser.get_screenshot_as_png()
screen = Image.open(BytesIO(screen))
cap = screen.crop((left, top, right, bottom))
cap.save('asas.png')9、切换 Frame
我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame() 方法来切换 Frame。
browser.get('https://www.douban.com/')
login_iframe = browser.find_element_by_xpath('//div[@class="login"]/iframe')
browser.switch_to.frame(login_iframe)
browser.find_element_by_class_name('account-tab-account').click()
browser.find_element_by_id('username').send_keys('123123123')
注意:对于iframe 网页 一定要切换进去才能够定位10、 延时等待
在 Selenium 中,get() 方法会在网页框架加载结束后结束执行,此时如果获取 page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的 Ajax 请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。
这里等待的方式有两种:一种是隐式等待,一种是显式等待。
隐式等待
当使用隐式等待执行测试的时候,如果 Selenium 没有在 DOM 中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是 0。示例如下:
import time
from selenium import webdriver
s = time.time()
在这里我们用 implicitly_wait() 方法实现了隐式等待
browser.implicitly_wait(10)
browser.get('https://www.zhihu.com/explore')
try:
input = browser.find_element_by_class_name('zu-top-add-question')
finally:
print(time.time() - s)显式等待
隐式等待的效果其实并没有那么好,因为我们只规定了一个固定时间,而页面的加载时间会受到网络条件的影响。
这里还有一种更合适的显式等待方法,它指定要查找的节点,然后指定一个最长等待时间。如果在规定时间内加载出来了这个节点,就返回查找的节点;如果到了规定时间依然没有加载出该节点,则抛出超时异常。示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')
wait = WebDriverWait(browser, 10)
input = wait.until(EC.presence_of_element_located((By.ID, 'q')))
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.btn-search')))
print(input, button)这样可以做到的效果就是,在 10 秒内如果 ID 为 q 的节点(即搜索框)成功加载出来,就返回该节点;如果超过 10 秒还没有加载出来,就抛出异常。
对于按钮,可以更改一下等待条件,比如改为 element_to_be_clickable,也就是可点击,所以查找按钮时查找 CSS 选择器为.btn-search 的按钮,如果 10 秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过 10 秒还不可点击,也就是没有加载出来,就抛出异常。
表 7-1 等待条件及其含义
| 等待条件 | 含义 |
|---|---|
| title_is | 标题是某内容 |
| title_contains | 标题包含某内容 |
| presence_of_element_located | 节点加载出,传入定位元组,如 (By.ID, 'p') |
| visibility_of_element_located | 节点可见,传入定位元组 |
| visibility_of | 可见,传入节点对象 |
| presence_of_all_elements_located | 所有节点加载出 |
| text_to_be_present_in_element | 某个节点文本包含某文字 |
| text_to_be_present_in_element_value | 某个节点值包含某文字 |
| frame_to_be_available_and_switch_to_it frame | 加载并切换 |
| invisibility_of_element_located | 节点不可见 |
| element_to_be_clickable | 节点可点击 |
| staleness_of | 判断一个节点是否仍在 DOM,可判断页面是否已经刷新 |
| element_to_be_selected | 节点可选择,传节点对象 |
| element_located_to_be_selected | 节点可选择,传入定位元组 |
| element_selection_state_to_be | 传入节点对象以及状态,相等返回 True,否则返回 False |
| element_located_selection_state_to_be | 传入定位元组以及状态,相等返回 True,否则返回 False |
| alert_is_present | 是否出现 Alert |
更多详细的等待条件的参数及用法介绍可以参考官方文档:7. WebDriver API — Selenium Python Bindings 2 documentation
11、 前进后退
平常使用浏览器时都有前进和后退功能,Selenium 也可以完成这个操作,它使用 back() 方法后退,使用 forward() 方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
12、选项卡管理
在访问网页的时候,会开启一个个选项卡。在 Selenium 中,我们也可以对选项卡进行操作。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://pic.netbian.com')控制台输出如下:
['CDwindow-4f58e3a7-7167-4587-bedf-9cd8c867f435', 'CDwindow-6e05f076-6d77-453a-a36c-32baacc447df']首先访问了百度,然后调用了 execute_script() 方法,这里传入 window.open() 这个 JavaScript 语句新开启一个选项卡。接下来,我们想切换到该选项卡。这里调用 window_handles 属性获取当前开启的所有选项卡,返回的是选项卡的代号列表。要想切换选项卡,只需要调用 switch_to_window() 方法即可,其中参数是选项卡的代号。这里我们将第二个选项卡代号传入,即跳转到第二个选项卡,接下来在第二个选项卡下打开一个新页面,然后切换回第一个选项卡重新调用 switch_to_window() 方法,再执行其他操作即可。
