







这个系列是对CUDA并行计算课程的复习回顾,主要用作个人复习之用,难免有很多疏漏之处,错误的地方请在评论区指出,谢谢。
教材:Programming Massively Parallel Processors A Hands-On Approach 第3版
课程参照:伊利诺伊大学ECE408
下方是胡文美教授讲授ECE408的配套资源网页:
Home Page![]() http://gputeachingkit.hwu.crhc.illinois.edu/
http://gputeachingkit.hwu.crhc.illinois.edu/
目录
1. 例子1:向量加法-续
上节我们已经讲到了向量加法的一个简单例子,给出了向量加法的Host端代码,这里我将继续讲解向量加法的例子。首先给出向量加法的Device端代码:
__global__ void vecAddKernel(float* A,float* B,float* C,int n)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if(i<n)
C[i] = A[i] + B[i];
}这一个函数即对应的是上一节我们给出的Host端代码中核函数部分,也就是真正由GPU执行的部分,在Host端代码中的位置如下图所示,它将在Host端被调用:

下面我们来分析一下这个简短的代码:
1.1 函数声明
首先我们可以观察到函数声明前有一个特别的__global__,表示这个函数是核函数,是在GPU上执行的。
简单介绍一下CUDA的函数声明:

__global__即表示当前的函数是在Device(GPU)端执行的核函数,它将在Host(CPU)端被调用,就像我们举的向量加法这个例子中的应用一样。
需要注意的是:
- __global__中的“__”实际上包含两根下划线
- 使用__global__声明的核函数必须返回的是void类型,也就是不需要有返回值
以上三种CUDA的函数声明,最常使用的就是__global__,其余的以后遇到再讲。
1.2 线程索引
int i = blockIdx.x * blockDim.x + threadIdx.x;这一行代码的作用是确定线程的索引。作为初学者,肯定会在这一步有疑问,为什么要做一个线程索引这个事情呢?我将尽量以通俗易懂的方式讲解这个问题:
首先,我们再次回顾上节讲到的一句很重要的话:
一个grid可以包含多个block,一个block可以包含多个thread。
我们需要知道,一个grid中的所有CUDA线程(thread)执行同一个核函数(kernel function)。那么我们要如何区分这些thread呢?
答案是:依靠坐标来区分这些thread。
那么如何得到这些坐标呢?这就引出了我们要讲的线程索引的概念。
切分上面这一行代码,其实无非是分成两个部分:
- 确定每个线程thread的块block索引
- 确定每个线程thread的线程索引
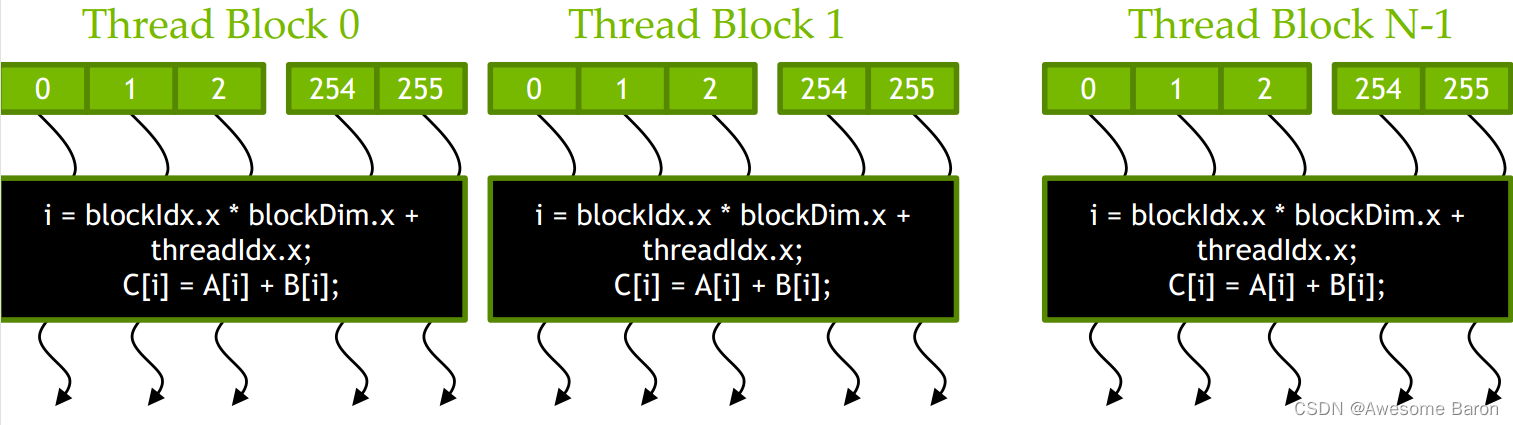 结合这个图,我们来继续理解这行代码的意思。首先,我们如何确定这个线程所在的块呢?
结合这个图,我们来继续理解这行代码的意思。首先,我们如何确定这个线程所在的块呢?
答案很明显:blockIdx.x。
定位到这个块之后,还需要更精确地定位到这个块所对应的第一个线程的位置,于是需要blockIdx.x*blockDim.x,blockDim.x表示的就是块的大小,也就是一个块包含多少个线程。
最后,我们要找到线程在这个块中所处的位置,也就是threadIdx.x。将块的索引与线程索引相加就得到了我们需要的最终的线程索引。
通过以上过程,就不难理解,为什么线程的索引要定义为i = blockIdx.x * blockDim.x + threadIdx.x了。
1.3 完整的可运行的向量加法代码
#include <stdio.h>
#include <time.h>
#include <cuda.h>
#define N 50000
// 用每个线程来计算矢量加法的一个输出元素的核函数
__global__ void vecAddkernel_1(int* d_a, int* d_b, int* d_c)
{
int i = threadIdx.x + blockIdx.x * blockDim.x;
d_c[i] = d_a[i] + d_b[i];
}
int main()
{
int size = N * sizeof(int);
int h_a[N], h_b[N], h_c[N]; // host 数组
int* d_a, * d_b, * d_c; // GPU 指针
// 为 GPU 指针分配内存
cudaMalloc(&d_a, size);
cudaMalloc(&d_b, size);
cudaMalloc(&d_c, size);
// 初始化 host 数组
for (int i = 0; i < N; i++)
{
h_a[i] = 1;
h_b[i] = 3;
}
// 将 host 数组数据拷贝到 GPU 指针中
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
// 统计函数运行时间
clock_t start, end;
start = clock();
// 运行函数,内核参数为:N/256 个 block,每个 block256 个线程
vecAddkernel_1 <<<N / 256, 256 >>> (d_a, d_b, d_c);
end = clock();
float time1 = (float)(end - start) / CLOCKS_PER_SEC;
printf("执行时间为%f\n", time1);
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
向量加法是一个简单的入门例子,但是了解它有利于帮助你从一开始对于CUDA并行计算的程序结构有印象,这将帮助你接下来的学习。
2. 例子2:用二维grid处理图片
如下方的图所示,我想要用大小为1616的block去覆盖掉这副需要处理的图像的所有像素。具体的操作是:将每个像素值缩放2.0。

