







这篇论文介绍了一种名为YOCO(You Only Cache Once)的新型解码器-解码器架构,旨在提高大型语言模型的推理效率和性能。
论文:You Only Cache Once: Decoder-Decoder Architectures for Language Models
地址:https://arxiv.org/pdf/2405.05254
摘要
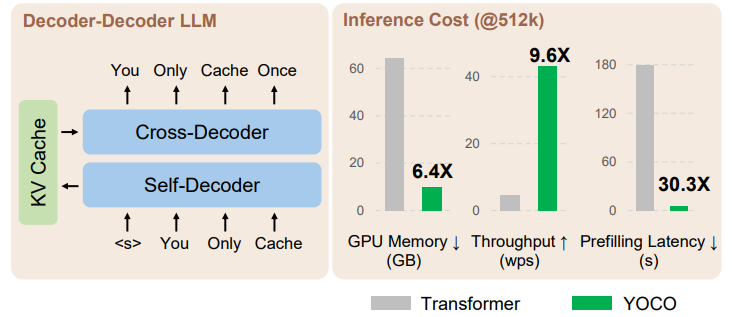
介绍: YOCO是一种新型的大型语言模型架构,它通过仅缓存一次键值对(KV pairs)来显著降低GPU内存需求,同时保持全局注意力(global attention)能力。
组成: YOCO由自解码器(self-decoder)和交叉解码器(cross-decoder)组成,自解码器生成全局KV缓存,交叉解码器通过交叉注意力(cross-attention)重用这些缓存。
性能: 实验结果显示,YOCO在不同模型大小和训练令牌数量的设置下,与Transformer相比,在推理内存、预填充延迟和吞吐量方面有显著提升。
引言 (Introduction)
背景: 论文讨论了语言模型的发展,包括仅编码器模型(如BERT)、编码器-解码器模型(如T5)和仅解码器模型(如GPT)。
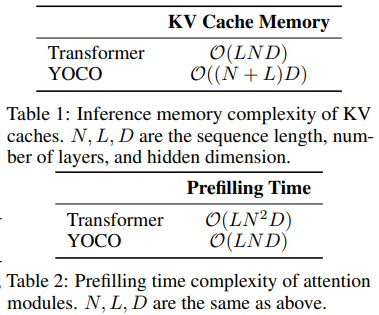
问题: 随着服务令牌数量的增加,KV缓存占用大量GPU内存,导致大型语言模型的推理受到内存限制。
YOCO架构: 论文提出了YOCO架构,它通过仅缓存一次KV对来解决这个问题,并允许更高效的分布式长序列训练。
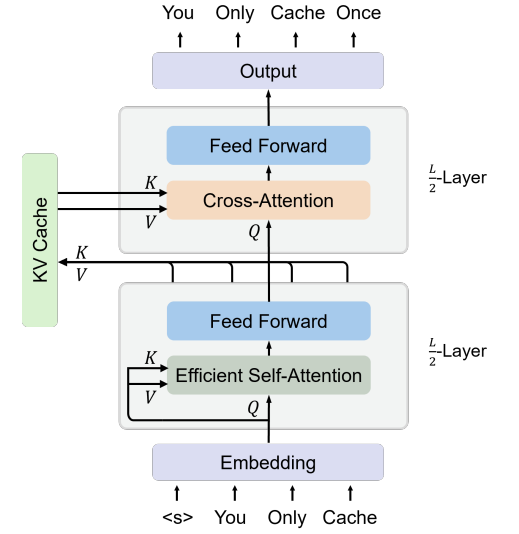
YOCO架构
设计目的: YOCO旨在进行自回归建模,如大型语言模型(LLMs)。
架构组成: YOCO由自解码器和交叉解码器组成,自解码器生成全局KV缓存,交叉解码器使用交叉注意力重用这些缓存。
自解码器: 使用高效的自注意力机制,如滑动窗口注意力(sliding-window attention)。
交叉解码器: 使用全局交叉注意力来关注自解码器输出的共享KV缓存。
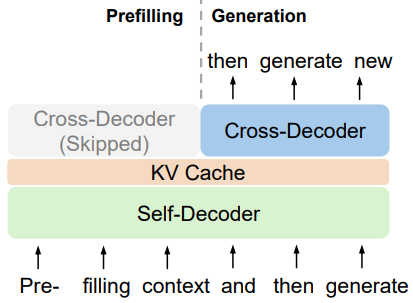
实验
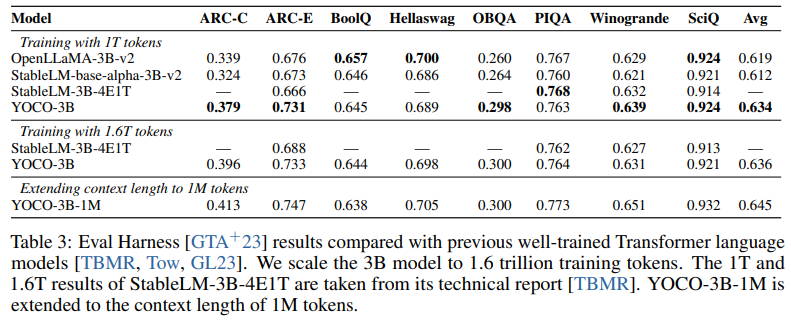
语言建模评估: 作者训练了一个3B大小的YOCO语言模型,并与强大的基于Transformer的语言模型进行了比较。
可扩展性: 论文展示了YOCO在不同模型大小下的扩展性,并通过实验结果证明YOCO在模型大小上的可扩展性。
长上下文评估: 作者将YOCO-3B的上下文长度扩展到1M令牌,并评估了其长序列建模能力。
推理优势
GPU内存和吞吐量: YOCO在GPU内存占用和推理吞吐量方面相比Transformer有显著优势。
预填充时间: YOCO减少了预填充时间,使得长上下文模型的用户体验得到改善。
结论
贡献: YOCO通过显著提高推理效率和保持竞争性能,为大型语言模型提供了一种新的架构。
未来工作: 论文提出了将YOCO与其他技术结合以进一步降低部署成本和优化KV缓存模块的可能方向。
这篇论文提出了一种新的架构,通过减少键值对缓存的次数来优化大型语言模型的内存使用和推理速度,同时保持了模型的性能。通过一系列实验,作者证明了YOCO在多个方面相比现有Transformer模型的优势。
本文主要来自kimi解读,具体了解请阅读原论文。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