13、 异常处理
在使用 Selenium 的过程中,难免会遇到一些异常,例如超时、节点未找到等错误,一旦出现此类错误,程序便不会继续运行了。这里我们可以使用 try except 语句来捕获各种异常。
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element')
finally:
browser.close()这里我们使用 try except 来捕获各类异常。比如,我们对 find_element_by_id() 查找节点的方法捕获 NoSuchElementException 异常,这样一旦出现这样的错误,就进行异常处理,程序也不会中断了。
控制台的输出如下:No Element
关于更多的异常类,可以参考官方文档::7. WebDriver API — Selenium Python Bindings 2 documentation。
14、绕过检测
浏览器控制台可以输入navigator.webdriver判断是否为自动化程序驱动,true则是,false则不是
# 无处理
browser.get('https://bot.sannysoft.com/')
# 设置屏蔽
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
browsers = webdriver.Chrome(chrome_options=options)
browsers.get('https://bot.sannysoft.com/')15、selenium案例①
采集义务购商品网站: http://www.yiwugo.com/
from selenium import webdriver
import time,random
# browser = webdriver.Chrome()
from pymongo import MongoClient
class YwShop():
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
self.browser = webdriver.Chrome(chrome_options=options)
def base(self):
self.browser.get('http://www.yiwugo.com/')
input = self.browser.find_element_by_id('inputkey')
input.send_keys('饰品')
self.browser.find_element_by_xpath('//div[@class="search-index"]/span[last()]').click()
def spider(self):
self.drop_down()
li = self.browser.find_elements_by_class_name('pro_list_product_img2')
for j in li:
title = j.find_element_by_xpath('.//li/a[@class="productloc"]')
price = j.find_element_by_xpath('.//li/span[@class="pri-left"]/em')
info = j.find_elements_by_xpath('.//li/span[@class="pri-right"]/span')
address = j.find_element_by_xpath('.//li[@class="shshopname"]')
texts = ''
for i in info:
texts = i.text
items = {
'标题':title.text,
"价钱": price.text,
"地址": address.text,
"信息":texts
}
self.save_mongo(items)
self.page_next()
def save_mongo(self,data):
client = MongoClient() # 建立连接
col = client['python']['xx']
if isinstance(data, dict):
res = col.insert_one(data)
return res
else:
return '单条数据必须是这种格式:{"name":"age"},你传入的是%s' % type(data)
def page_next(self):
try:
next = self.browser.find_element_by_xpath('//ul[@class="right"]/a[@class="page_next_yes"]')
if next:
next.click()
self.spider()
else:
self.browser.close()
except Exception as e:
print(e)
def drop_down(self):
for x in range(1, 10):
j = x / 10
js = f"document.documentElement.scrollTop = document.documentElement.scrollHeight * {j}"
self.browser.execute_script(js)
time.sleep(random.randint(400,800)/1000)
if __name__ == '__main__':
f = YwShop()
f.base()
f.spider()16、selenium案例②
地址:在售商品分类【品牌 正品 低价】_唯品会|12|1|1
技术:selenium自动化
字段:价格、标题 可以自行拓展
保存:mongo
import time
import random
from selenium import webdriver
from pymongo import MongoClient
from fake_useragent import UserAgent
from selenium.webdriver.common.by import By
class Spider:
def __init__(self):
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_argument(f'user-agent={UserAgent().chrome}')
self.browser = webdriver.Chrome(chrome_options=options)
self.client = MongoClient()