2.1 核函数代码
首先给出核函数代码:
__global__ void PictureKernel(float* d_Pin, float* d_Pout, int height, int width)
{
// Calculate the row # of the d_Pin and d_Pout element
int Row = blockIdx.y*blockDim.y + threadIdx.y;
// Calculate the column # of the d_Pin and d_Pout element
int Col = blockIdx.x*blockDim.x + threadIdx.x;
// each thread computes one element of d_Pout if in range
if ((Row < height) && (Col < width)) {
d_Pout[Row*width+Col] = 2.0*d_Pin[Row*width+Col];
}
}在上述核函数代码中,由于grid为二维的,变量Row表示竖直方向上的索引,变量Col表示水平方向上的索引。确定好当前像素的行与列之后,为什么要有if这个条件判断呢?
我的理解是:限定边界,上图中我们可以看到1616的block在覆盖大小为76
62的图片时,超出边界的部分thread并未覆盖到某个具体像素,因此不必参与计算。
而要取出最终参与计算的像素索引,需要用到Row*width+Col,由于类似C语言的行优先存储,所以对应的像素索引映射可以这样计算。

核函数部分就讲到这里。
2.2 调用核函数时的另一种写法
现在我们来看在Host端调用核函数时可以采用另一种写法:
//assume that the picture is m × n,
// m pixels in y dimension and n pixels in x dimension
// input d_Pin has been allocated on and copied to device
// output d_Pout has been allocated on device
dim3 DimGrid((n-1)/16 + 1, (m-1)/16+1, 1);
dim3 DimBlock(16, 16, 1);
PictureKernel<<<DimGrid,DimBlock>>>(d_Pin, d_Pout, m, n);在这里的写法中,默认grid是三维的。我们在本例中想使用二维的grid,将最后一个维度z默认为1即可。第一个配置参数DimGrid以block的数量指定grid的维度,第二个参数DimBlock以thread的数量指定block的维度。将它们视为三维的来进行理解。














 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









