







第十章 Keras人工神经网络简介
前言
通过前面九章的学习,我们完成了本书机器学习部分的所有内容,我们知道了如何选择一个机器学习模型、如何训练一个模型,以及参数的调优、特征的选择。
接下来我们将要学习人工智能另外一个重要的部分——神经网络。本章主要讲述了人工神经网络的起源、发展与应用。着重讲解人工神经网络是如何从最起初的一个感知器开始发展为如今庞大的神经网络体系,并运用基础的多层感知器为我们实现了分类与回归操作。最后讲解了神经网络基础的参数调整。
现在就让我们来一起看一下!
一、思维导图

二、主要内容
1、从生物神经元到人工神经元
- 生物神经元
早在1943年就已经有两位科学家提出了人工神经网络的概念,使用命题逻辑运算模仿神经元。但是在那之后由于各方面的问题神经网络经历了多次的寒冬,如今在大量数据、强大的硬件与资本大力支持的情况下,神经网络再次迎来新一轮的热潮,并且将会持续很长时间。 - 神经元的逻辑计算
与其他的所有生物仿制品一样,人工神经网络也在生物神经网络的基础上做了一些修改,它使用一个或者多个的二进制开关来模拟神经元的激活操作。由多个这样简易的神经元组合起来的网络就足以解决一些复杂的逻辑命题。 - 感知器
感知器是一个最简单的人工神经网络(ANN),他仅有一层逻辑单元(TLU)组成,每个输入与连接权重关联,输入加和之后再由阶跃函数输出结果,并且他的输出都是数字。
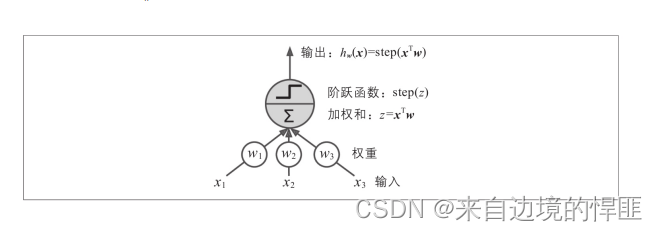
感知器通过新实例的预测误差来修改神经元连接的权重,其灵感也是有生物神经元而来,当一个神经元经常触发另外一个神经元时,两个神经元的连接权重就会增加。
全连接
当一层的神经元与上一层的神经元都连接时,这种情况称之为全连接。 - 多层感知器与反向传播
多层感知器
经过对感知器的研究我们发现,我们在解决一些非线性的复杂问题时,感知器将没有作用。这个时候我们就可以将多个感知器堆叠起来形成多层感知器(MLP),这样就能打破线性的局限。多层感知器是由多层阀值逻辑单元(成为隐藏层)与一个输出层组成。
前馈神经网络(FNN)
当所有的信号都是由一个方向流动,及从输入流向输出时,这样的神经网络称之前馈神经网络。
深度神经网络(DNN)
当一个多层感知器中包含多个隐藏层时,这样的神经网络称为深度神经网络。
反向转播
反向传播是一种用于训练多层感知器的算法,算法主要分为四个步骤:
1、随机生成整个神经网络的连接权重。
2、选取一部分训练集,像模型预测一样从输入传到输出,并保留每个连接的计算结果。
3、从输出层快开始使用链式法则计算每个连接对预测误差的贡献值,直到输入层。
4、使用刚刚计算出来的误差梯度来调整整个网络的连接权重。 - 回归MLP
多层感知器(MLP)可以用于回归任务,在构建回归多层感知器时,神经网络输入层的神经元数量有特征的数量决定,隐藏层的数量与隐藏层中神经元的数量由实际的问题决定。由于回归的输出并不是一个逻辑值,所以神经网络的输出可以不用激活函数,如果想要对结果的正负或者范围进行约束的话可以使用ReLU或是softplus激活函数。损失函数的选择与机器学习类似,使用均方误差或是与之类似的指标。 - 分类MLP
在使用多层感知器(MLP)处理分类问题时,输入层与隐藏层的数量与回归一样,但是输出层的激活函数就得使用逻辑激活函数。根据分类的类别问题来决定输出层神经元的多少与激活函数的种类。损失函数使用交叉熵。
2、使用Keras实现MLP
这部分内容会在文章最后的github中体现。
3、微调神经网络超参数
- 简介
我们可以像在机器学习中一样使用随机搜索或者是网络搜索的方式来调整神经网络的超参数。但是这种方式将会非常消耗时间并且效率很低。好消息是现在已经有很多的库可以用于神经网络的调参,这些库可以在很短的时间内得到一个很好的解决方案。 - 隐藏层数量
只有一个隐藏层的神经网络已经可以解决一些很复杂的问题,但是对于同一个问题多层的MLP总会比单层的MLP更有效率并且性能更好。总而言之,在面对复杂的问题时你可以通过添加隐藏层的数量来拟合训练集,直到模型过拟合于训练集为止。 - 隐藏层的神经元数量