self.collection = self.client['spider']['weipin']
def start(self, pages=1):
for i in range(1, pages + 1):
url = f'https://category.vip.com/suggest.php?keyword=%E5%8F%A3%E7%BA%A2&ff=235&page={i}'
self.browser.get(url)
self.turn_page()
self.spider_one_page()
# self.close_browser()
def spider_one_page(self):
for product in self.browser.find_elements(By.XPATH, '//section[@id="J_searchCatList"]/div'):
sku = product.get_attribute('data-product-id')
data = {'sku': sku}
if sku is not None:
data['price'] = product.find_element(By.XPATH, './/div[contains(@class,"c-goods-item__sale-price")]').text
data['title'] = product.find_element(By.XPATH, './/div[contains(@class,"c-goods-item__name")]').text
data['original_price'] = product.find_element(By.XPATH, './/div[contains(@class,"c-goods-item__market-price")]').text
data['product_url'] = product.find_element(By.XPATH, './a').get_attribute('href')
self.save_data(data)
print(data)
def save_data(self, data: dict):
res = self.collection.insert_one(data)
return res
def get_browser(self):
return self.browser
def turn_page(self, frequency=10):
# 页面滚动到底部,让所有数据加载出来
for i in range(frequency):
self.browser.execute_script("window.scrollBy(0, 1000)")
time.sleep(random.randint(1, 3))
def close_browser(self):
if self.browser:
self.browser.quit()
if __name__ == '__main__':
spider = Spider()
spider.start()
Pypputeer
Puppeteer 是 Google 基于 Node.js 开发的一个工具,而 Pyppeteer 又是什么呢?它实际上是 Puppeteer 的 Python 版本的实现,但它不是 Google 开发的,是一位来自于日本的工程师依据 Puppeteer 的一些功能开发出来的非官方版本。
在 Pyppetter 中,实际上它背后也是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染,首先说下 Chrome 浏览器和 Chromium 浏览器的渊源。

总的来说,两款浏览器的内核是一样的,实现方式也是一样的,可以认为是开发版和正式版的区别,功能上基本是没有太大区别的。
安装:pip install pyppeteer
pyppeteer支持异步,而selenium不支持。
注意: 支持异步需要3.5以上的解释器
import pyppeteer
print(pyppeteer.__chromium_revision__) # 查看版本号
print(pyppeteer.executablePath()) # 查看 Chromium 存放路径
# pyppeteer-install 帮助你去安装谷歌,自动安装测试版本 的chrome如果无法启动,需要手动改文件路径
'linux': 'https://storage.googleapis.com/chromium-browser-snapshots/Linux_x64/575458/chrome-linux.zip'
'mac': 'https://storage.googleapis.com/chromium-browser-snapshots/Mac/575458/chrome-mac.zip'
'win32': 'https://storage.googleapis.com/chromium-browser-snapshots/Win/575458/chrome-win32.zip'
'win64': 'https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/575458/chrome-win32.zip'
官方网站:API Reference — Pyppeteer 0.0.25 documentation
1、测试样例
from pyppeteer import launch
import asyncio
import time
async def main():
# 启动一个浏览器
browser = await launch(headless=False,args=['--disable-infobars','--window-size=1920,1080'])
# 创建一个页面
page = await browser.newPage()
# 跳转到百度
await page.goto("http://www.baidu.com/")
# 输入要查询的关键字,type 第一个参数是元素的selector,第二个是要输入的关键字
await page.type('#kw','pyppeteer')
# 点击提交按钮 click 通过selector点击指定的元素
await page.click('#su')
time.sleep(3)
await browser.close()
asyncio.get_event_loop().run_until_complete(main())可以发现这里展示并不会全屏展示,只有一部分
接下来看看launch它的参数简介:
-
ignoreHTTPSErrors (bool):是否要忽略 HTTPS 的错误,默认是 False。
-
headless (bool):是否启用 Headless 模式,即无界面模式,如果 devtools 这个参数是 True 的话,那么该参数就会被设置为 False,否则为 True,即默认是开启无界面模式的。
-
executablePath (str):可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可以指定为已有的 Chrome 或 Chromium。
