







哈希表
前言
首先来看数组,我们知道数组可以通过下标值拿到某个元素,这个操作是非常快的(O(1)),但是数组的插入和删除的效率并不是很高,删除数组的某个元素我们需要将被删除元素的后面的元素往前移,插入则需要将数组元素往后移,这种移动操作是效率并不是很好。
这时候可能就会想能不能有一种数据结构既能通过某个index值快速查找到某个元素(数组的功劳),又能让插入和删除效率非常高(链表的功劳),所以就引入了哈希表(散列表)这个数据结构
哈希表
定义
哈希表就是通过key值(键值)直接访问数据的数据结构。它会通过一个函数来计算这个key值,将所需要查找的数据映射到表中一个位置来进行访问记录,这加快了查找速度。这个映射函数叫做散列(哈希)函数,存放记录的数组称为散列表(哈希表)
哈希函数通常是将一个key值转换成一个数组范围内的下标,然后我们就可以将数据存放在数组对应下标的元素当中。常见的哈希函数有这几种:除法散列法 ,平方散列法 ,斐波那契(Fibonacci)散列法。这里介绍一下除法散列法:通常这个key值是一个字符串类型,我们可以将其转换成一个大数字,然后再将这个大数字对哈希表总长度取余得到一个 index,
HashTable.prototype.hashFunction = (str, size) => {
let hashCode = 0
for (let i = 0; i < str.length; i++) {
