







在mapreduce出现之前,已经有像mpi这样非常成熟的并行计算框架了,那么为什么google还需要mapreduce?mapreduce相较于传统的并行计算框架有什么优势?

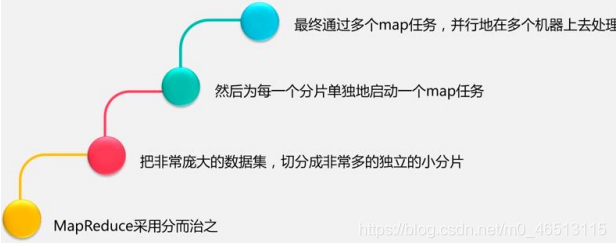
mapreduce的策略:采用’“分而治之”策略,把非常庞大的数据集,切分成非常多的独立的小分片然后为每一个分片单独启动一个map任务,最终通过多个map任务并行地在多个机器上去处理分而治之
mapreduce框架采用了master/slave架构,包括一个master服务器和若干个slave服务器。master上运行jobtracker,slave上运行tasktracker。

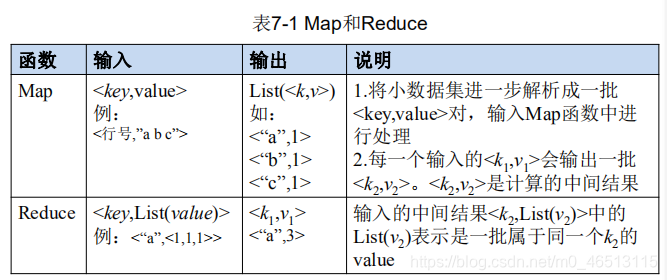
map和reduce函数
mapreduce主要有以下四个部分组成:
(1)client
●用户编写的mapreduce程序通过client提交到jobtracker端
●用户可通过client提供的一些接口查看作业运行状态
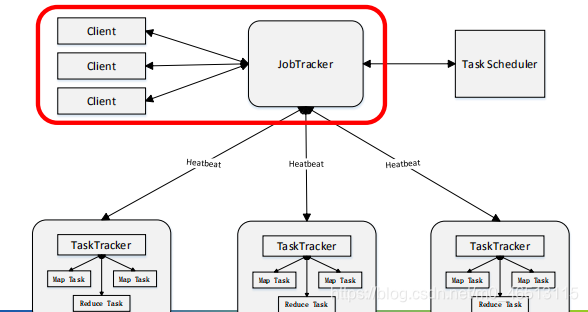
(2)jobtracker
●jobtracker负责资源监控和作业调度;
●jobtracker监控所有tasktracker与job的健康状况,一旦发现失败,就将相应的任务转移到其他节点;
●jobtracker会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空闲时,选择合适的任务去使用这些资源。
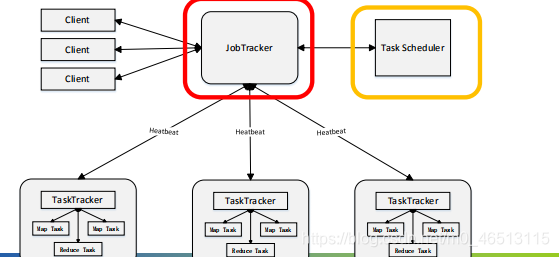
(3)tasktracker
●tasktracker会周期性地通过心跳将本节点上资源的使用情况和任务的运行进度汇报给jobtracker,同时接收jobtracker发送过来的命令并执行相应的操作;
●tasktracker使用“slot”等量划分本节点上的资源量。一个task获取到一个slot后才有机会运行,而hadoop调度器的作用就是将各个tasktracker上的空闲slot分配给task使用。slot分为map slot和reduce slot两种,分别供map task和reduce task使用;
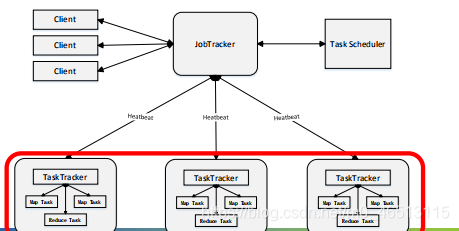
(4)task
●task分为map task和reduce task两种,均由tasktracker启动。
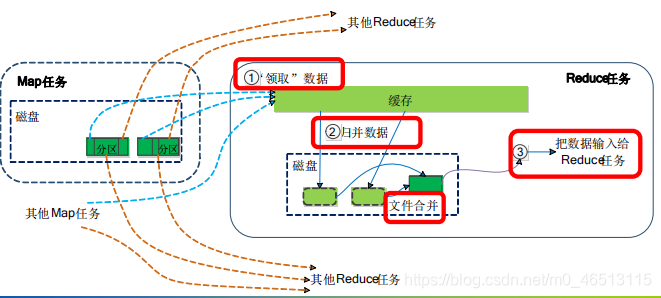
reduce的shuffle过程
●reduce任务通过rpc像jobtracker询问map任务是否已经完成,若完成,则领取数据
●reduce领取数据先放入缓存,来自不同map机器,,先归并,再合并,写入磁盘
●多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
●当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给reduce














 3175
3175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