-
slowMo (int|float):通过传入指定的时间,可以减缓 Pyppeteer 的一些模拟操作。
-
args (List[str]):在执行过程中可以传入的额外参数。
-
ignoreDefaultArgs (bool):不使用 Pyppeteer 的默认参数,如果使用了这个参数,那么最好通过 args 参数来设定一些参数,否则可能会出现一些意想不到的问题。这个参数相对比较危险,慎用。
-
handleSIGINT (bool):是否响应 SIGINT 信号,也就是可以使用 Ctrl + C 来终止浏览器程序,默认是 True。
-
handleSIGTERM (bool):是否响应 SIGTERM 信号,一般是 kill 命令,默认是 True。
-
handleSIGHUP (bool):是否响应 SIGHUP 信号,即挂起信号,比如终端退出操作,默认是 True。
-
dumpio (bool):是否将 Pyppeteer 的输出内容传给 process.stdout 和 process.stderr 对象,默认是 False。
-
userDataDir (str):即用户数据文件夹,即可以保留一些个性化配置和操作记录。
-
env (dict):环境变量,可以通过字典形式传入。
-
devtools (bool):是否为每一个页面自动开启调试工具,默认是 False。如果这个参数设置为 True,那么 headless 参数就会无效,会被强制设置为 False。
-
logLevel (int|str):日志级别,默认和 root logger 对象的级别相同。
-
autoClose (bool):当一些命令执行完之后,是否自动关闭浏览器,默认是 True。
-
loop (asyncio.AbstractEventLoop):事件循环对象。
2、基本配置

2.0 基本参数
params={
# 关闭无头浏览器
"headless": False,
'dumpio':'True', # 防止浏览器卡住
r'userDataDir':'./cache-data', # 用户文件地址
"args": [
'--disable-infobars', # 关闭自动化提示框
'--window-size=1920,1080', # 窗口大小
'--log-level=30', # 日志保存等级, 建议设置越小越好,要不然生成的日志占用的空间会很大 30为warning级别
'--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
'--no-sandbox', # 关闭沙盒模式
'--start-maximized', # 窗口最大化模式
'--proxy-server=http://localhost:1080' # 代理
],
}2.1 设置窗口
# UI模式 频闭警告
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.setViewport({'width': 1200, 'height': 800})2.2 添加头部
await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5")2.3 网页截图
page.screenshot(path='example.png')
2.4 伪装浏览器 绕过检测
Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性,并返回此对象。
# 伪装
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,'
'{ webdriver:{ get: () => false } })}')
await page.goto('https://intoli.com/blog/not-possible-to-block-chrome-headless/chrome-headless-test.html')2.5 案例演示 触发JS
async def run():
browser = await launch()
page = await browser.newPage()
await page.setViewport({'width': 1200, 'height': 800})
await page.goto('https://www.zhipin.com/job_detail/?query=%E8%85%BE%E8%AE%AF%E7%88%AC%E8%99%AB&city=101020100&industry=&position=')
dimensions = await page.evaluate('''() => {
return {
cookie: window.document.cookie,
}
}''')
print(dimensions,type(dimensions))
asyncio.get_event_loop().run_until_complete(run())2.6 boss直聘cookie反爬绕过实践
先通过自动化拿到cookie,然后在传入requests作为参数,此时requests就可以正常请求了。但是cookie只有两分钟有效,可以写入redis设置有效期,当过期时再重新获取。
当然如果请求的多是有封IP的风险的,可以通过拨号或服务器转发等方式。
import asyncio,requests
from pyppeteer import launch
async def run():
browser = await launch()
page = await browser.newPage()
await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5")
await page.setViewport(viewport={'width': 1536, 'height': 768})
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,'
'{ webdriver:{ get: () => false } }) }')
await page.goto('https://www.zhipin.com/job_detail/?query=%E8%85%BE%E8%AE%AF%E7%88%AC%E8%99%AB&city=101020100&industry=&position=')
dimensions = await page.evaluate('''() => {
return {
cookie: window.document.cookie,
}
}''')
headets = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
'cookie': dimensions.get('cookie')
}
res = requests.get(
