







第十九章 大规模训练和部署TensorFlow模型
文章目录
前言
这一章是这本书的最后一章,最后的我们学习的是整个机器学习中不可获取的一部分:模型的部署与一些加速训练的方法。当我们已经拥有了完美的模型的时,想到的第一件事就是将模型部署到生产环境中发挥他的能力。正常情况想我们会像开发模型是那样,调用predict()来完成模型的预测,其实这并不是最好的选择。我们在训练模型的时候也会遇到由于模型规模很大,需要处理的数据庞大的问题,面对这些我们都有很好的解决办法,下面就让我们一起来看一下吧。
一、主要内容
1、为TensorFlow模型提供服务
-
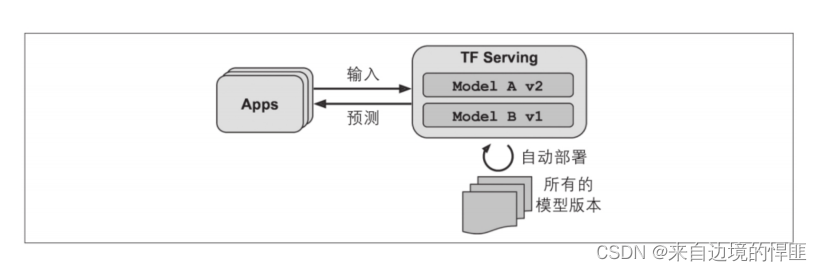
使用TensorFlow Serving
在我们使用TF Serving来部署我们的模型之后,我们就不需要在开发时预测的一样调用predict()方法来完成模型的预测,只需要将模型导出为SaveModel格式,然后将导出的模型放入指定的目录下就可以使用调用API的方式完成预测。使用API调用模型的方式有两种,一种是使用REST API调用,还有一种是为了适应传输过程中也别占用带宽的情况使用gRPC API。
线上的模型部署还需要考虑到版本的问题,我们升级版本时只需要在指定的目录下创建一个新的文件夹将模型放在里面,版本回滚时只需删除新版本的文件即可。
-
在GCP AI平台上创建预测服务
模型部署还有一种情况是线上部署,我们可以在一些例如GCP AI云平台上部署我们的模型,部署的步骤与本地部署大同小异只是多了一些平台账号注册之类的工作,还有就是正对不同的平台有不同的平台使用的规则。
虽然是使用了云平台上部署,不过云平台上同样是在服务器上启动了TF Serving,所以理论上同样是可以使用本地部署调用的方式来调用API,但是建议还是使用云平台提供的库来调用预测服务。
2、将模型部署到移动端或者嵌入式设备
有的时候我们需要将训练好的模型部署到移动端或者是一些自动化的嵌入式设备上。这时我们需要考虑几个问题:
- 减少模型尺寸,缩短下载的时间并减少RAM使用量。
- 减少每个预测所需的计算以减少延时、电池使用量和发热量。
