






一、引言
感谢华为杭州研究所和ICT计算机产品线提供的宝贵学习机会和优质学习平台,这次参加“2024鲲鹏&昇腾创新大赛集训营”受益匪浅,不仅与其他学校的优秀同学进行了深入交流,还认识到华为计算机产品线等部门在国产化全栈AI计算中做出的巨大贡献。现将今天的学习内容做如下总结。
本文主要介绍(目录):
二、一些概念的理解(CANN、NPU、算子、Ascend C)
1. 什么是CANN
一个通俗的理解是:异构计算架构CANN(Compute Architecture for Neural Networks)就是华为针对AI场景而提出的“国产CUDA”,是上层(昇腾AI应用)与底层(昇腾AI处理器)的桥梁(如图1所示)。其支持多种AI框架,包括MindSpore、PyTorch、TensorFlow等。
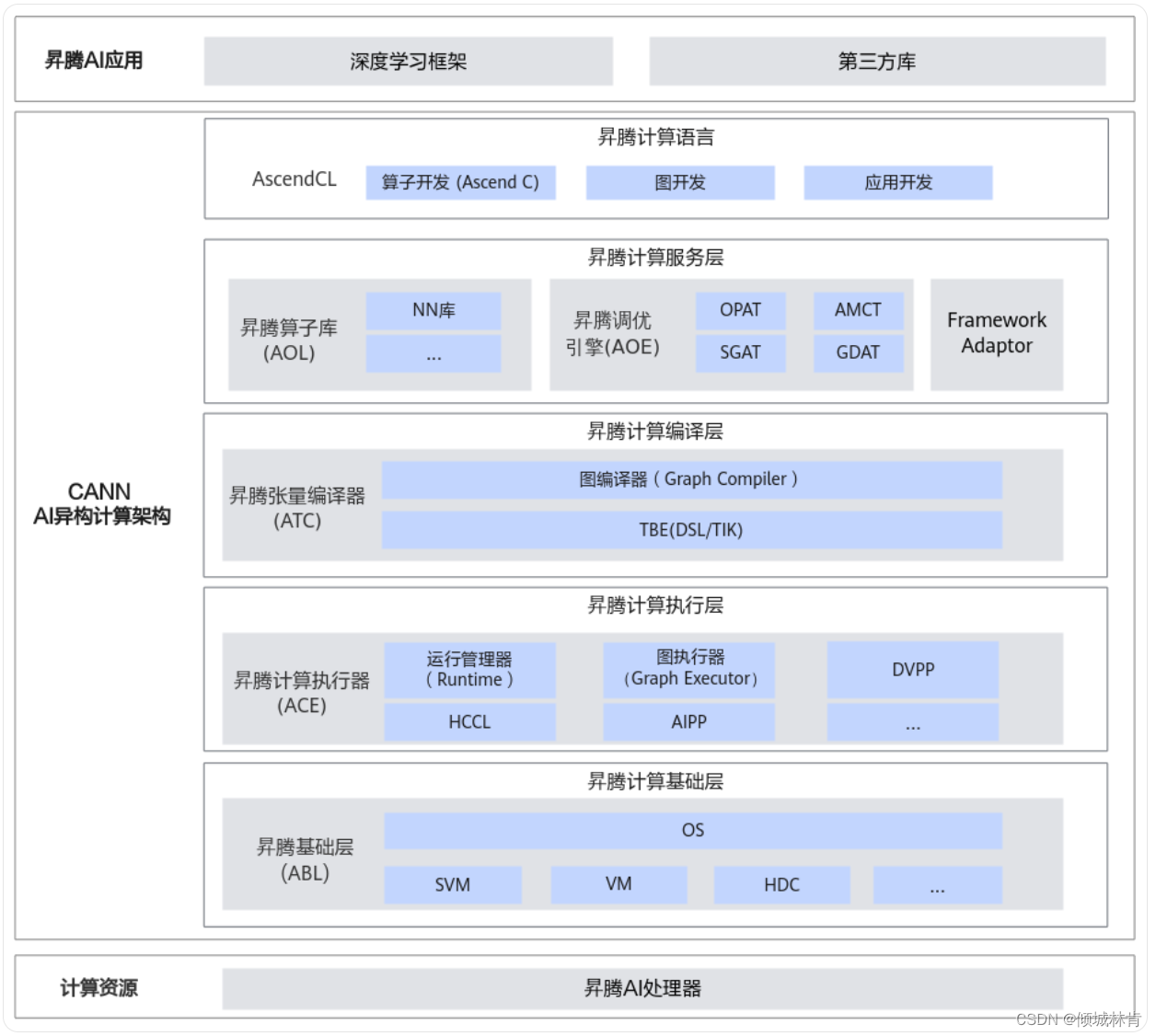
图1 CANN与AI应用和AI硬件的逻辑关系图
2. 什么是NPU
NPU(Neural Processing Unit)架构是一种新型的处理器设计理念,它将传统的CPU和GPU架构进行整合,并引入了深度学习算法。可以通俗理解为:加强版的GPU,从设计理念上来说NPU比GPU更适合处理AI任务。华为的昇腾AI处理器就是NPU架构。
NPU虽然并行计算能力强,但不能独立运行,需要与CPU协同工作,可以看成是CPU的协处理器,CPU负责整个操作系统运行,管理各类资源并进行复杂的逻辑控制,而NPU主要负责并行计算任务。CPU所在位置称为主机端(host),而NPU所在位置称为设备端(device),两者关系如图2所示。