'https://www.zhipin.com/job_detail/?query=%E8%85%BE%E8%AE%AF%E7%88%AC%E8%99%AB&city=101020100&industry=&position=',
headers=headets)
print(res.text)注:boss主要是cookie token反爬还有IP监测
2.7滚动到页面底部
await page.evaluate('window.scrollBy(0, document.body.scrollHeight)')3、进阶使用
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
async def main():
browser = await launch(headless=False) # 打开浏览器
page = await browser.newPage() # 开启选项卡
# 输入地址访问页面
await page.goto('https://careers.tencent.com/search.html?keyword=python')
# 调用选折器
await page.waitForXPath('//div[@class="recruit-wrap recruit-margin"]/div')
# 获取网页源代码 带有数据的 可以绕过JS反爬虫
doc = pq(await page.content())
# 提取数据
title = [item.text() for item in doc('.recruit-title').items()]
print('title:', title)
# 关闭浏览器
await browser.close()
# 启动异步方法
asyncio.get_event_loop().run_until_complete(main())4、数据提取
# 在页面内执行 document.querySelector。如果没有元素匹配指定选择器,返回值是 None
J = querySelector
# 在页面内执行 document.querySelector,然后把匹配到的元素作为第一个参数传给 pageFunction
Jeval = querySelectorEval
# 在页面内执行 document.querySelectorAll。如果没有元素匹配指定选择器,返回值是 []
JJ = querySelectorAll
# 在页面内执行 Array.from(document.querySelectorAll(selector)),然后把匹配到的元素数组作为第一个参数传给 pageFunction
JJeval = querySelectorAllEval
# XPath表达式
Jx = xpath
# Pyppeteer 三种解析方式
Page.querySelector() # 选择器 css 选择器
Page.querySelectorAll()
Page.xpath() # xpath 表达式
# 简写方式为:
Page.J(), Page.JJ(), and Page.Jx()5、获取属性
提取目标地址:https://pic.netbian.com/4kfengjing/所有的图片资源
async def mains1():
browser = await launch(headless=False, args=['--disable-infobars'])
page = await browser.newPage()
await page.setUserAgent("Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5")
await page.setViewport(viewport={'width': 1536, 'height': 768})
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,'
'{ webdriver:{ get: () => false } }) }')
await page.goto('https://pic.netbian.com/4kmeinv/index.html')
elements = await page.querySelectorAll(".clearfix li a img")
for item in elements:
# 获取连接,getProperty获取到的是一个对象,还需要转换成内容
title_link = await (await item.getProperty('src')).jsonValue()
print(title_link)
await browser.close()
asyncio.get_event_loop().run_until_complete(mains1())6、登录案例
import asyncio
from pyppeteer import launch
async def mains2():
browser = await launch({'headless': False, 'args': ['--disable-infobars', '--window-size=1920,1080']})
page = await browser.newPage()
await page.setViewport({'width': 1920, 'height': 1080})
await page.goto('https://www.captainbi.com/amz_login.html')
await page.evaluateOnNewDocument('() =>{ Object.defineProperties(navigator,'
'{ webdriver:{ get: () => false } }) }')
await page.type('#username', '13555553333') # 账号
await page.type('#password', '123456') # 密码
await asyncio.sleep(2)
await page.click('#submit',{'timeout': 3000})
import time
# await browser.close()
print('登录成功')
asyncio.get_event_loop().run_until_complete(mains2())7、综合案例
抓取口红信息:标题、价格、原价、折扣、品牌 翻页 入库
有些url有编码,可以通过urllib.parse解码和编码
from urllib.parse import quote,unquoteimport requests
from lxml import etree
from loguru import logger
import pandas as pd
from utils import ua
import asyncio
from pyppeteer import launch
class Wph(object):
def __init__(self,url,name):
self.url = url
self.name = name
