






这是微软再5月刚刚发布的一篇论文提出了一种解码器-解码器架构YOCO,因为只缓存一次KV对,所以可以大量的节省内存。
以前的模型都是通过缓存先前计算的键/值向量,可以在当前生成步骤中重用它们。键值(KV)缓存避免了对每个词元再次编码的过程,这样可以大大提高了推理速度。
但是随着词元数量的增加,KV缓存占用了大量GPU内存,使得大型语言模型的推理受到内存限制。所以论文的作者改进了这一架构:
YOCO是为自回归建模而设计的,例如大型语言模型(llm)。所提出的解码器-解码器架构有两部分,即自解码器和交叉解码器,如下图所示

2个解码器架构
YOCO采用L块堆叠,其中前L/2层为自解码器,其余模块为交叉解码器,自解码器和交叉解码器都遵循与Transformer类似的块(即,交叉注意力和FFN)。
自解码器与交叉解码器的区别在于它们各自的注意力块不同,自解码器使用高效的自注意机制(例如,滑动窗口注意力)。而交叉解码器使用全局交叉注意力来关注自解码器输出产生的共享KV缓存。
自解码器:
以词元嵌入X0作为输入,计算中间向量表示M = X * u /²

这里的ESA(·)表示自注意力实现,SwiGLU(X) = (swish(XWG)⊙XW1)W2,其中的 LN(·)使用RMSNorm。
还在自注意力中使用了mask(遮蔽掉后面的内容),这个自注意力的模块在推理时的内存占用是 O(1),即KV缓存数为常数。
交叉解码器:
自解码器的输出X * u /²产生交叉解码器的全局KV缓存K, V:

其中,WK,WV∈Rd×d为可学习权重。
交叉解码器层在自解码器之后堆叠,获得最终输出向量XL。KV缓存{K}、{V}被所有L/2交叉解码器模块重用:

其中Attention(·)是标准的多头注意力,Wˡᵩ∈Rd×d为可学习矩阵。
交叉注意也应用了mask,并且使用分组注意力,进一步节省了KV缓存的内存消耗,在获得Xᴸ后,使用softmax分类器执行下一个词元的预测
推理的优势
1、节省GPU内存
下表比较了transformer和YOCO的存储复杂度,其中N、L、D分别为序列长度、层数和隐藏维数
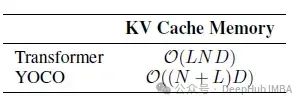
全局KV缓存被重用,并且只需要恒定的缓存,数量为O (N + CL),其中N为输入长度,C为常数(如滑动窗口大小),L为层数。这样对于长序列,CL远小于N,因此只需要大约O(N)个缓存,就是论文名字说的 “只缓存一次”。相比之下,Transformer解码器在推理期间必须存储N × L个键和值,与Transformer解码器相比,YOCO大约为缓存节省了L倍的GPU内存
2、减少预填充时间
下图显示了YOCO 推理时的并行编码和逐个解码输出。
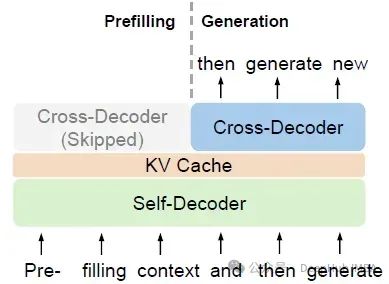
如上图所示,由于交叉解码重用了自解码的输出,使得预填充可以在不改变最终输出的情况下提前得到结果,从而大大加快了预填充阶段。
自解码器的选择
1、门控保留率
门控保留(gRet,又名gRetNet或RetNet-3)通过数据依赖的门控机制增强了保留,从而在序列建模中同时实现了训练并行性、良好的性能和较低的推理成本。该方法统一了并行、递归和块递归计算范式
并行表示的门控保留率定义为:
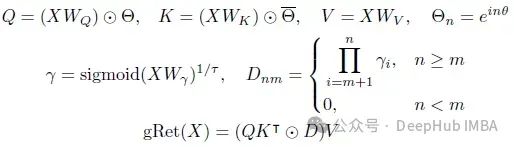
其中W,Wₖ,Wᵥ∈Rd×d和Wγ∈Rd×1是可学习的权重,并且温度项τ鼓励γ到1以更好地记忆
2、递归表示
门控保持的输出等价于并行表示,可以循环计算。对于第n个时间步长,通过以下方式获得输出:

