






基于注意力的Transformer网络被广泛用于序列建模任务,包括语言建模和机器翻译。为了提高性能,模型通常通过增加隐藏层的维度来扩展,或者通过堆叠更多的Transformer块来扩展。例如,T5使用65K的隐藏层参数,GPT-3使用96个Transformer块。然而,这样的缩放显著增加了网络参数的数量(例如,T5和GPT-3分别有110亿个和1750亿个参数),并使学习复杂化,也就是说,这些模型要么需要非常大的训练库或特定的的正则化。
在本篇文章中介绍一篇论文,该论文引入了一种新的基于参数的高效注意力架构,可以很容易地扩展到广泛和深入。DeLighT 提出了一个更深、更轻的Transformer,更高效地在每个Transformer块中分配参数:
使用DeLighT 深度和轻量级转换;
对跨块使用块的缩放,允许较浅和较窄的DeLighT 靠近输入,更宽和较深的DeLighT 靠近输出。
一般来说,DeLighT 深度是标准Transformer的2.5 ~ 4倍,但参数和操作更少。
模型缩放
模型缩放是提高顺序模型性能的标准方法。 模型的大小在宽度比例上增加,而在深度比例上堆叠更多的块。 在这两种情况(及其组合)中,网络每个块中的参数都相同,这可能出现次优解决方案。 为了进一步改善序列模型的性能,[1]引入了块比例缩放,允许设计可变大小的块并在网络中有效分配参数。
论文的研究结果表明:
- 靠近输入的较浅和较窄的DeLighT块,靠近输出的较深和较宽的DeLighT块可提供最佳性能。
- 与仅使用模型缩放相比,基于块缩放的模型可以实现更好的性能。
卷积神经网络(CNN)还可以学习靠近输入的浅层和窄层表示,以及靠近输出的深层和宽泛表示。 与在每个卷积层中执行固定数量的操作的CNN不同,建议的块缩放在每个层和块中使用可变数量的操作。
改善序列模型
最近,在改善序列模型的其他相关方法上也进行了重要工作,包括
(1)使用更好的标记级别表示(例如使用BPE),自适应输入和输出以及定义以提高准确性,以及
(2)使用压缩 ,修剪和蒸馏以提高效率。
与[1]的工作最接近的是定义转换,它也使用了“展开-缩小”策略来学习表示形式。 DeFINE变换(图1c)和DeLighT变换(图1d)之间的主要区别在于,DeLighT变换在扩展层和简化层之间分配参数时更有效。
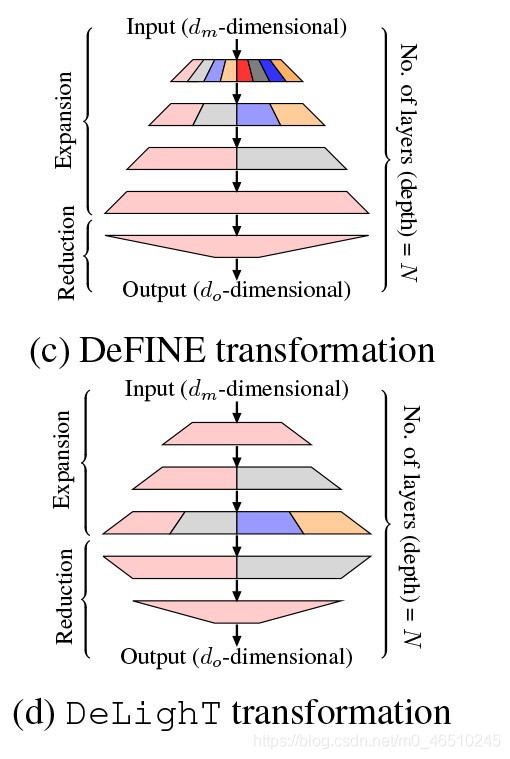
(c,d)比较了DeFINE变换和DeLighT变换。 与DeFINE变换相比,DeLighT变换使用具有更多组的组线性变换(GLT)来学习具有较少参数的更广泛的表示形式。 不同的颜色用于显示GLT中的组。 为简单起见,特征改组未在(d)中显示。
与DeFINE不同,DeFINE使用较少的组来学习组线性变换中的更多鲁棒表示,而DeLighT变换使用更多的组来学习范围更广的表示,并且参数较少。 DeLighT转换可实现与DeFINE转换相同的性能,但参数要少得多。