self.headers = {
'user-agent': ua.get_random_useragent()
}
self.session = requests.session()
self.hadlnone = lambda x:x[0] if x else ''
async def main(self,url):
global browser
browser = await launch()
page = await browser.newPage()
await page.goto(url)
text = await page.content() # 返回页面html
return text
def spider(self):
df = pd.DataFrame(columns=['品牌', '标题', '原价', '现价', '折扣'])
# 发起HTTP请求
# https://category.vip.com/suggest.php?keyword=%E5%8F%A3%E7%BA%A2&brand_sn=10000359
res = self.session.get(self.url,params={'keyword':self.name},headers = self.headers,verify=False)
html = etree.HTML(res.text)
url_list = html.xpath('//div[@class="c-filter-group-content"]/div[contains(@class,"c-filter-group-scroll-brand")]/ul/li/a/@href')
# 迭代品牌URL地址
for i in url_list:
ua.wait_some_time()
# 驱动浏览器 请求
page_html = asyncio.get_event_loop().run_until_complete(self.main('http:' + i))
# 获取网页源代码
page = etree.HTML(page_html)
htmls = page.xpath('//section[@id="J_searchCatList"]/div')
# 迭代商品URL列表
for h in htmls[1:]:
# 评判
pingpai = self.hadlnone(h.xpath('//div[contains(@class,"c-breadcrumbs-cell-title")]/span/text()'))
# 标题
title = self.hadlnone(h.xpath('.//div[contains(@class,"c-goods-item__name")]/text()'))
# 价格 原价
y_price = self.hadlnone(h.xpath('.//div[contains(@class,"c-goods-item__market-price")]/text()'))
# 卖价
x_price = self.hadlnone(h.xpath('.//div[contains(@class,"c-goods-item__sale-price")]/text()'))
# 折扣
zk = self.hadlnone(h.xpath('.//div[contains(@class,"c-goods-item__discount")]/text()'))
logger.info(f'品牌{pingpai},标题{title},原价{y_price},现价{x_price},折扣{zk}')
# 构造字典
pro = {
'品牌':pingpai,
'标题':title,
'原价':y_price,
'现价':x_price,
'折扣':zk
}
df = df.append([pro])
df.to_excel('唯品会数据2.xlsx',index=False)
return df
def __del__(self):
browser.close()
if __name__ == '__main__':
url = 'https://category.vip.com/suggest.php'
name = '香水'
w = Wph(url,name)
w.spider()为什么要用requests.session,主要是session能记录会话信息以及给请求头排序,有些网站会验证请求头顺序。
抓包工具Charles
背景
爬虫抓的数据无非为PC、APP、小程序
PC端可以通过浏览器查找地址 包括API接口数据和静态数据
APP和小程序端都是API接口数据
因此需要抓包工具对请求和响应进行拦截,这时就可以看到API接口的一些内容了。
抓包工具:charles(青花瓷)、fiddler
类似于VPN的原理,在手机端和要访问的服务器之间建立一个墙,然后拦截请求进行转发,
charles官网:Charles Web Debugging Proxy • HTTP Monitor / HTTP Proxy / HTTPS & SSL Proxy / Reverse Proxy
HTTPS协议需要证书绑定(信任证书)
浏览器的一些接口:Web API 接口参考 | MDN
下载雷电模拟器,用3.0版本:安卓模拟器最新以及历史版本下载_雷电安卓模拟器
charles介绍
中文名--> 青花瓷 是一款基于Http协议的代理服务器 通过成为代理,截取请求和响应达到分析抓包的目的。
Charles 主要的功能包括:
1. 截取 Http 和 Https 网络封包。
2. 支持重发网络请求,方便后端调试。
3.支持修改网络请求参数。
4. 支持网络请求的截获并动态修改。
5. 支持模拟慢速网络。
抓包简介
抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作。也 用来检测网络安全。抓包也经常被用来进行数据截取等。对于iOS初学者来说,抓包主要是为了了解网络 请求操作,解决没有专人提供网络接口进行练习的问题。可以抓取大量已经上架AppStore的App的网络 请求,进行网络阶段的操作练习。
软件安装
汉化版:https://www.52pojie.cn/thread-1600964-1-1.html
常规版:https://www.charlesproxy.com/
1、准备工作
请确保已经正确安装 Charles 并开启了代理服务,手机和 Charles 处于同一个局域网下,Charles 代理 和 CharlesCA 证书设置好,另外需要开启 SSL 监听
2、 原理
首先 Charles 运行在自己的 PC 上,Charles 运行的时候会在 PC 的 8888 端口开启一个代理服务,这个 服务实际上是一个 HTTP/HTTPS 的代理。
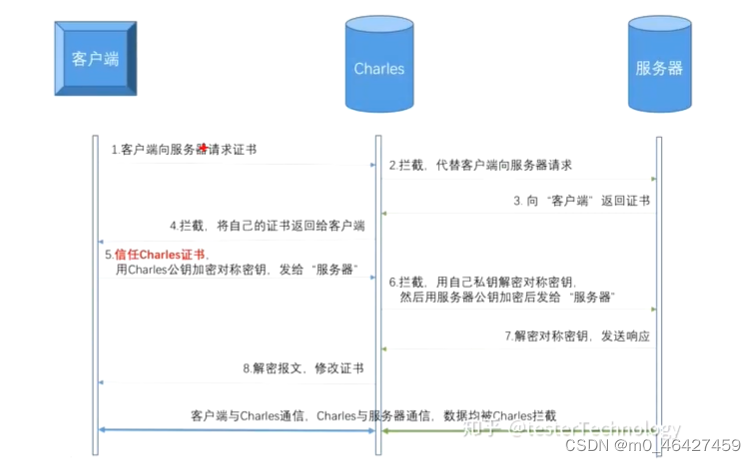
1. 客户端向服务器发起HTTPS请求。
2. Charles拦截客户端的请求,伪装成客户端向服务器进行请求。
3. 服务器向“客户端”(实际上是Charles)返回服务器的CA证书。
4. Charles拦截服务器的响应,获取服务器证书公钥,然后自己制作一张证书,将服务器证书替换后 发送给客户端。(这一步,Charles**拿到了服务器证书的公钥)**