其中Q K V γ和并行表示的定义是一样的
3、分段递归表示
分段表示是循环表示和并行表示的统一形式。给定块大小B,输出以块为单位计算,计算分为块内部分和跨块部分设[i]为第i个块,即x[i] = x(i−1)B+1,····,xiB,则第i个块计算为:

其中Ri是第i块的中间态,β总结了数据控制的衰变γ。
4、多头门控保留
与多头注意[VSP+17]和多尺度保留类似,作者对每个头部应用门控保留,并将输出组合在一起:
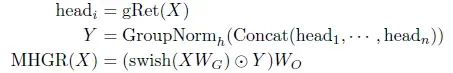
其中WG,WO∈Rd×d是可学习的矩阵,GroupNorm对每个头进行规范化,swish gate应用于增加非线性
5、滑动窗口的注意力
滑动窗口注意将注意范围限制为固定的窗口大小C,在推理过程中,KV缓存复杂度可以从O (N)降低到O ©,即内存占用是恒定的,而不是随着序列长度的增加而增加。与多头自注意力类似,可以通过以下方式计算滑动窗口注意的输出:
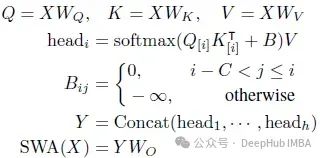
这里的WQ,WK,WV,WO∈Rd×d为可学习矩阵,窗口因果掩码B控制每个查询只关注距离小于C
实验结果
作者通过增加训练词元的数量来训练一个3B大小的YOCO语言模型。然后与基于transformer的语言模型进行比较。
与LM Eval Harness上的OpenLLaMA-v2-3B、StableLMbase-alpha-3B-v2和StableLM-3B-4E1T进行比较结果如下:
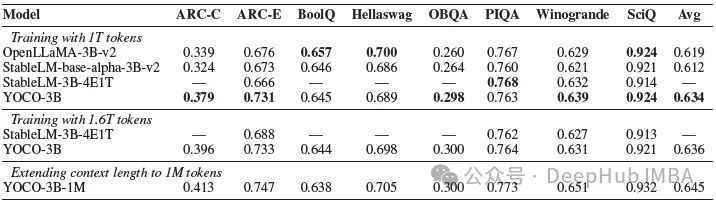
跨端任务的实验结果表明,YOCO与Transformer语言模型取得了相当的结果,同时在训练方面具有可扩展性。
Llama Transformer、带门控的YOCO (YOCOgRet)和带滑动窗口注意力的YOCO (YOCOSWA)使用相同的训练数据和设置训练不同规模(160M、400M、830M、1.4B、2.7B、6.8B、13B)的语言模型。Transformer架构增强了Llama的改进,如RMSNorm、SwiGLU和消除偏差。