DeLight Transformer
标准的Transformer块如图1a所示:
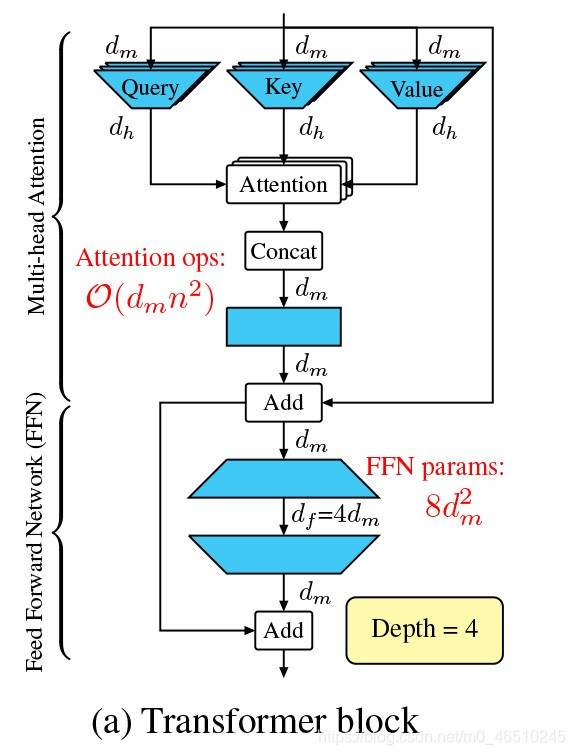
包括使用查询,键,值对序列令牌之间的关系进行建模,以及使用前馈网络(FFN)来学习更广泛的表示形式。
通过将3个投影应用于输入以获得Query,Key和Value,可以获得多头注意。 每个投影均由h个线性层(或头部)组成,并且尺寸输入映射到一维空间,即头部尺寸。
FFN由以下两个线性层操作完成:
第1步:尺寸扩展;
第2步:尺寸缩减。
DeLight
DeLighT变换首先将维输入向量映射到高维空间,然后使用N层组变换将其简化为维输出向量(降阶),如图1d所示。
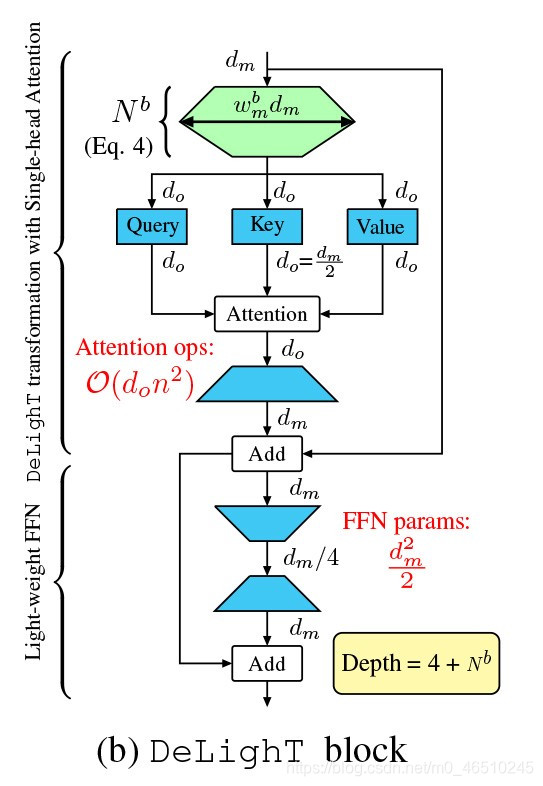
在展开缩减阶段,DeLighT变换使用组线性变换(GLT),因为它们通过从输入的特定部分导出输出来学习局部表示,这比线性变换更有效。为了学习全局表示,DeLighT变换使用特征变换在组线性变换的不同组之间共享信息,类似于卷积网络中的通道变换。
增加Transformer的表达能力和容量的标准方法是增加输入尺寸。但是,线性增加也会增加标准Transformer块(序列长度在其中)的多头注意力的复杂性。相比之下,为了增加DeLighT块的表达能力和容量,论文使用扩展和收缩阶段来增加中间DeLighT过渡的深度和宽度。这使DeLighT可以使用较小的尺寸和较少的操作来计算注意力。
DeLighT变换由5个配置参数控制:
- GLT层数N,
- 宽度乘数,
- 输入维数,
- 输出维度,
- GLT中最大的组数
在两个常见的序列建模任务(i)机器翻译和(ii)语言建模上,DeLighT模型在参数和操作上明显少于Transformer模型,但其性能与Transformer模型相似或更好,在资源低的WMT’16 En-Ro机器翻译数据集上, DeLighT使用的参数减少了2.8倍,并实现了Transformer相同性能。 在高资源WMT’14 En-Fr数据集上,DeLighT以比基线Transformer少1.8倍的参数提供了更好的性能(+0.4 BLEU分数)。 同样,在语言建模方面,DeLighT在WikiText-103数据集上将Transformer-XL的性能(Dai等人,2019)与参数减少了1.5倍相匹配。
引用
1.Sachin Mehta, Marjan Ghazvininejad, Srinivasan Iyer, Luke Zettlemoyer, Hannaneh Hajishirzi,DeLighT: Deep and Light-weight Transformer,
arXiv:2008.00623
作者:Nabil MADALI
deephub翻译组














 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