hashCode = 37 * hashCode + str.charCodeAt(i)
}
const index = hashCode % size
return index
}
我们把这个哈希函数记为f(key),key 经过 f(key)之后得到一个 index。下面我们来举一个例子:
我们将这个哈希函数表示为返回key的长度,即f(‘name’)返回4,f(‘school’)返回6,数组记为arr。
有如下几个数据,我们想把他们存放到哈希表中
key: 'name', value: 'user'
key: 'age', value: 100
经过哈希函数的处理,f(‘name’)得到index为4,f(‘age’)得到index为3,所以我们将第一条数据存放到arr[4]中,第二条存放到arr[3]中,这样确实没有任何问题,但是我们还想要存放这样的一条数据
key: 'sex', value: 'man'
经过计算,f(‘sex’)得到index为3,这时候发现有问题了,arr[3]已经有值了,这就发生冲突了,从而引起一个问题:哈希表到底是应该存放原来的值还是最新的值还是两个都存放?这时候我们就需要用到解决冲突的方法
冲突解决
什么是冲突?就是通过哈希函数将key值转换成数组index的时候出现重复的index,这种现象称为冲突
遇见冲突,我们就需要解决它,下面就来介绍解决哈希冲突的方法
-
链地址法
-
开放地址法
-
公共溢出区法
建立一个特殊存储空间,专门存放冲突的数据。此方法适用于数据和冲突比较少的情况
-
再哈希法
多个hash函数,第一个发生冲突了使用第二个,第二个发生冲突了使用第三个…
链地址法
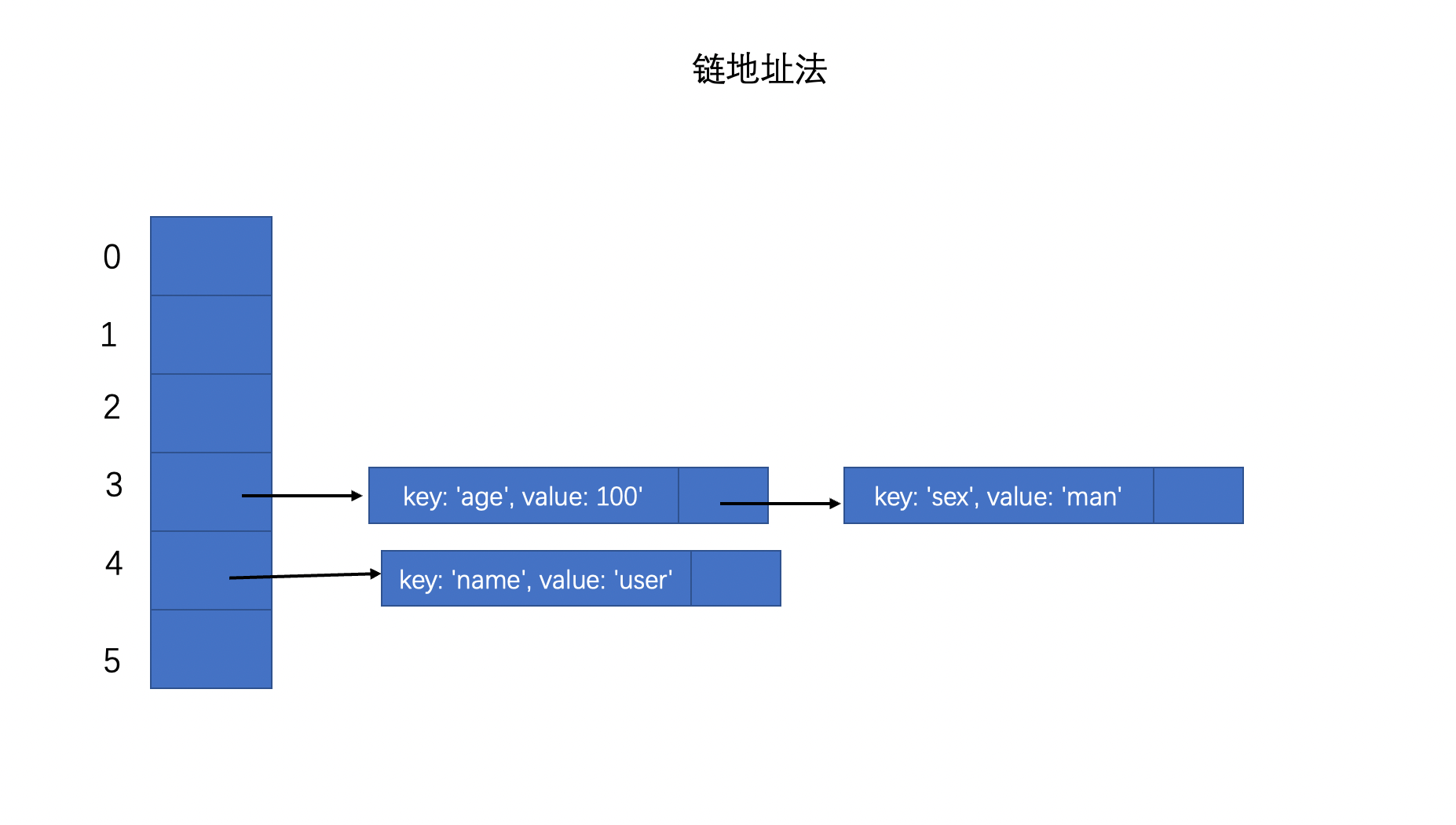
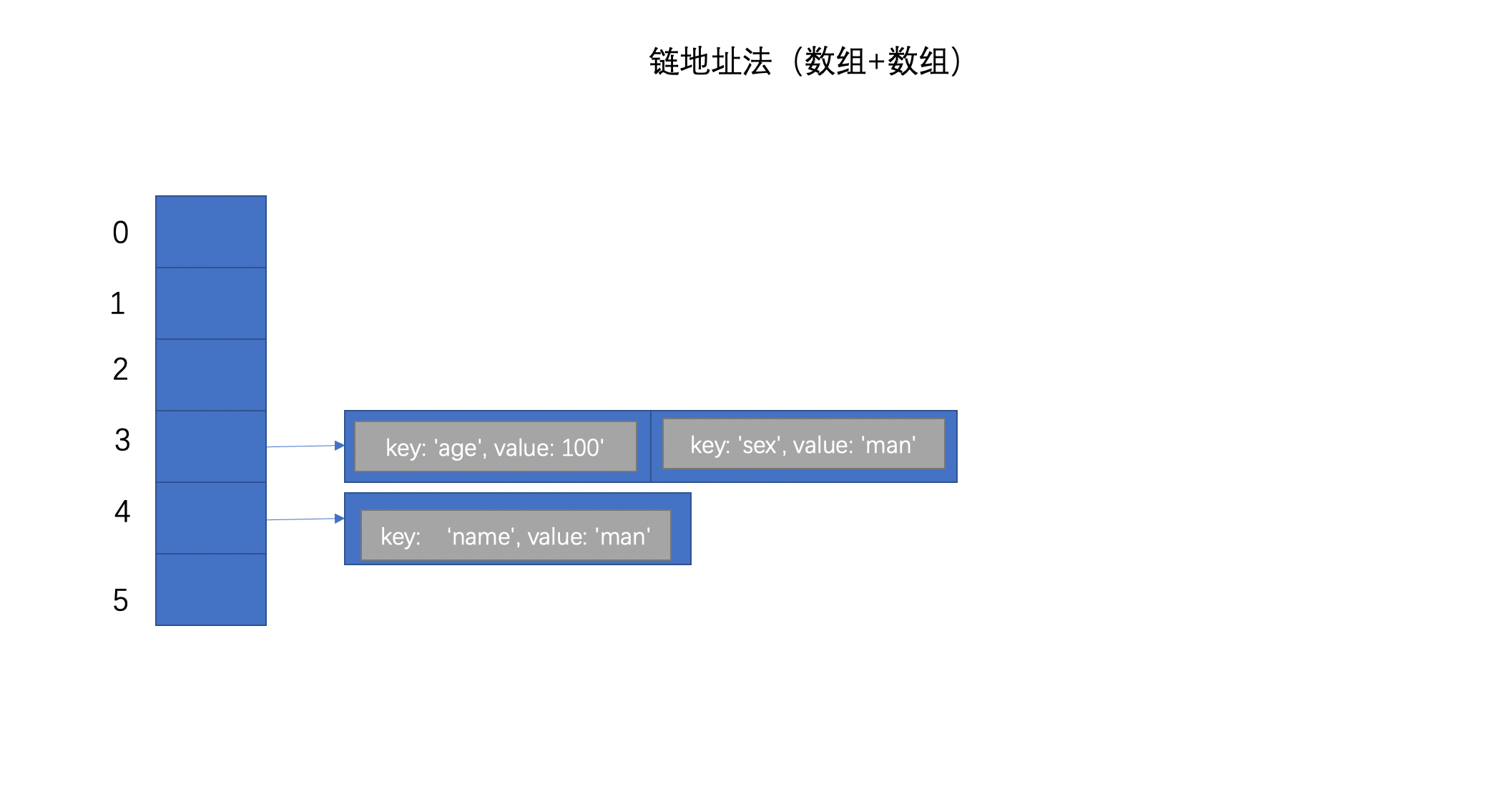
将重复的元素封装成一个链表/数组,也就是说数组每个index对应的元素不再是一个单独的元素而是一个链表/数组。
此时,数组的每个元素不再是一个单独的元素而变成了链表/数组。如果某个数据的key值经过哈希函数得到的index已经存在,首先通过这个index拿到index位置相应的链表/数组,然后将这个数据插入到链表/数组的末端或首端都可以,这样即保留了旧数据又添加了新数据。如果我们想要得到某个数据,首先通过哈希函数将key值转换成index,然后在通过这个index拿到相应的链表/数组,然后通过key值遍历链表拿到对应的数据,注意:key值不能重复
数组+链表
数组+数组
开放地址法
就是寻找数组中的空白位置,即没有数据的index位置,来存放冲突的数据。常见有线性探测和二次探测
线性探测
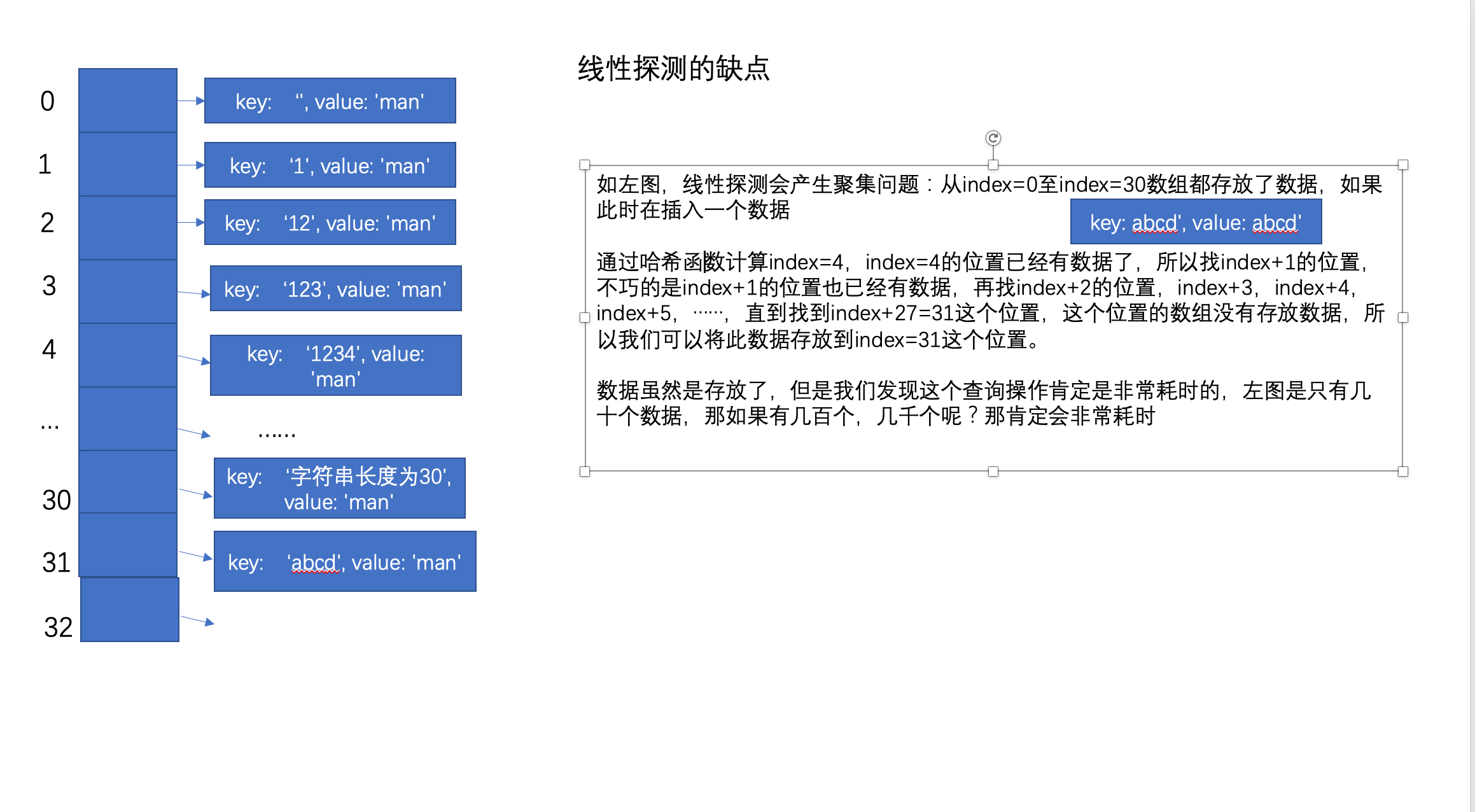
从当先index位置开始往后找,依次让index + 1,直到找到一个空白位置来存放这个数据

但是线性探测会产生聚集问题:如图从index=0至index=30数组都存放了数据,此时再插入一个数据
key: 'abcd', value: 'abcd'
通过哈希函数计算index=4,index=4的位置已经有数据了,所以找index+1的位置,不巧的是index+1的位置也已经有数据,再找index+2的位置,index+3,index+4,index+5,……,直到找到index+27=31这个位置,这个位置的数组没有存放数据,所以我们可以将此数据存放到index=31这个位置。
数据虽然是存放了,但是我们发现这个查询操作肯定是非常耗时的,左图是只有几十个数据,那如果有几百个,几千个呢?那肯定会非常耗时,所以为了解决这个问题,就有了二次探测
二次探测
二次探测其实和线性探测类似,只不过线性探测是每次步长 + 1,index +1,index +2,…;而二次探测是“先平方再相加”:index + 1^2,
index + 2^2, index + 3^2, …
通过二次探测增大了步长,降低了产生聚集问题的概率,但事实上二次探测还是会出现聚集问题,只不过相比于线性探测二次探测有了很大的改进
封装一个简单的哈希表
/*
封装哈希表,使用链地址法,哈希表每个元素存储的是数组/链表
本例采用数组:[[[key, value], [key1,value1],...],...]
