







Ming Ding, Chang Zhou, Qibin Chen, Hongxia Yang, Jie Tang, Department of Computer Science and Technology, Tsinghua University, DAMO Academy, Alibaba Group
Cognitive Graph for Multi-Hop Reading Comprehension at Scale
论文原文:https://arxiv.org/pdf/1905.05460v2.pdf
源码:https://github.com/THUDM/CogQA(official / pytorch)
文章目录
1 introduction
近期较多模型(例如 bert )均在一些传统的阅读理解问题上取得了较好的效果,但是本质上同人类表现相比仍存在以下三个需要克服的问题:
- 推理能力:传统阅读理解问题的机制仍限制于从文本中寻找和问题相似的段落并从中提取答案,也就是说只是简答地完成匹配的任务 = 简单的语义匹配,并不具有推理并解决复杂问题的能力。
- 解释性:传统用于解决阅读理解问题的模型并不具有较好的解释性,即使可以标注出提取答案所依赖的段落,但是难以给出整体问题解决推理的逻辑链条,难以 step by step 地给出问题的解决思路。
- 拓展性:传统模型大多通过从整个文本中寻找相关的段落进行一定的文本筛选,再集中于一部分的文本进行整体的阅读理解与答案提取,不同于人类的能够针对总体文本作总结并结合多个部分的信息,再通过推理给出答案的能力。
在这里先解释一下什么是 多跳阅读理解问题:可以直观地理解为需要多次跳转,将不同的信息进行进一步整合才能得到答案的阅读理解问题。举个例子:
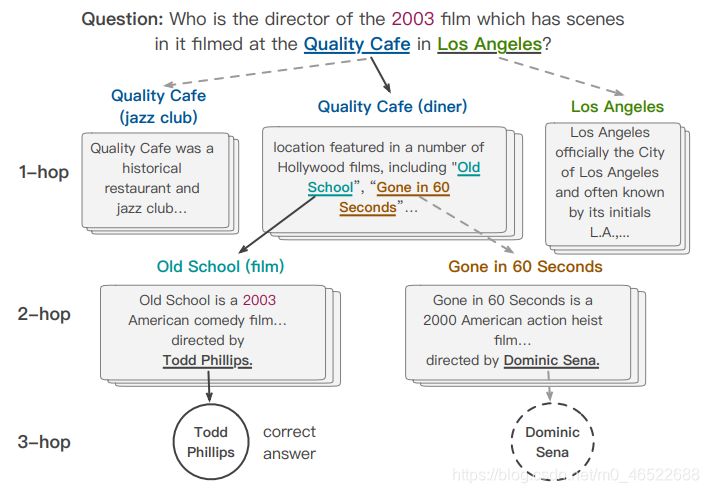
这个问题本身问的是导演,但是没有给出电影的名字,首先需要后面的信息去推断是哪一部电影,才能进一步去寻找该电影的导演。
为解决上述问题,基于 dual process theory,我们尝试将以下两个模块进行结合以模拟人类解决问题的思路:
- 系统 1 通过浏览信息,收集和问题可能相关的信息
- 系统 2 则将得到的信息作进一步的挖掘整合(也就是推理过程)再得到最终的答案
这样的结合方式能够较好地解决更为复杂的多跳阅读理解问题。
基于此本文提出 Cognitive Graph QA (CogQA) 模型。模型主要由以下两个模块组成:
-
system1(BERT):从文本中提取和问题相关的实体(entity)并得到候选答案,同时对其语义信息进行编码(encode),对应到人脑进行阅读理解的过程也就是记忆部分,人通过浏览阅读材料无意识地记录所有和问题相关的信息。
-
system2(GNN):将系统 1 得到的信息进行整合,通过图的方式进行问题的推导,并收集一定的线索(clues)来帮助更好地提取下一跳的信息。对应到人脑也就是推断过程
将上述的两个步骤不断循环重复,直到找到所有可能的候选答案(也就是 system1 不再能够给出新的候选答案的时候)。最后的问题的解答基于 system2 的推断结果,也就是对各个结点更新后的结果(reasoning results)。注意其中两个系统是互相依赖的
2 模型解释
这里利用 BERT 作为 system1,利用 GNN 作为 system2,整体的模型架构如下图所示:

综上整体模型的伪代码如下:

2.1 System 1 (BERT)
也就是对整体信息的提取部分
2.1.1 输入
BERT 部分系统的输入形如: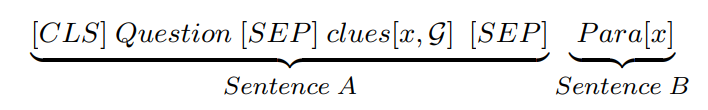
这里的 CLS 和 SEP 同传统 BERT 的含义相同,不再赘述。question 为目标问题文本,而 c l u e s [ x , G ] clues[x ,G] clues[x,G] 为认知图谱中结点 x 的前序结点相关的文本中涉及到了 x 的句子, P a r a [ x ] Para[x] Para[x] 也就是涉及了结点 x 的 context
这里着重说一下 clues,举个例子,在上面的问题中(再放一遍图):
第一跳通过问题提取到了 quality cafe,第二跳通过 quality cafe 提取到了 old school,则此时 quality cafe 就是 old school 的前序结点。此时关于 old school 的 clues 就是所有 quality cafe 的段落中涉及到了 old school 的句子。注意这里的 clues 是直接输入原句子(raw sentence)的,而没有利用某一个隐藏层的表示之类。(原文提到主要是基于训练效率的考虑)
也就是说,这里的 结点 x 的 clues 可以简单理解为(我之所以从 x 的上一个结点推出 x 的原因 = 涉及 x 的上一个结点的文本中确实提到了 x 的证据)
对于一个实体 x 它的 Para[x] 可能是空的(也就是上一个实体确实提到了实体 x,但是实体 x 的更多信息没有了),则此时 Span Extraction 的部分(也就是下一跳实体和候选答案的提取)不能够继续进行,但是仍能够基于前面的部分计算 Semantics Generation 部分。可以认为此时结点 x 不再作延伸(也就是不再有从 x 出发的新的 ans 结点或者实体结点),但是本身 x 自己的初始化表示还是可以完成的。
2.1.2 输出
再来看系统 1 的输出,主要包括两个部分:
- Span Extraction:也就是下一跳的实体 + 答案候选
- Semantics Generation : 关于涉及了结点 x 的文本的语义向量
先分别来计算候选答案和下一跳的实体。将两个部分分开考虑的主要原因是二者的生成依赖的思路不同:候选答案更多的依赖的还是问题的表述和用词(比如对于一个涉及了 where 的问题,明显 new york 比 2019 更可能是正确答案),而下一跳的实体的选择更多地考虑描述的匹配,也就是某一个实体是否符合某一个问题中的描述,考虑的更多的是句子之间的关系。
这里利用四个指针向量 S h o p , E h o p , S a n s , E a n s S_{hop}, E_{hop}, S_{ans}, E_{ans} S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1023
1023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