5. 客户端接收到服务器(实际上是Charles)的证书后,生成一个对称密钥,用Charles的公钥加密, 发送给服务器(实际是Charles)。
6. Charles拦截客户端的响应,用自己的私钥解密对称密钥,然后用服务器证书公钥加密,发送给服 务器。(这一步,Charles**拿到了对称密钥)**
7. 服务器用自己的私钥解密对称密钥,向客户端(实际是Charles)发送响应。
8. Charles拦截服务器的响应,替换成自己的证书后发送给客户端。
9. 至此,连接建立,Charles拿到了服务器证书的公钥和客户端与服务器协商的对称密钥,之后就可 以解密或者修改加密的报文了
主要流程如下:
1,客户端发请求
2,charles 接收再发送给服务端
3、服务端返回请求结果给charles
4、由charles转发给客户端
3、 抓包
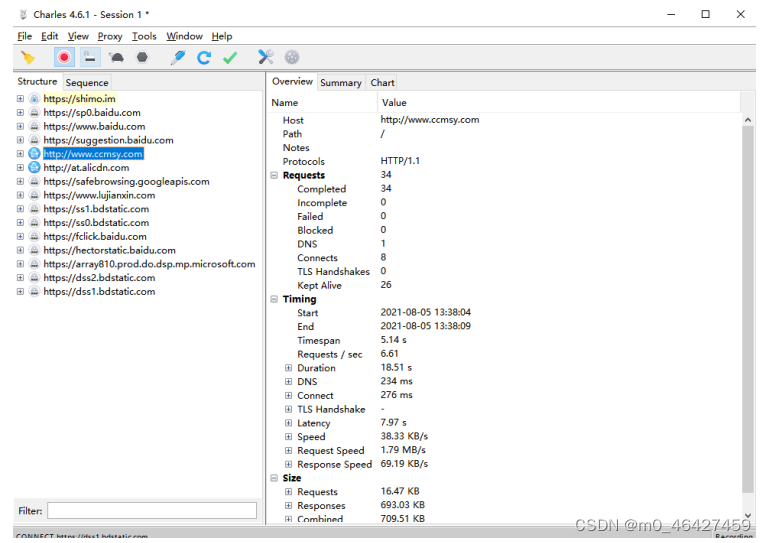
初始状态下 Charles 的运行界面如图所示:
4、PC端HTTPS配置
试用期间每天 30分钟
官方下载地址:https://www.charlesproxy.com/latest-release/download.do
破解方法:
打开charles,点击Help下面的register charles,输入对应的注册名和license
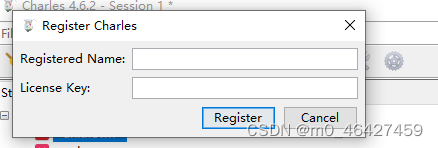
Registered Name:https://zhile.io
License Key: 48891cf209c6d32bf4
4.1 端口监听
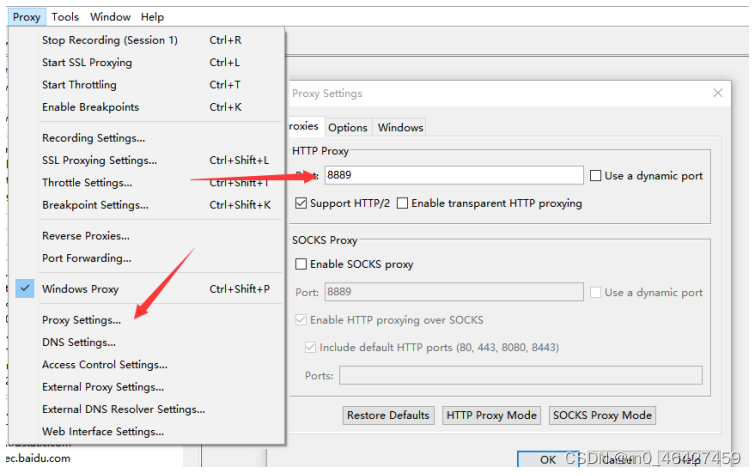
打开charles软件,在proxy 》 proxy Setting中,可以看到http的默认监听端口是8888,并且可以看到 在第三个页签中是windows窗口,用于监听当前windows系统的请求抓包,如下图:
可以将端口修改为8889
4.2 添加HTTPS端口监听
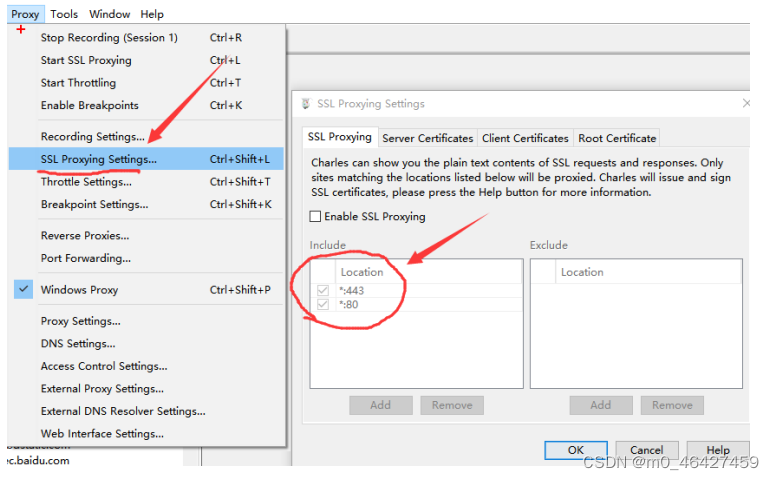
勾选Enable SSL Proxying,表示能抓取HTTPS的请求
4.3 配置服务端证书
由于Charles更改了证书,所以如果你是使用的Web浏览器,需要导入相应的Charles证书,否则校 验不通过会给出安全警告,必须安装Charles的证书后才能进行正常访问。不安装证书会导致打开charles没网,把Proxy ——》 Windows Proxy勾去掉
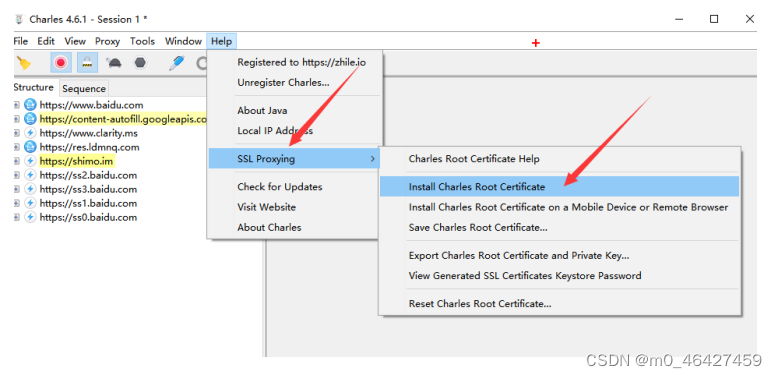
参考地址:https://www.jianshu.com/p/8346143aba53
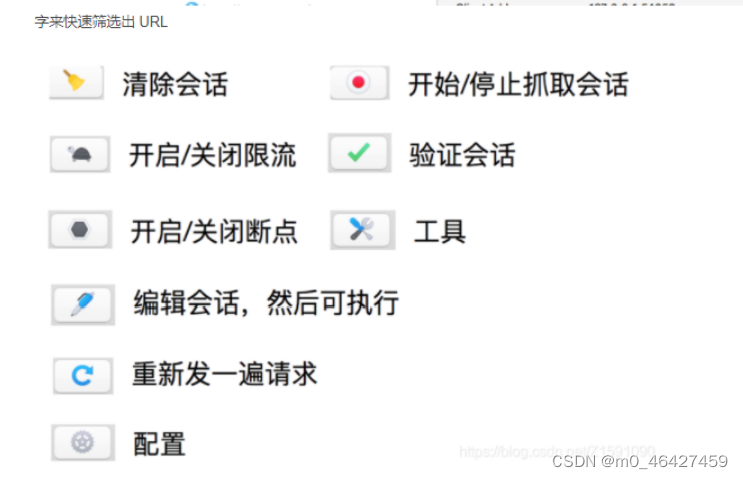
4.4 工具介绍
4.5 高级玩法
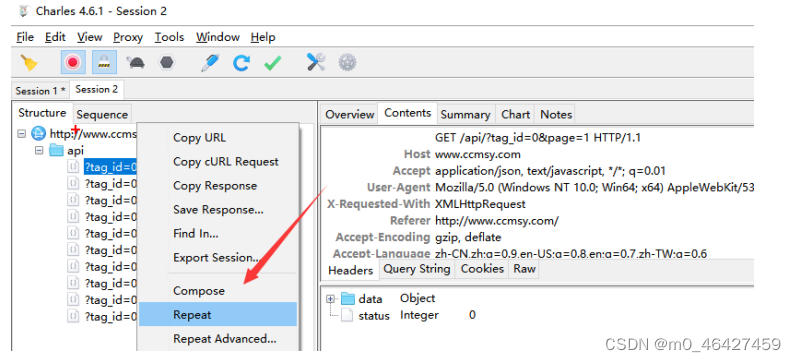
4.5.1 重放攻击
4.5.2 修改响应数据
案例: http://zb.yfb.qianlima.com/yfbsemsite/mesinfo/zbpglist
选择某个请求,邮件点击Breakpoint,然后重新刷新页面,此时页面会一直转圈,请求没发出去,此时再上面的栏中有breakpoint,找到对应的请求,就可以编辑请求参数请求头等内容了,点击execute才会向下继续执行。如果有Edit response就可以修改响应数据了。
4.5.3 文件替换
一般用在网站JS 比如无限debugger或者高度混淆代码替换
找到需要替换的文件,右键选择 Map Local
![]() 这个工具可以修改请求参数或者url从而重新发请求。
这个工具可以修改请求参数或者url从而重新发请求。
查看证书是否被代理
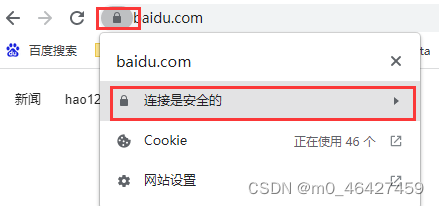
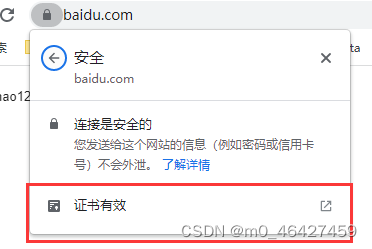
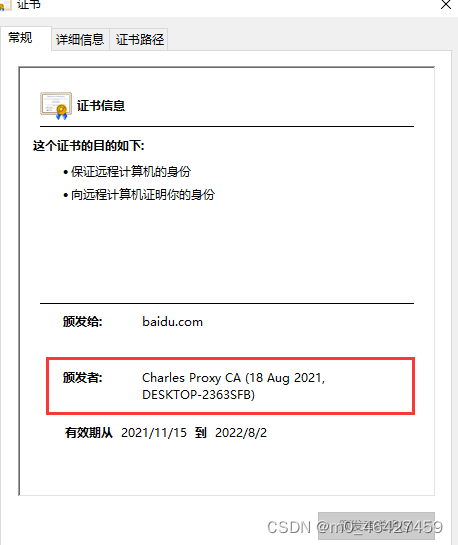
颁发者是charles说明已成功被charles代理。
5、安卓抓包
对APP进行调试,一般会使用adb调试(安卓的桥梁)。
模拟器地址:https://www.ldmnq.com/other/version-history-and-release-notes.html(官网中选择历史版本3.0)
可以安装模拟器,注意版本是安卓5往下
首先确保自己手机的wifi和电脑在同一网络下
使用模拟器进行抓取,先启动一个安卓5的模拟器,下载完雷神模拟器之后如下图所示:
首先新建一个模拟器,设置里面可以进行配置。
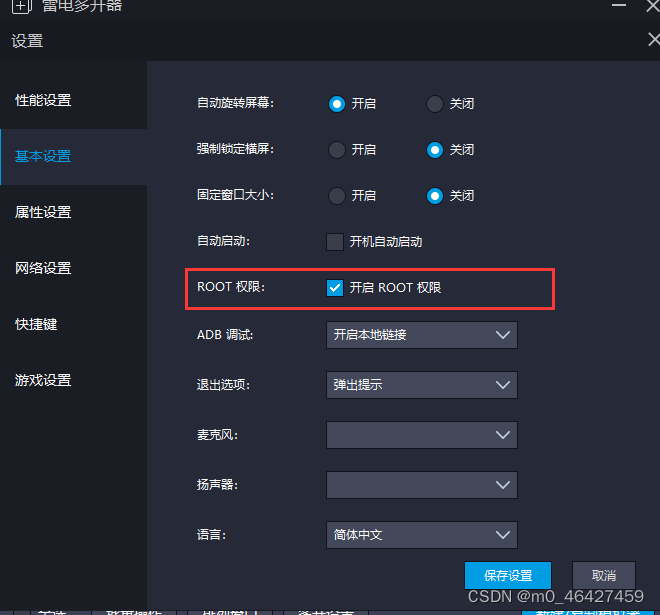
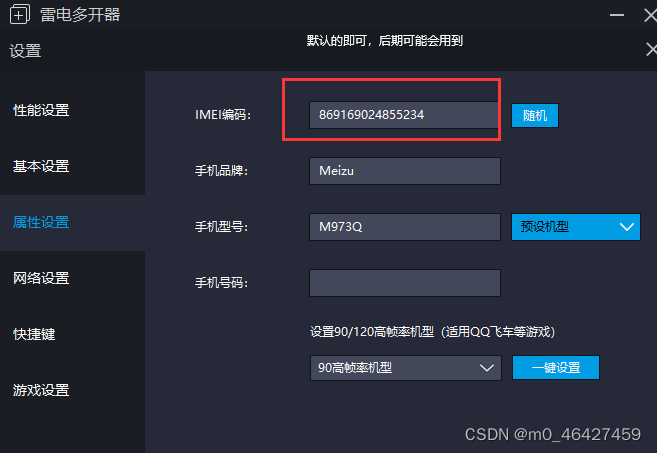
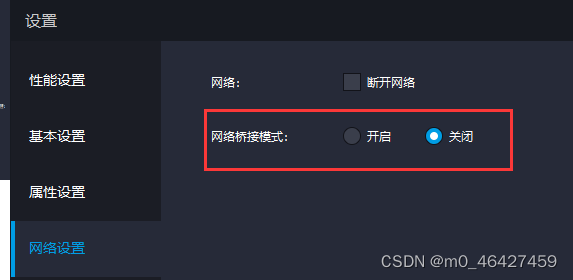
建议开启root,桥接模式
点击启动即可

开启后的界面如下:
charles中把window的抓包关闭,点击proxy中的window proxy即可。然后再模拟器中打开浏览器,查看抓包情况。
此时会发现charles抓包抓不到,因为模拟器还没配置IP等端口信息。
5.1 配置网络环境
让模拟器与window保持在同一个局域网。找对wlan,按住不动点击修改网络
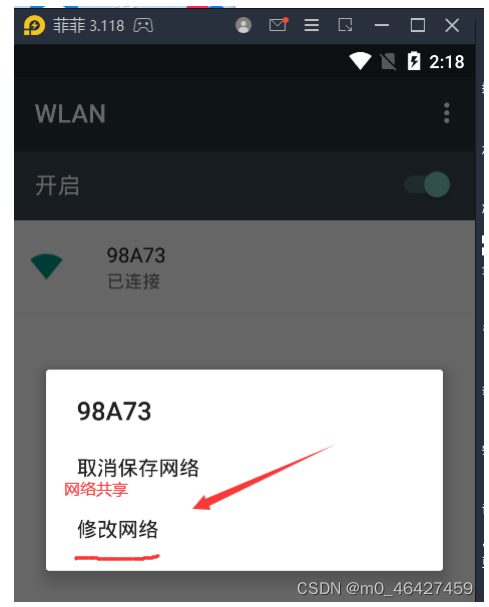
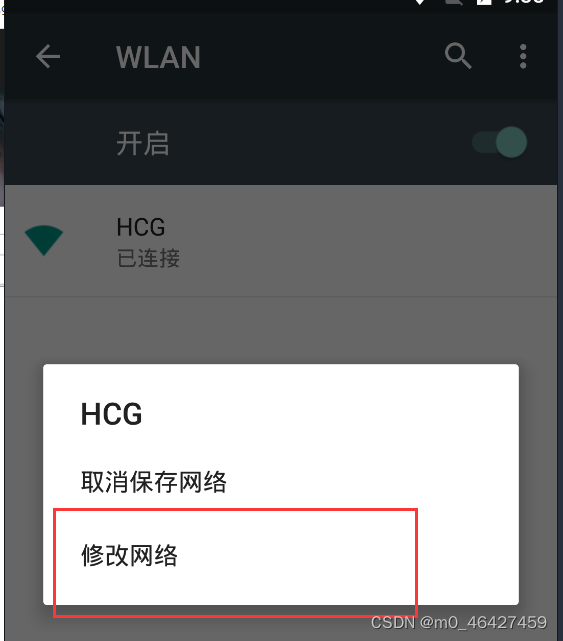
选择手动代理,代理服务器主机名即IP地址,可以在cmd的ipconfig查看,端口就是charles设置的端口,即proxy中的proxy setting中http proxy的端口。
保存后重新刷新模拟器的浏览器就可以看到了。
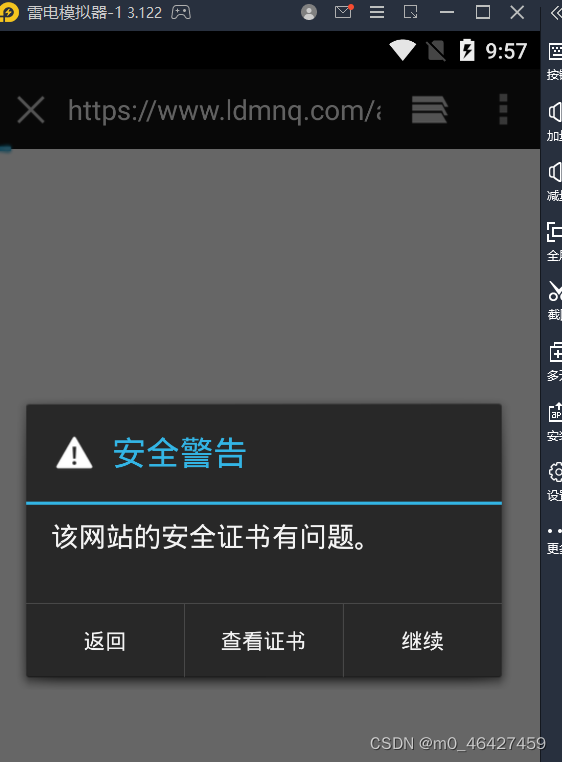
5.2 配置证书
代理设置好后,重新进入模拟器的浏览器,可能出现这个问题:
因此需要下载证书
5.2.1 下载证书
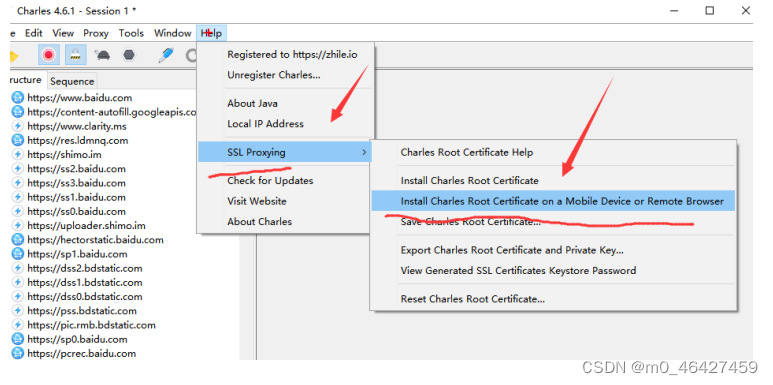 查询地址与IP 打开手机访问当前这个地址 chls.pro/ssl
查询地址与IP 打开手机访问当前这个地址 chls.pro/ssl
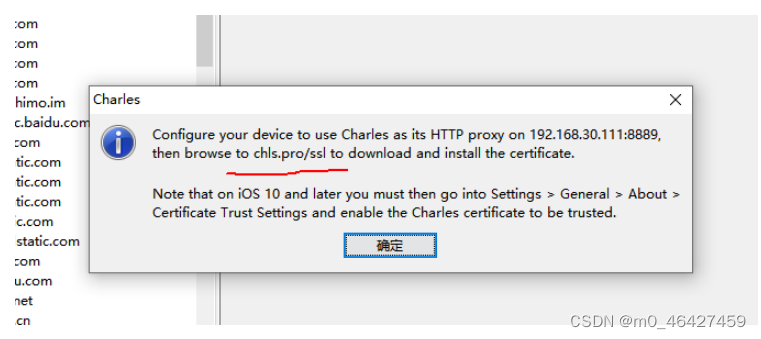
5.3 下载证书
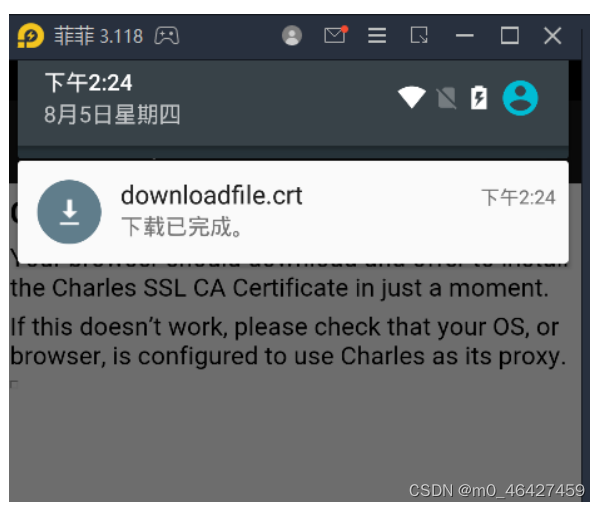
可能需要输入密码,选自己喜欢的就好
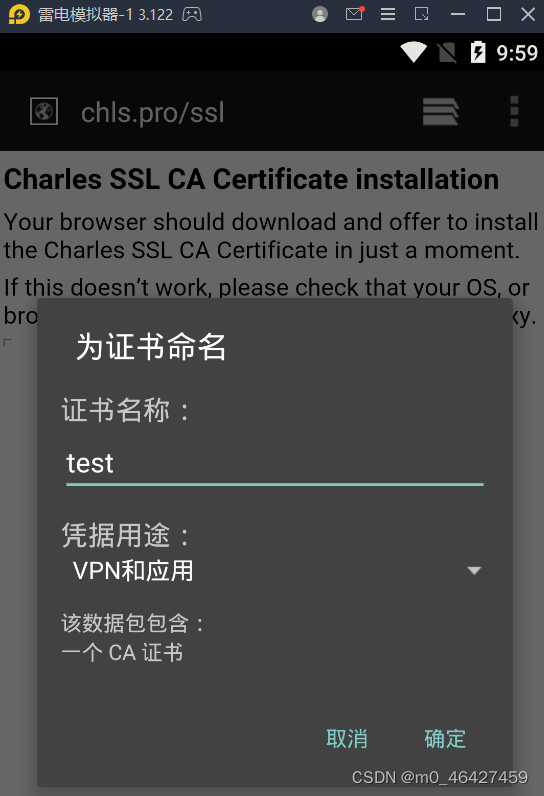
打开安装,填写证书名,设置PIN码
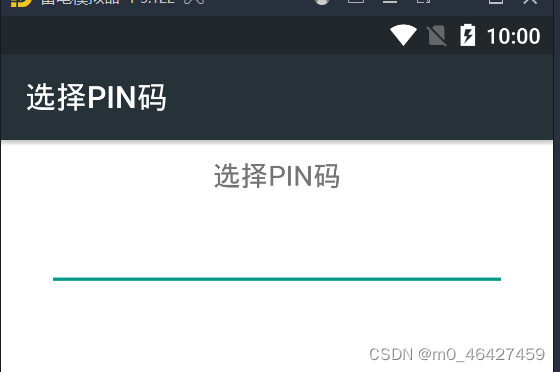
此时就可以正常访问了包括https协议也能访问,如果不安装只能访问http协议的网站。
5.4 安卓7抓包
下载APP软件包的站点:豌豆荚手机助手-海量安卓APP应用与游戏免费下载
安卓7以上,安卓系统默认不信任用户安装的外部证书,需要把SSL证书安装到安卓系统证书目录里,放成功后可以在系统凭证里面看到证书。但是我自己真机配置时系统路径是无法修改的。。就很尴尬。