神经元的数量与隐藏层是一个道理,你可以通过添加神经元的数量来拟合一些复杂的训练集,直到模型过拟合为止。一般情况下添加隐藏层的数量而不是添加神经元的数量会更加容易得到一个优秀的模型。 - 学习率、批量大小和其他超参数
其他的这超参数都是模型训练中不可缺少的,有的会影响模型的性能,有的会影响模型的训练程度。后面的章节中会介绍每一个参数的作用与调参方法。
三、课后练习
- 为什么通常最好使用逻辑回归分类器而不是经典的感知器(即使用感知器训练算法训练的单层阈值逻辑单元)?如何调整感知器以使其等同于逻辑回归分类器?
经典的感知器只有在数据集是线性可分的情况下才会收敛并且不能估计分类概率。相反逻辑回归分类器在数据集不是线性可以分的情况下也可以收敛兵器可以输出分类的概率。
如果你把多层感知器的激活函数换为逻辑激活函数,然后使用梯度下降训练它,那么这个感知器就等同于逻辑回归分类。 - 为什么逻辑激活函数是训练第一个MLP的关键要素?
因为逻辑激活函数的导数永远都是非零的,所以梯度下降是可以连续的。当激活函数是一个阶梯函数时,逐渐下降就不会连续,因为没有斜率。 - 列举三种常用的激活函数。你能画出来吗?
常用的激活函数有:阶跃函数,逻辑函数,双曲正切函数,线性整流函数。 - 如果要将电子邮件分类为垃圾邮件或正常邮件,你需要在输出层中有多少个神经元?你应该在输出层中使用什么激活函数?相反如果你想解决MNIST,则在输出层中需要多少个神经元,应该使用哪种激活函数?如第2章所述,如何使你的网络预测房价?
如果将电子邮件分类为正常邮件与垃圾邮件那么你的输出层有一个神经元,在估算概率时通常会在输出层使用逻辑激活函数。如果想要解决MNIST问题,那么输出层需要十个神经元应该使用softmax函数替换逻辑激活函数。如果想要预测房价,那么只需要一个输出神经元,输出层也不需要任何的激活函数。 - 什么是反向传播,它如何工作?反向传播和反向模式的autodiff有什么区别?
反向传播是一种用于训练人工神经网络的技术。它首先计算关于每个模型参数的成本函数的梯度,然后使用这些梯度执行梯度下降。这种反向传播模式一般会执行很多次,并且需要多个训练批次,知道模型参数收敛到最小化成本函数的值为止。反向模式会先正向执行一次,计算每个节点的值,然后再反向计算一次,一次性计算所有梯度。反向传播是指多次使用反向模式来训练人工神经网络的全部过程,而反向模式只是一种技术。 - 你能否列出可以在基本MLP中进行调整的所有超参数?如果MLP过拟合训练数据,你如何调整这些超参数来解决问题?
在基本的MLP中可以调整的超参数有:隐藏层的数量,隐藏层中神经元的数量,隐藏层与输出层的激活函数。如果MLP过拟合于训练集了,会尝试减少隐藏层的数量或者是减少隐藏层中的神经元数量。
四、总结
这是机器学习第十章的全部内容,主要就是初步介绍了什么是神经网络,神经网络的发展已经神经网络的简单应用。总结下来就是:
- 神经网络的概念在1943年就已经有人提出,简单的神经网络建立在生物神经网络的基础上发来开来,在经历了多次的寒冬之后再如今天时地利人和的情况下再次迎来热潮。
- 感知器是一个最简单的神经网络,已经给足以解决一些复杂的逻辑问题。但是在面临一些更加复杂的非线性问题是,只能通过添加感知器的层数来突破局限,也就形成了多层感知器(MLP)。
- 多层感知器的训练使用反向传播技术,来计算神经网络中神经元与神经元的权重。
- 神经网络中有很多超参数可以调节,并且目前已经提供了很多的库可以用于调整神经网络的超参数,在很短的时间内可以得到很好的模型。
对文章有任何疑惑或者想要和博主一起学机器学习一起进步的朋友们可以添加 群号:666980220。需要机器学习实战电子版或是思维导图的也可以联系我。祝你好运!
项目地址: github















 389
389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