*/
function HashTable() {
/**
* 数组,存放相关元素,这里面的每一个元素用用来存放一个链表或数组的
*/
this.storage = []
/**
* number,表示当前存放了多少条数据
*/
this.count = 0
/**
* number,哈希表的总长度
*/
this.limit = 10
/**
*
* @param {*} str 字符串
* @param {*} size 哈希表尺寸
* @returns 下标值
*/
HashTable.prototype.hashFunction = (str, size) => {
let hashCode = 0
for (let i = 0; i < str.length; i++) {
hashCode = 37 * hashCode + str.charCodeAt(i)
}
const index = hashCode % size
return index
}
// 添加或修改
HashTable.prototype.put = (key, value) => {
// 1. 获取下标值
const index = this.hashFunction(key, this.limit)
// 2. 拿到此下标值在哈希表中对应的链表或数组,这里用的是数组
let bucket = this.storage[index]
// 3. if bucket === undefined ----> add
if (bucket === undefined) {
bucket = []
this.storage[index] = bucket
// add
bucket.push([key, value])
return (this.count += 1)
}
// 3. if bucket !== undefined ----> add / update
for (let i = 0; i < bucket.length; i++) {
// update
const element = bucket[i]
if (element[0] === key) {
return (element[1] = value)
}
}
// add
bucket.push([key, value])
this.count += 1
// 填充因子:已有数据的总数 / 哈希表总数,只要填充因子大于 0.75 就扩容 x 2
if (this.count > this.limit * 0.75) {
const newLimit = this.getPrime(this.limit * 2)
this.resize(newLimit)
}
}
// 获取元素
HashTable.prototype.get = key => {
// 1. 获取下标值
const index = this.hashFunction(key, this.limit)
// 2. 拿到此下标值在哈希表中对应的链表或数组
const bucket = this.storage[index]
// null
if (bucket === undefined || bucket.length === 0) {
return null
}
// search
for (let i = 0; i < bucket.length; i++) {
const element = bucket[i]
if (key === element[0]) return element[1]
}
// not found
return null
}
// 删除元素
HashTable.prototype.remove = key => {
// 1. 获取下标值
const index = this.hashFunction(key, this.limit)
// 2. 拿到此下标值在哈希表中对应的链表或数组
const bucket = this.storage[index]
// fail
if (bucket === undefined || bucket.length === 0) {
return false
}
for (let i = 0; i < bucket.length; i++) {
const element = bucket[i]
// success
if (element[0] === key) {
bucket.splice(i, 1)
this.count -= 1
// // 填充因子:已有数据的总数 / 哈希表总数,只要填充因子小于 0.25 就减容 / 2
if (this.count < this.limit * 0.25 && this.limit > 7) {
const newLimit = this.getPrime(this.limit / 2)
this.resize(newLimit)
}
return true
}
}
// fail
return false
}
HashTable.prototype.isEmpty = () => this.count === 0
HashTable.prototype.size = () => this.count
// 哈希表扩容 / 减容
HashTable.prototype.resize = newLimit => {
const storage = this.storage
// 1. 重置所有属性,为了重新执行插入操作
this.storage = []
this.count = 0
this.limit = newLimit
// 2. 遍历前哈希表每个元素
for (let i = 0; i < storage.length; i++) {
const bucket = storage[i]
if (bucket === undefined || bucket.length === 0) continue
// 3. 插入,此时 this.limit已经为 新的limit了
for (let j = 0; j < bucket.length; j++) {
this.put(bucket[i][0], bucket[i][1])
}
}
}
// 用质数作为哈希表的容量,质数就可以更好的减少冲突,且让数据在哈希表分布均匀
HashTable.prototype.isPrime = num => {
const temp = parseInt(Math.sqrt(num))
for (let i = 2; i <= temp; i++) {
if (num % i === 0) return false
}
return true
}
// 获取最近质数
HashTable.prototype.getPrime = num => {
while (!this.isPrime(num)) {
num++
}
return num
}
}














 28万+
28万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