- 使模型适应特定设备的约束。
以上这些问题我们可以使用TFLite库来解决。
还有一种情况是我们需要将模型部署在WEB前端,那么我们可以使用TensorFlow.js来完成模型的预测。
3、使用GPU加速运算86
-
简介
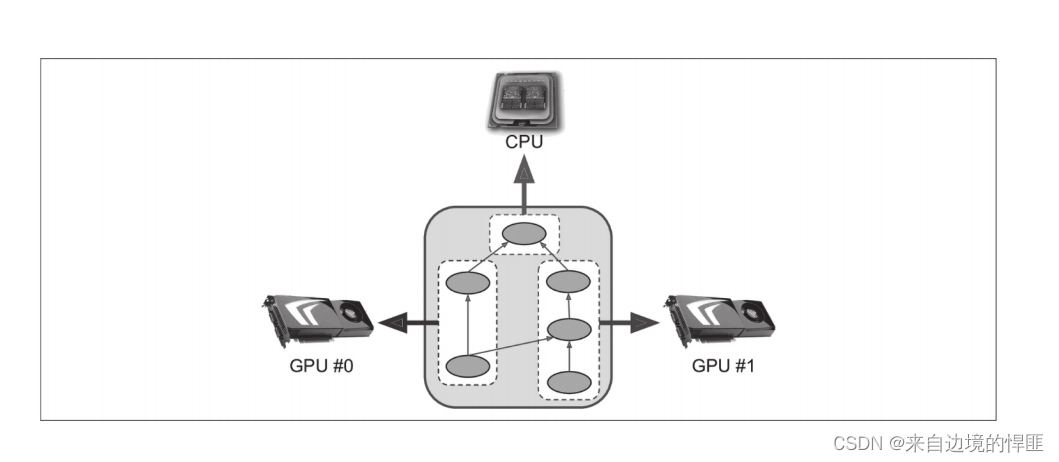
一般情况我们不会单纯的使用CPU来训练模型,当涉及到很大的计算量时,更推荐使用GPU来训练模型。我们可以通过直接购买物理GPU或者是虚拟GPU的方式来获得。物理GPU的使用要比虚拟GPU相对复杂,首先我们需要购买模式框架支持的GPU然后需要在本机上下载对应GPU的驱动。
-
管理GPU内存
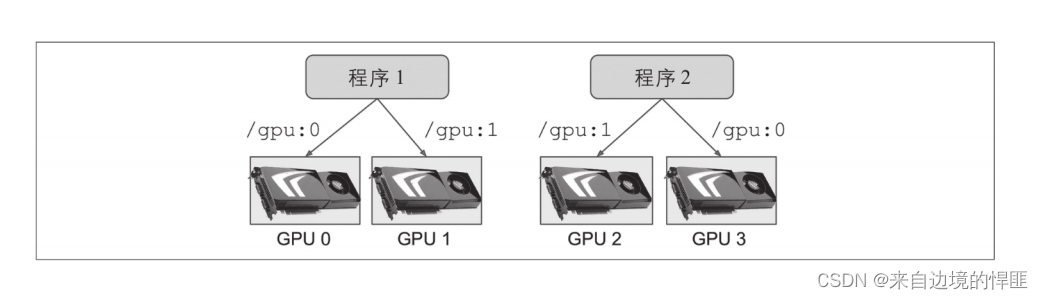
由于TensorFlow在第一次运行计算的时候会获取所有GPU中可用的RAM,所以在你启动第二个TensorFlow程序时就会出现内存占满的情况。当我们需要在一台服务器上启动多个TensorFlow服务时就需要管理GPU的内存,可以使用一个GPU对应一个TensorFlow程序的方式,如果只有一个GPU也可以将一个GPU分为多个虚拟GPU然后一一对应。
-
在设备上放置操作和变量
我们在正常使用TensorFlow训练一个模型或者是使用模型预测时,tf.data和tf.keras通常可以很好的将操作和变量放在他们所属的位置上,但是如果你需要也可以在每个设备上手动方式操作和变量。 -
跨多个设备并行执行
我们可以通过修改TensorFlow的默认配置来完成同一个任务在多台设备上并行执行。
4、跨多个设备的训练模型
-
模型并行
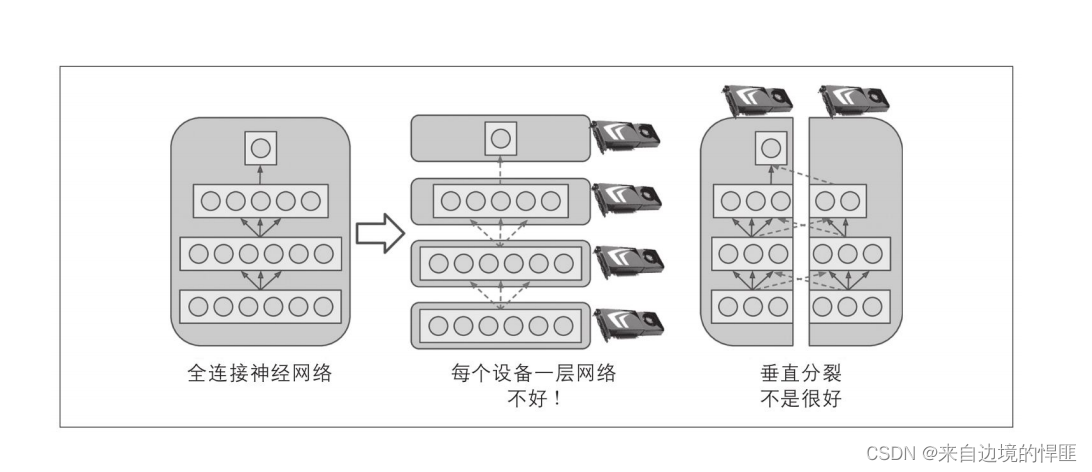
模型并行是跨多设备训练的模型的一种方式,简单来说就是将一个模型分为多个部分分别放到不同的设备上训练。从理论上来看,确实可以加快训练速度提高训练的效率。但是当我们把神经网络一层层拆开之后会发现,即使我们已经实现了每层的分开训练,后一层的训练依旧需要依赖上一层的训练结果,所以使用模型并行的方式来加快训练的速度是一种并不完美的方法。
-
数据并行