图2 CPU(host)与NPU(Device)的关系图
3. 什么是算子
深度学习算法由一个个计算单元组成,这些计算单元为算子(Operator,简称Op)。从广义上讲,对任何函数进行某一项操作都可以认为是一个算子。例如:卷积层中的卷积算法是一个算子;全连接层中的权值求和过程也是一个算子。
4. 为什么要开发算子
为了使GPU实现特定的AI计算(卷积、全连接、激活等),CUDA开发一系列的算子实现这些计算功能。用户可以直接调算子实现相应功能,使其可以专注于AI任务本身的研究,而不是AI计算的具体实现。
同理,为了在NPU(昇腾AI处理器)上实现AI计算,也需要开发适用于CANN的算子(注:CUDA与CANN的算子不通用)。
5. 什么是Ascend C
Ascend C是一种面向算子开发场景的编程语言。使用Ascend C进行算子开发有如下四点优势:
- C/C++原语编程;
- 编程模型屏蔽硬件差异,编程范式提高开发效率;
- 多层级API封装,从简单到灵活,兼顾易用与高效;
- 孪生调试,CPU侧模拟NPU侧的行为,可优先在CPU侧调试。
三、昇腾AI硬件简介
1. 昇腾AI处理器
昇腾AI处理器有不同的型号和产品形态,小到模块、加速卡,大到服务器、集群。昇腾AI处理器里最核心的部件是AI Core(一个处理器内有多个AI Core),是神经网络加速的计算核心。使用Ascend C编程语言开发的算子就运行在AI Core上,AI Core内部的并行计算架构抽象如图3所示。
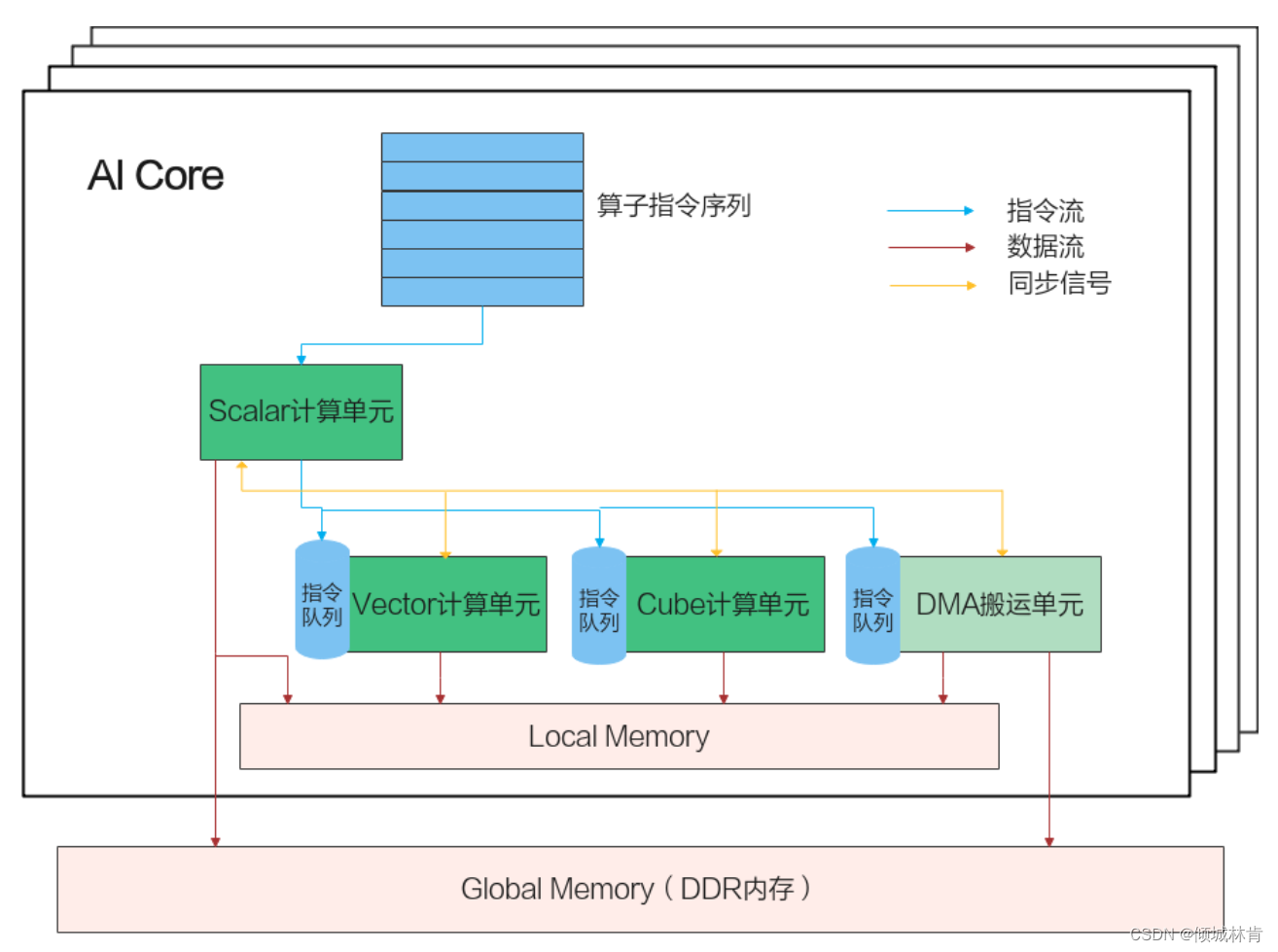
