







1.什么是感知机
根据输入实例的特征向量X对其进行二分类的线性分类模型
2.目标
感知机模型从输入空间到输出空间的映射可表示为y=f(x)=sign(w*x+b),感知机学习的目的就是学得一个使训练样本正例与负例完全正确分开的超平面wx+b=0,也就是学习参数w和b。
3.损失函数
用分类错误的样本到超平面的距离表示。
点到平面的距离公式为:
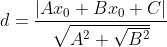

因为在函数y=f(x)=sign(w x+b)中sign为符号函数,因此当wx+b≥0时,y=1;当w*x+b≤ 0时,y=-1;因此对于任意分类错误的样本,其一定满足以下式子:
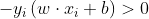
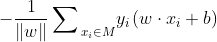
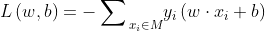
4.梯度下降法
通俗的说,所谓梯度,就是导数和偏导数。梯度下降法的思想就是:梯度方向是目标函数值下降最快的方向,因此沿着梯度下降的方向优化能最快寻找到目标函数的极小值。
下边这张图,直观展示了在只考虑一个参数w时的梯度下降原理:
因此参数w、b的更新可表示为:
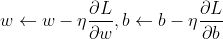
在感知机中采用随机梯度下降法,即每次随机选择一个分类错误的样本计算其梯度,进行w和b的更新,即:
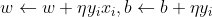
根据w、b的更新公式可以看出感知机学习的过程即利用梯度对参数进行更新,从而使损失函数更小。其过程直观理解为:当一个样本被当前超平面划分到分类错误一类时,利用此样本调整超平面的参数,使超平面向靠近该样本的方向移动,则该样本距离超平面的距离减小,从而降低损失函数,直到超平面移动至使该样本被正确划分为止。
5.感知机算法伪代码

6.sklearn实现感知机算法
首先导入需要的包:
import sklearn
import pandas as pd
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
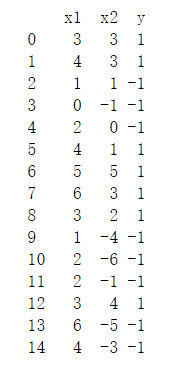
导入数据:这里的数据集是一份包含两维特征、15个样本的线性可分数据。
a=pd.read_excel('D:/DataMining/sj/gzjyb.xlsx',header=0)
print(a)
X=a.iloc[:,:2]
y=a.iloc[:,-1]
数据如下所示:
plt.scatter(a[(a['y']==1)]['x1'], a[(a['y']==1)]['x2'], label='1')#绘制出标签为1的样本
plt.scatter(a[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