数据并行的中心思想是把需要训练的模型在每个设备上都复制一份,并且每个模型训练的步骤都是相同的,只是每个模型所训练的数据是不同的。这是一种目前常用的方法,不过使用这个方法有一个需要克服的问题,在每一个批次训练完成之后需要同步更新每个设备上的模型,更新的方式就是取所有的模型参数的平均值组成新的参数,同步到所有的模型中。
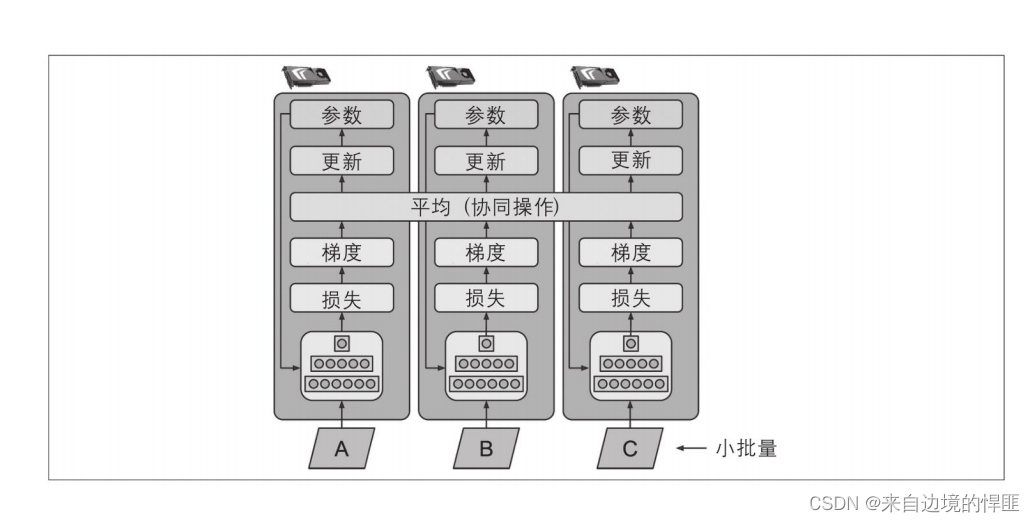
-
使用分布式策略API进行大规模训练
当我们需要在同一台服务器上不同GPU上甚至是不同服务器的不同GPU上训练模型时,这个过程相当繁琐,所以并不建议由我们自己来完成,而是调用TensorFlow附带的用于分布式策略的API来完成。 -
在TensorFlow集群上训练模型
TensorFlow集群是一组并行运行的TensorFlow进程,通常在不同的机器上运行并且互相通讯以完成一些工作。当我们使用这个集群时,需要通过配合环境变量,针对集群中的每个个体需要完成的工作以及他们的代号、角色。
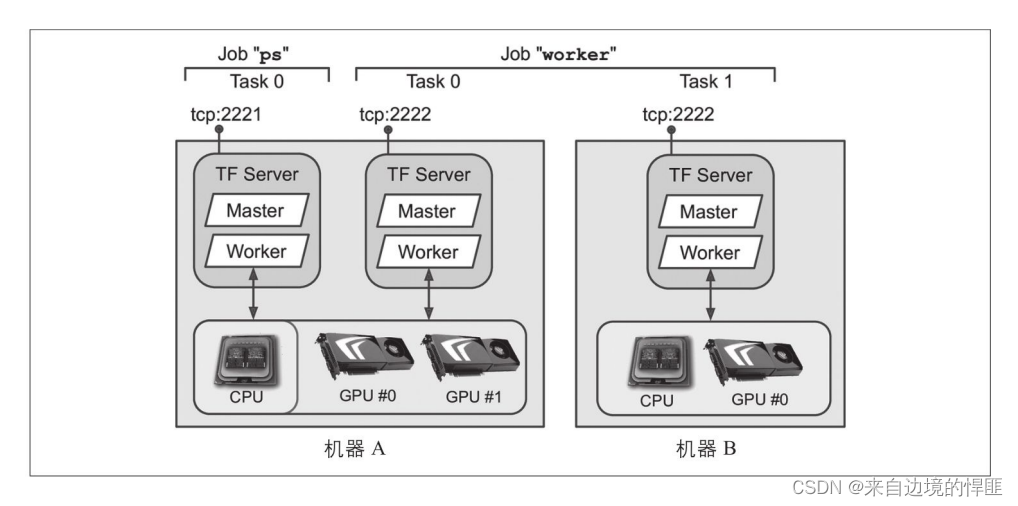
-
在Goolg Cloud AI平台上运行大型训练作业
在线上平台完成训练就相对比较简单,你只需要使用在本地集群中使用的相同代码部署到线上即可。平台会尽可能的满足你所需要的所有配置。 -
AI平台上的黑箱超参数调整
我门还可以在AI 平台上对YAML文件的配置进行调整就可以完成一些模型的超参数调整功能。
二、课后练习
-
SavedModel包含什么?如何检查其内容?
SavedModel包含一个TensorFlow模型,包括其架构(计算图)及其权重。它保存在一个目录中,该目录包含一个save_model.pb文件和一个variables子目录——该文件定义了计算图(表示为序列化的协议缓冲区),该子目录包含变量值。对于包含大量权重的模型,可以将这些变量值拆分为多个文件。SavedModel还包括assets子目录,该子目录可能包含其他数据,例如词汇表文件、类名或该模型的某些实例。准确地说,SavedModel可以包含一个或多个元图。元图是一个计算图,外加一些函数签名定义(包括它们的输入名称输出名称、类型和形状)。每个元数据由一组标签来标识。要查看SavedModel,你可以使用命令行工具save_model_cli或使用tf.saved_model.load()来加载它并在Python中对其进行查看。 -