图3 AI Core的并行计算架构
- Scalar计算单元:负责标量计算和算子指令序列的读取;
- Vector计算单元:负责向量的计算;
- Cube计算单元:负责矩阵的计算;
- DMA搬运单元:负责将数据从Local Memory 和 Global Memory之间搬运
- Local Memory:每个AI Core独享,容量小、带宽高,所有待处理数据需拉到此内存中处理;
- Global Memory:(一个处理器内)所有AI Core共享,容量大、带宽低(相对Local Memory),处理完的结果需拉到此内存中保存。
AI Core内部数据处理的基本过程:DMA搬入单元把数据从Global Memory搬运到Local Memory,Vector/Cube计算单元完成数据,并把计算结果写回Local Memory,DMA搬出单元把处理好的数据搬运回Global Memory。
2. Orange Pi AIpro
本次实验的硬件平台为Orange Pi AIpro(Orange Pi AIpro 官网介绍),其搭载了昇腾AI处理器。
四、AI Core并行计算方法
1. 单个AI Core内
单个AI Core内的并行计算遵循流水线并行计算方法,把算子核内的处理程序分成多个流水任务(如图4 所示)。说明如下:
- 同一时间内,每个Stage中的Progress只能执行一个;
- 同一Stage中各Progress执行相同的代码指令;
- Stage的运算依赖关系为Stage1->Stage2->Stage3(即每份数据必须按照该顺序进行运算)。