安卓7模拟器,雷电版本需要4.0+
安卓5抓包,需要设置IP代理,很多APP不兼容
七层协议
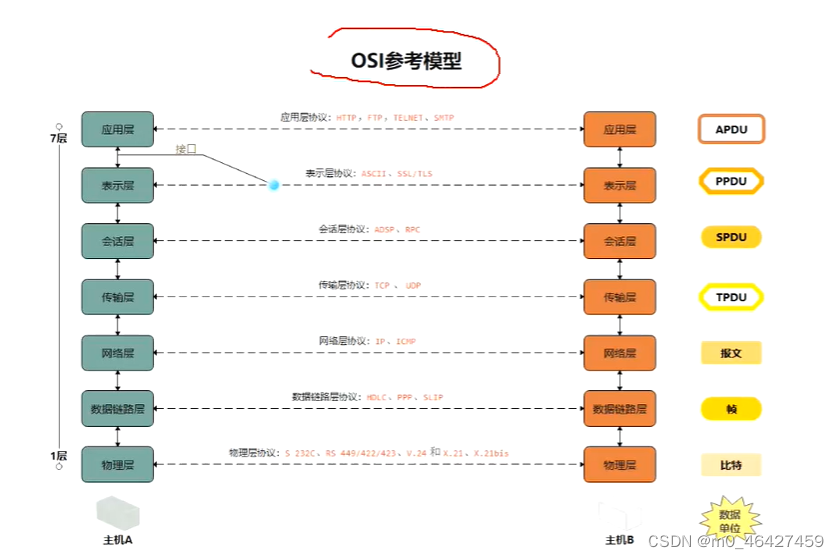
抓包工具正常抓的是会话层、表示层、应用层,手机如果开VPN代理可以抓网络层,并网上兼容抓包。
在window下使用adb连接到模拟器(要先下载adb)
adb devices # 查看可以连接的设备,第二个就是我们的模拟器
adb -s emulator-5556 shell # 连接设备

接下来将VPN软件postern安装到模拟器
adb -s emulator-5556 install ./Postern-3.0.10.apk

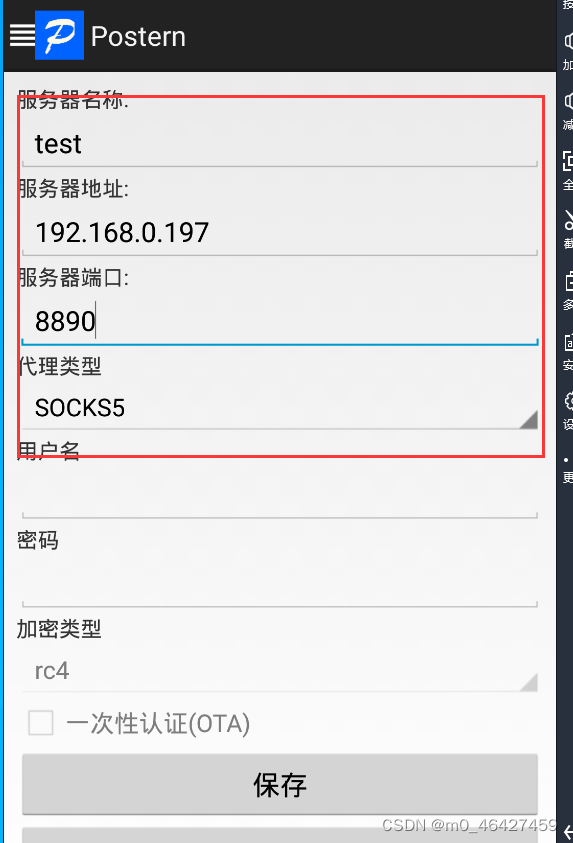
打开Postern配置代理
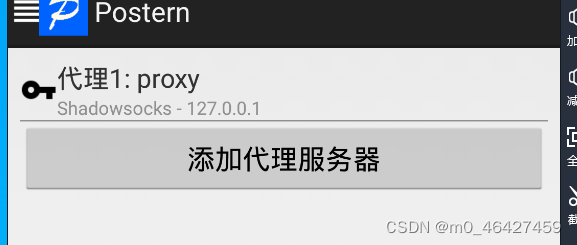 89
89
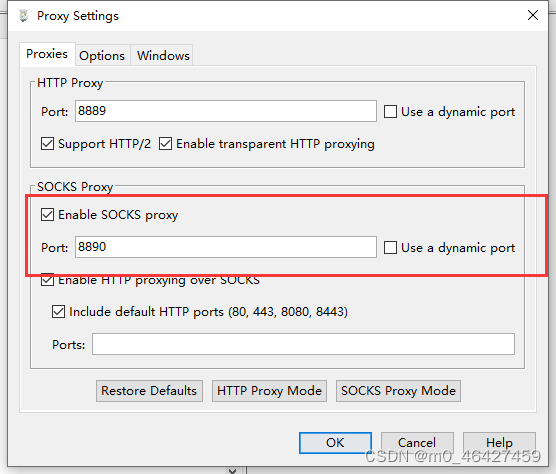
这里服务器地址就是window的ip地址,端口设置跟charles中一样,用socks5代理。
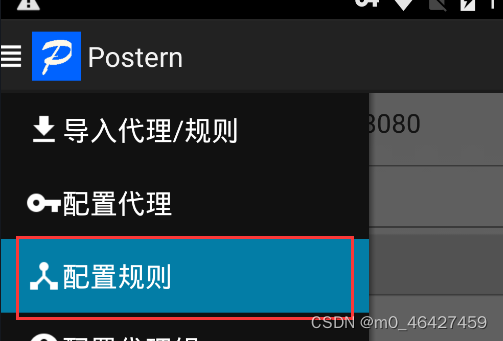
接下来继续添加规则:代理选择我们前面添加的test
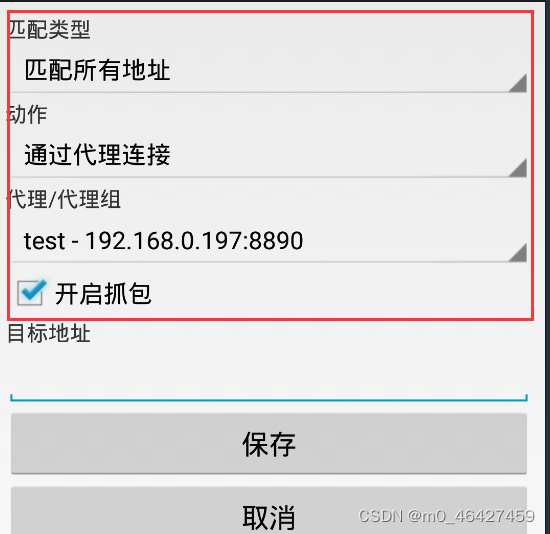
接下来关闭再打开VPN,此时界面会有这个图标,此时就可以通过VPN抓包

操作完成后可能会无法抓包。。。原因暂未解决
5.4.1 使⽤ vpn ⽅式抓包
运⾏在⽹络层,使⼿机的路由器/路由表改变
更加底层,意味着可以捕获更多的上层流量
5.4.2 安装证书
同⼀局域⽹下,通过系统配置 http 代理⽅式,浏览器访问 chls.pro/ssl ,安装证书到设备 搞定证书以后,此后就使⽤ postern 配置 charles 的 socks 模式代理的⽅式抓包了
信任证书
安卓5以后版本需要把证书放到系统目录,下载的证书就是cacerts-added这个文件夹,把整个文件夹移到cacerts下
/data/misc/user/0/cacerts-added/ -------> /system/etc/security/cacerts
5.4.3 abd安装
Android Debug Bridge(安卓调试桥) tools。它就是一个命令行窗口,用于通过电脑端与模拟器或者 是设备之间的交互。
ADB是一个C/S架构的应用程序
链接:https://pan.baidu.com/s/1SKu24yyShwg16lyIupO5VA 提取码:ih0i
安装完记得把路径配置到环境变量中的path,就可以使用了。
5.4.4 软件安装
adb -s 127.0.0.1:5555 install .\Postern-3.0.10.apk
5.5 抓app途居岛
先安装到模拟器中,有些app如抖音等,他们会有风控机制,检查是否为模拟器还是真机,模拟器是无法抓包的。
5.6使用真机抓包
配置证书、安卓5以后得把证书放到系统路径
在手机中装一个mt管理器,方便文件操作。
1、首先打开开发者模式(版本号点五下)、使用USB连接手机。接下来在系统-开发者模式-打开USB调试,并且不锁定屏幕。(USB配置要选择RNDIS)
接下来cmd中输入adb devices就可以查看到连接的手机
adb shell进入手机内部

2、使用真机进行抓包,得配置证书安卓5以后得把证书放到系统路径
看了一下我荣耀十是安卓4的,参考前面方式先安装证书,浏览器访问chls.pro/ssl,如果访问后没有弹出下载证书,应该配置手机的网络的代理服务器,可以参考charles中的help-setting proxy中的代理服务器和端口
安装完证书在设置-安全-更多安全设置/高级-加密与凭证-受信任的凭证。
3、配置Postern等一系列规则。搞完发现证书并没有安装到系统路径下,而且安装不进去,因为没有root权限。明天继续获取root权限
4、经过了几天的真机环境配置,最终以失败落幕。。。后面考虑用模拟器。
真机配置
比如安卓9系统
点击版本5下 打开手机开发者模式 勾选USB调试
adb 安装app到手机
adb install xxxx.apk
配置证书到系统目录
可以使用MT管理器
前提:打开浏览器访问 chls.pro/ssl 安装证书到用户目录
问题:
打开window系统 浏览器 下载charles证书
使用adb push 证书到手机 adb push <local> <remote>
手机 sdcard 路径下 /sdcard下
adb shell 可以进入手机内部
/data/misc/user/0/cacerts-added/ -------> /system/etc/security/cacerts
5.7 最后还是用模拟器抓包
现在高级别的android版本并不允许开root权限,可以考虑用app虚拟机VMOS pro,或者买谷歌的pixel3.
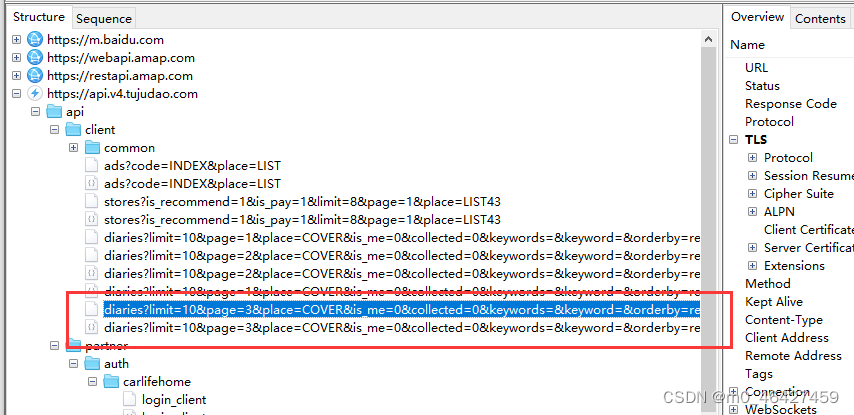
请求一下
Pycharm同时编辑多行:alt+shift+ctrl+鼠标左键
import requests
from loguru import logger
url = "https://api.v4.tujudao.com/api/client/diaries?limit=10&page=3&place=COVER&is_me=0&collected=0&keywords=&keyword=&orderby=read_num&created_member_id=&state=9"
def get_app_data():
res = requests.get(url)
if res.status_code == 200:
data = res.json().get('message').get('data')
for i in data:
item = dict()
item["mobile"] = i.get('member').get('mobile')
item["name"] = i.get('name')
item["city"] = i.get('city')
logger.info(item)
get_app_data()
微信小程序抓包需要删除一些系统文件
例如先打开一个小程序,接下来在任务管理器中找到这个进程

右键打开文件所在位置,会进到这个目录:C:\Users\Administrator\AppData\Roaming\Tencent\WeChat\XPlugin\Plugins\WMPFRuntime\4586\extracted\runtime
回到这个目录:C:\Users\Administrator\AppData\Roaming\Tencent\WeChat\XPlugin\Plugins\WMPFRuntime
将下面的所有文件删除


















 3712
3712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