何时应使用TF Serving?它的主要特点是什么?可以使用哪些工具进行部署?
TF Serving允许你部署多个TensorFlow模型(或同一模型的多个版本),使其可以通过REST API或gRPC API轻松地被所有应用程序访问。直接在你的应用程序中使用模型会使在所有应用程序中部署模型的新版本变得更加困难。实现你自己的微服务来包装TF模型需要额外的工作,并且很难匹配TF Serving的特性。TF Serving具有许多特性:它可以监视目录并自动部署放置在其中的模型,并且你不必更改甚至重新启动任何应用程序就可以从新的模型版本中受益。它的速度很快、很好测试并且扩展性非常好。它支持对实验模型进行A/B测试,并仅向部分用户部署新的模型版本(在这种情况下,该模型称为金丝雀)。TF Serving还能够将单个请求分组,可以使它们在GPU上一起运行。要部署TF Serving,你可以从源代码安装它,但是使用Docker映像安装要简单得多。要部署TF Serving Docker映像集群,你可以使用编排工具(例如Kubernetes)也可以使用完全托管的解决方案(例如Google Cloud AI平台)。 -
如何跨多个TF Serving实例部署一个模型?
要跨多个TF Serving实例来部署模型,你需要做的就是配置这些TF Serving实例来监视相同的models目录,然后将新模型作为SavedModel导出到子目录中。 -
什么时候应该使用gRPC API而不是REST API来查询一个被TF Serving服务的模型?
gRPC API比REST API更有效。但是,它的客户端库不那么广泛,如果在使用REST API时使用压缩,则你可以获得几乎相同的性能。因此,当你需要尽可能高的性能并且客户端不仅限于REST API时,gRPCAPI最为有用。 -
TFLite减少模型大小以使其在移动端或嵌入式设备上运行的不同方式是什么?