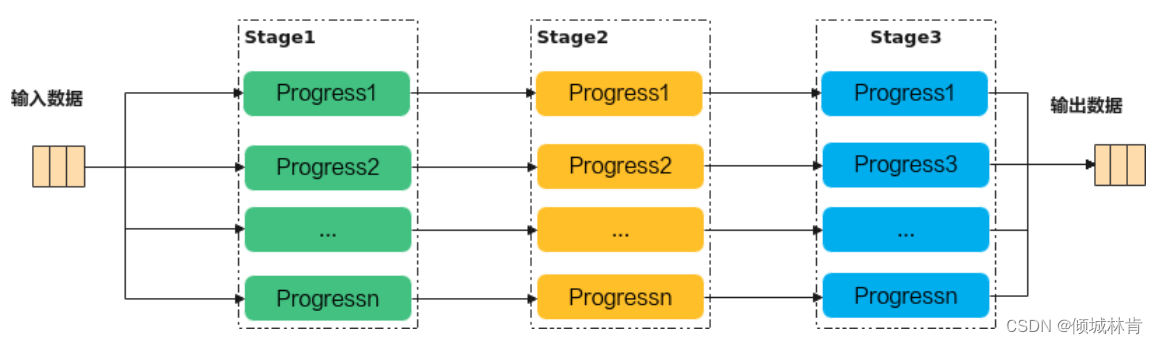
图4 单个AI Core内并行计算流程(图中将某个算子分成3个流水任务处理)
图4表示的运算逻辑为:将输入数据分成n份,每个Progress各拿1份处理,然后送入下一个Stage对应的Progress处理,n份数据依次经Stage1,2,3处理后,再拼成完整的输出。
为了实现最大效率实现并行计算,不同Stage的Progress需要同时进行运算。为了同时满足运算依赖关系和最大效率并行计算两个要求,得到如图5所示的流水线计算图(图中假设n=3)。
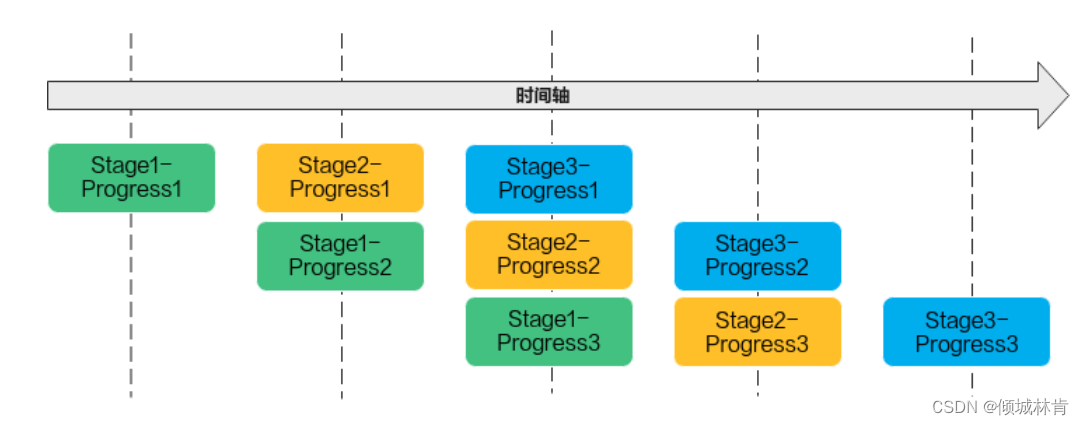
图5 流水线计算图
流水线计算过程中,为了避免并发引起的数据无序,通过队列(Queue)完成任务间通信和同步,并通过统一的内存管理模块(Pipe)管理任务间通信内存。
2. 多个AI Core间
昇腾AI处理器往往包含多个AI Core,如何把多个AI Core充分利用起来呢?常用的并行计算方法中,有一种SPMD(Single-Program Multiple-Data)数据并行的方法。
简单说就是:将数据分成多份,每份数据的处理分别运行在不同的核上(所有核共享相同的指令代码),这样每份数据并行处理完成,整个数据也就处理完了(如图6所示),Ascend C就是采用这种SPMD编程方法。
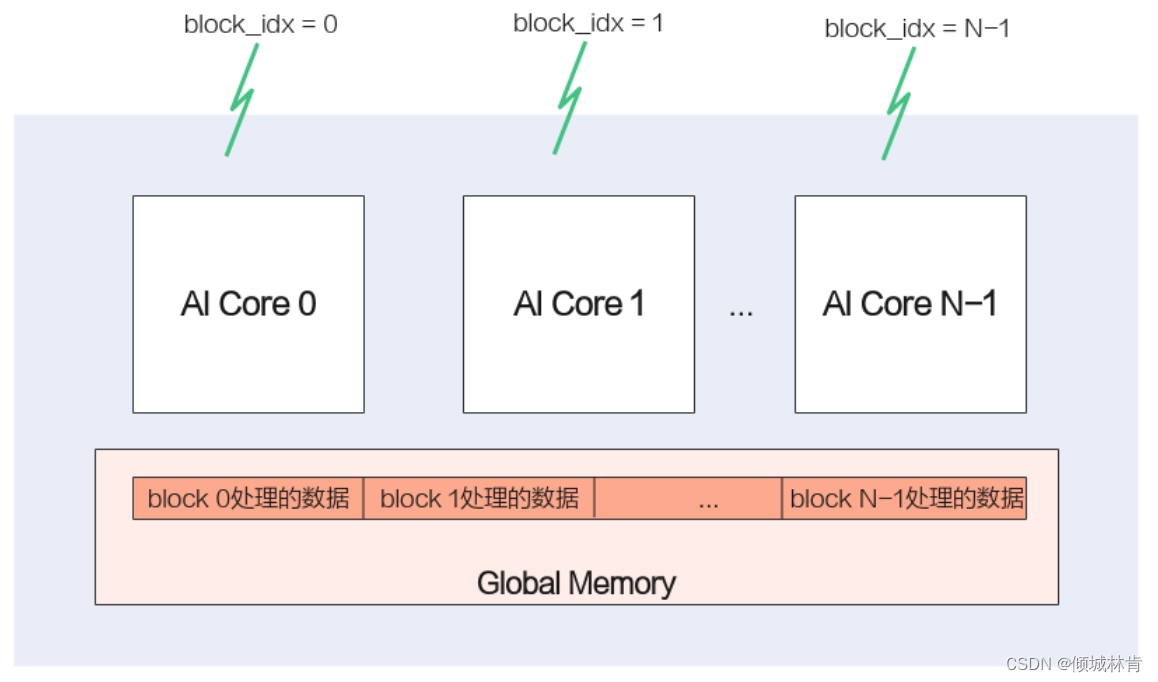
图6 多核并行计算
