







【昇腾AI-CANN训练营】Ascend C算子开发-学习记录帖
文章目录
前言
此为华为昇腾AI训练营(南京站)授课内容,经个人整理发布
为了更好的理解课程内容,建议读者有一定的计算机组成原理、编译原理学习基础
提示:以下是本篇文章正文内容,笔者自行整理,欢迎批评指正!
一、背景知识
1. CANN&AI core

华为的异构计算架构CANN(Compute Architecture for Neural Networks)对标NVIDA的CUDA
NPU(Neural Processing Unit)架构是一种新型的处理器设计理念,它将传统的CPU和GPU架构进行整合,并引入了深度学习算法。
AI core 采用华为自研的达芬奇架构,它包含下面几个组成部分:
- 计算单元(矩阵计算、向量计算、标量计算)
- 存储系统
- 控制单元
Ascend C编程语言开发的算子运行在AI core上
2. Ascend C算子
-
算子:一个函数空间到函数空间上的映射
-
从广义上讲,对任何函数进行某一项操作都可以认为是一个算子
-
CUDA与CANN的算子不通用
3. 核函数
- 核函数:Ascend C算子设备侧的入口
- 核函数是直接在设备侧执行的代码
- 使用变量类型限定符
- 核函数必须具有void返回类型
- 核函数的调用语句是C/C++函数调用语句的一种扩展
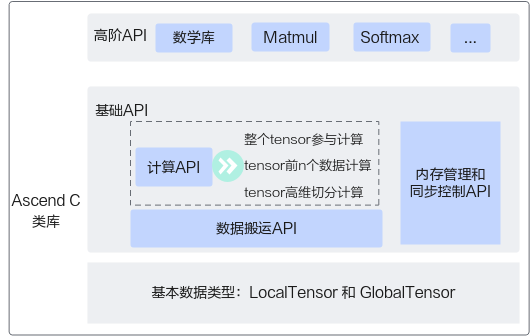
二、编程范式
Ascend C采用标准C++语法和一组类库API进行编程
1)矢量编程主要分为:
- CopyIn
- Compute
- CopyOut
3个流水任务:CopyIn负责搬入操作,Compute负责矢量计算操作,CopyOut负责搬出操作
2)矩阵编程主要分为:
- CopyIn
- Split
- Compute
- Aggregate
- CopyOut
相比矢量编程多了矩阵分割(Split)和聚合(Aggregate)两步
三、香橙派的连接
四、改造sinh任务
首先运动add任务,然后修改add算子功能为sinh函数功能
1.测试运行
根据实验手册,成功运行后会显示:test pass

2.改造成sinh
需要参考一些官方的API:华为昇腾社区-Ascend C
需要修改目录:~/samples/operator/AddCustomSample/KernelLaunch/test
下的两个文档:
- add_custom.cpp
- scripts / gen_data.py
分别需要修改的地方为:
- 1

- 2
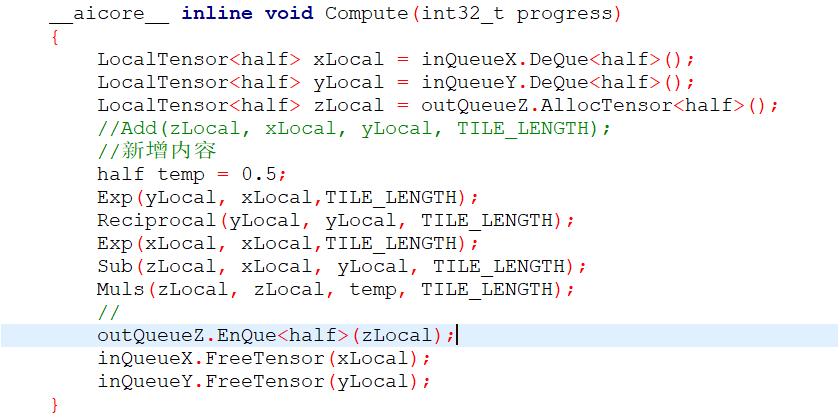
将公式修改为sinh的公式,之后用实验文档中的运行命令再次运行即可
五、Ascend C中级认证
点击链接:Ascend C中级认证考试
题目:
参考tensorflow的Sinh算子,实现Ascend C算子Sinh,算子命名为SinhCustom,并完成aclnn算子调用相关算法: sinh(x) = (exp(x) - exp(-x)) / 2.0
要求:
1、完成host侧和kernel侧代码实现。
2、实现sinh功能,支持float16类型输入,使用内核调试符方式调用算子测试通过。
3、使用单算子API调用方式调用SinhCustom算子测试通过
提交要求:
完成编程后,将上述实现的工程代码打包在rar包内提交,如SinhCustom.rar.
所有需要补充的文件包括:
- op_host文件夹下的sinh_custom_tiling.h文件
- op_host文件夹下的sinh_custom.cpp文件
- op_kernel文件夹下的sinh_custom.cpp文件
这个实现过程可以参考samples仓库的Add算子,把Add算子的内核调用代码复制一份到SinhCustom,Add需要x,y,z三个变量,sinh只需x和y两个变量,因此删掉关于z的操作
- kernel侧的sinh_custom.cpp文件内关键公式修改方法参考前文所示,完整代码如下:
#include "kernel_operator.h"
using namespace AscendC;
constexpr int32_t BUFFER_NUM = 2;
class KernelSinh {
public:
__aicore__ inline KernelSinh() {
}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, uint32_t totalLength, uint32_t
tileNum)
{
//考生补充初始化代码
ASSERT(GetBlockNum() != 0 && "block dim can not be zero!");
this->blockLength = totalLength / GetBlockNum();
this->tileNum = tileNum;
ASSERT(tileNum != 0 && "tile num can not be zero!");
this->tileLength = this->blockLength / tileNum / BUFFER_NUM;
xGm.SetGlobalBuffer((__gm__ DTYPE_X *)x + this->blockLength * GetBlockIdx(),
this->blockLength);
yGm.S 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 233
233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