为了减小模型的大小,使其可以在移动端或嵌入式设备上运行,TFLite使用了以下几种技术:
·它提供了一个可以优化SavedModel的转换器:它可以缩小模型并减少其延迟。为此,它修剪进行预测不需要的所有操作(例如训练操作),并在可能的情况下优化和融合操作。
·转换器还可以执行训练后的量化:该技术极大地减小了模型大小,因此下载和存储速度更快。
·它使用FlatBuffer格式来保存优化的模型,该格式可以直接加载到RAM中,而无须进行解析。这样可以减少加载时间和占用的内存。 -
什么是量化意识训练,为什么你需要它?
有量化意识的训练包括在训练过程中向模型添加伪造的量化操作。这使模型能够学会忽略量化噪声。最终的权重会对量化更加稳健。 -
什么是模型并行和数据并行?为什么通常建议使用后者?
模型并行化意味着将模型分成多个部分,在多个设备上并行运行它们,希望在训练或推理期间加快模型的运行速度。数据并行化意味着创建模型的多个精确副本,并将其部署在多个设备上。在训练过程中的每次迭代中,每个副本会获得不同批次的数据,并且它会根据模型参数来计算损失的梯度。在同步数据并行处理中,汇总所有副本的梯度,然后优化器执行“梯度下降”步骤。可以将参数集中(例如,在参数服务器上),或者在所有副本之间复制参数,并使用AllReduce使其保持同步。在异步数据并行处理中,参数是集中的,副本彼此独立运行,每个副本都在每次训练迭代结束时直接更新中心参数,而不必等待其他副本。为了加快训练速度,通常来说,数据并行性要比模型并行性更好。这主要是因为它需要较少的跨设备通信。此外,它更容易实现,并且对任何模型都以相同的方式工作,而模型并行性则需要分析模型来确定将其分成模块的最佳方法。 -
在多台服务器上训练模型时,可以使用什么分布式策略?如何选择使用哪一个?
在跨多台服务器上训练模型时,可以使用以下分配策略:
·MultiWorkerMirroredStrategy并行执行镜像的数据。该模型在所有可用的服务器和设备上复制,每个副本在每次训练迭代时获取不同
批次的数据,并计算其自己的梯度。使用分布式AllReduce实现(默认情况下为NCCL)来计算并在所有副本之间共享梯度的平均值,所有副本都执行相同的梯度下降步骤。由于所有服务器和设备的处理方式都完全相同,因此该策略使用起来最简单,性能良好。通常,你应该使用此策略。它的主要局限是它要求模型适合每个副本中的RAM。
·ParameterServerStrategy执行异步数据并行。该模型在所有工人上的所有设备上复制,并且参数在所有参数服务器上分片。每个工人都有自己的训练循环,与其他工人异步运行。在每次训练迭代中,每个工人都会获取自己的数据批次,从参数服务器中获取模型参数的最新版本,然后针对这些参数计算损失的梯度,将其发送到参数服务器。最后,参数服务器使用这些梯度执行“梯度下降”步骤。此策略通常比以前的策略慢,而且部署起来有点困难,因为它需要管理参数服务器。但是,训练不适合GPU RAM的大型模型很有用。
三、总结
以上就是本章的所有内容,介绍了我们如何使用TensorFlow来完成模型的部署与分布式训练,依旧总结一下:
- 我们可以使用TF Serving来完成模型的部署与版本迭代。
- 调用模型预测我们不必像开发时一样调用方法来完成预测,可以使用调用API的方式来完成模型的预测。
- 训练模型是我们一般不直接使用CPU来训练,而是使用GPU。当我们需要处理的问题很复杂使用分部署的方式来训练模型,同时要完成GPU内存的管理。
- 我们在使用分部署的方式训练模型不建议由自己来完成一整个过程,而是建议调用TensorFlow的库来完成。
至此,整本机器学实战的内容我们已经讲解完成了,很多的东西并没有深入的推导每一个公式,解释每一个过程,算是起到了一个抛砖引玉的作用,如果你对文章中的某个部分很感兴趣,那么可以去阅读相关的书籍或是文献。同时我也相信所有的文章内容总会有不足的地方,也请大家多多包涵,我也会在今后的日子里不断丰富自己来弥补自己不足的地方,给大家带来更多更精彩的文章。谢谢大家的支持。还是那句话祝你好运,祝我们都好运!
项目地址: 码云地址















 3489
3489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