如图6所示,Ascend C使用block_idx区分不同的AI Core,将Global Memory上的数据分片后,依次分给不同的AI Core即可实现多核并行计算。
五、Ascend C流水编程范式
Ascend C编程范式把算子内部的处理程序,分成多个流水任务(Stage),以张量(Tensor)为数据载体,以队列(Queue)进行任务之间的通信与同步,以内存管理模块(Pipe)管理任务间的通信内存。
1. 矢量编程范式(重点)
1)矢量编程流水任务
矢量编程范式把算子的实现流程分为3个流水任务(Stage):CopyIn,Compute,CopyOut。其中,CopyIn负责搬入操作,Compute负责矢量计算操作,CopyOut负责搬出操作(如图7所示)。
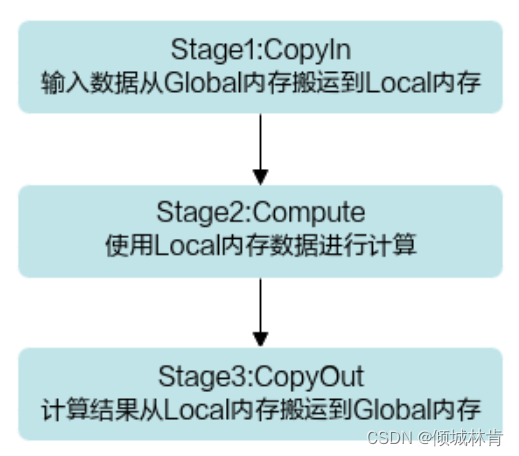
图7 矢量编程范式
2)流水任务通信同步
从图5知,实际计算中这三个任务是并行处理的,那么如何确保三个Stage按照1,2,3的顺序进行呢?为了实现任务之间的通信和同步,Ascend C使用Queue队列进行管理,主要使用EnQue、DeQue两个队列操作API实现任务之间的排序。
Queue的基本思路(此处将VECIN理解为一个变量):
- 例如Stage1的计算结果出来后,会使用EnQue放入VECIN的队列中;
- Stage2(Stage2输入就是Stage1的输出)对VECIN使用DeQue方法,该方法是阻塞模式(即,Stage1的结果未放入VECIN的队列中,Stage2就会一直阻塞在DeQue方法处;直到VECIN队列有值了,DeQue就能将该值取出作为Stage2的输入);