与llama优化架构相比,YOCO在160M到13B的范围内获得了相当的性能,这表明YOCO在模型尺寸方面可以有效地扩展。YOCOgRet优于Transformer和YOCOSWA是因为注意力和混合架构,它们的归纳偏差往往是相互补充的。
将YOCO-3B的上下文长度扩展到1M标记,并对长上下文模型在检索和语言建模任务上进行评估。
YOCO- 3b - 1m以近乎完美的精度通过了“Needle-In-A-Haystack”测试,表明YOCO具有较强的长上下文建模能力
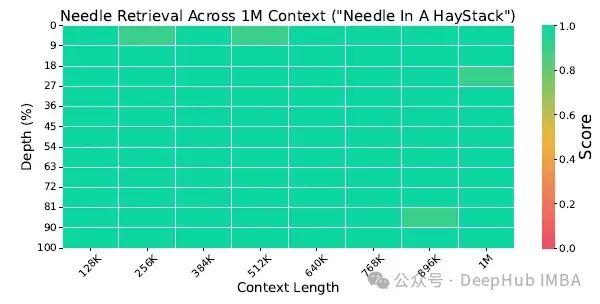
下表报告了N needles的精度。N = 1为参考单针检索,N > 1为多针检测。评估以128K长度进行,因为大多数以前的长上下文模型都是用这个长度进行调优的。
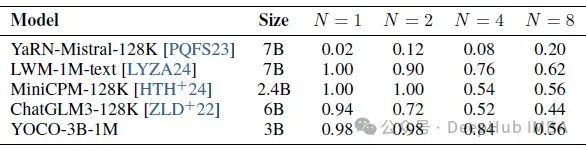
YOCO-3B-1M可以用一半的模型尺寸达到相当的性能。与MiniCPM-128K和ChatGLM3-128K相比,YOCO-3B-1M也优于这些语言模型。
下表显示了累积平均负对数似然(NLL)作为上下文长度的函数

NLL随序列长度的增加而降低,表明YOCO可以有效地利用远程依赖进行语言建模。
推理的优势
将YOCOgRet与Transformer进行比较
1、GPU内存
推理内存消耗由模型权重、中间激活和KV缓存三部分组成。

随着上下文长度的增加,KV缓存成为主要的内存瓶颈,而模型权重消耗恒定的内存,表明YOCOgRet减轻了激活成本和KV缓存内存占用。下图显示了Transformer和YOCO在不同长度上的推理内存,由此得出使用YOCO可以显著降低内存成本的结论

下图显示了不同模型大小的每个词元的KV缓存的GPU内存消耗

由于YOCO只缓存一层全局键值对,所以它需要的内存比Transformer大约少L倍。
在预填充阶段,模型并行地对输入进行编码。下图显示了不同长度的预填充延迟,即给定输入提示符在生成第一个结果之前的编码时间
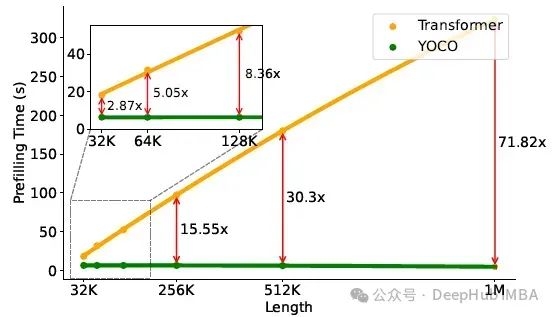
Transformer的时间呈二次增长,而YOCO的时间呈线性增长。即使对于较短的输入长度,例如32K, YOCO仍然可以加速2.87倍
吞吐量表示模型每秒可以处理多少词元,包括预填充时间和生成时间下图显示了Transformer和YOCO在改变上下文长度时的推理吞吐量。

YOCO实现了更高的跨上下文长度的吞吐量。
总结
论文提出了一种用于大型语言建模的解码器-解码器体系结构(YOCO)。与Transformers相比,YOCO具有更好的推理效率和竞争性能。实验结果表明,在各种设置下,YOCO在大型语言模型上取得了良好的效果,即扩大训练词元数量,扩大模型大小,将上下文长度扩大到1M词元。分析结果还表明,YOCO将推理效率提高了几个数量级,特别是对于长序列建模
论文地址:
https://avoid.overfit.cn/post/90e0bd170644476cbccabb039e7105ae
作者:SACHIN KUMAR














 71
71











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