3)流水任务实现思路
首先定义数据存放位置: 搬入数据的存放位置:VECIN; 搬出数据的存放位置:VECOUT。
Stage1:CopyIn任务
使用DataCopy接口将GlobalTensor数据拷贝到LocalTensor;
使用EnQue接口将LocalTensor放入VECIN的Queue中。
Stage2:Compute任务
使用DeQue接口从VECIN中取出LocalTensor;
使用Ascend C接口完成矢量计算;
使用EnQue接口将计算结果LocalTensor放入到VECOUT的Queue中。
Stage3:CopyOut任务
使用DeQue接口从VECOUT的Queue中去除LocalTensor;
使用DataCopy接口将LocalTensor拷贝到GlobalTensor上。
2. 矩阵编程范式
同理,矩阵编程范式把算子的实现流程分为5个基本任务:CopyIn,Split,Compute,Aggregate,CopyOut。相比矢量编程多了矩阵分割(Split)和聚合(Aggregate)两步(流程图如图8所示)
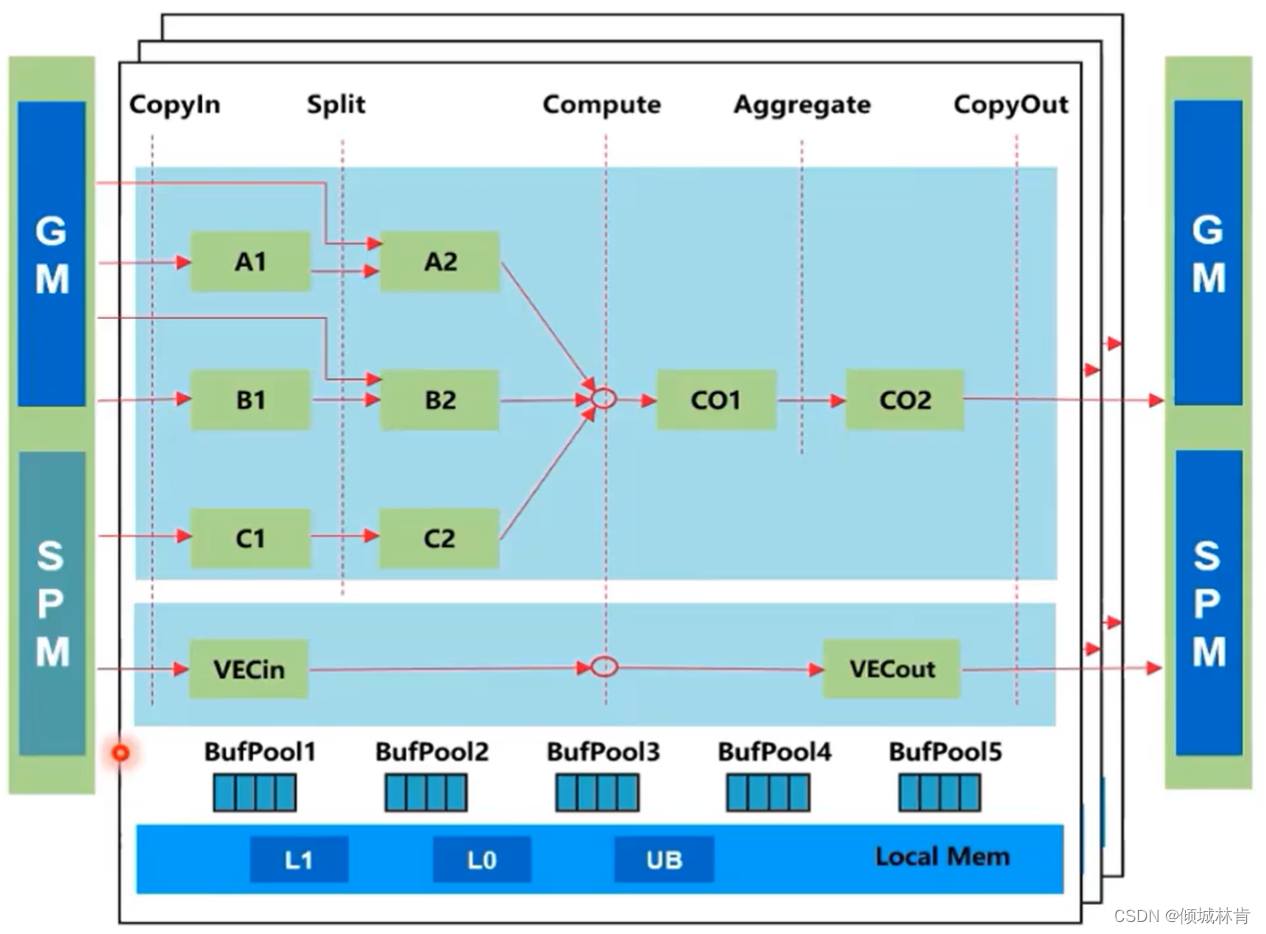
图8 矩阵、矢量编程范式图
3. 复杂的矩阵/矢量编程范式
如遇到复杂的计算过程,通常我们将In/Out组合在一起的方式来实现复杂计算数据流。
六、矢量算子开发流程
矢量算子开发流程共分为以下3步(如图9所示),以矢量算子Add(实现两个相同长度的一维向量的加法运算 z = x + y)的开发为例进行讲解。
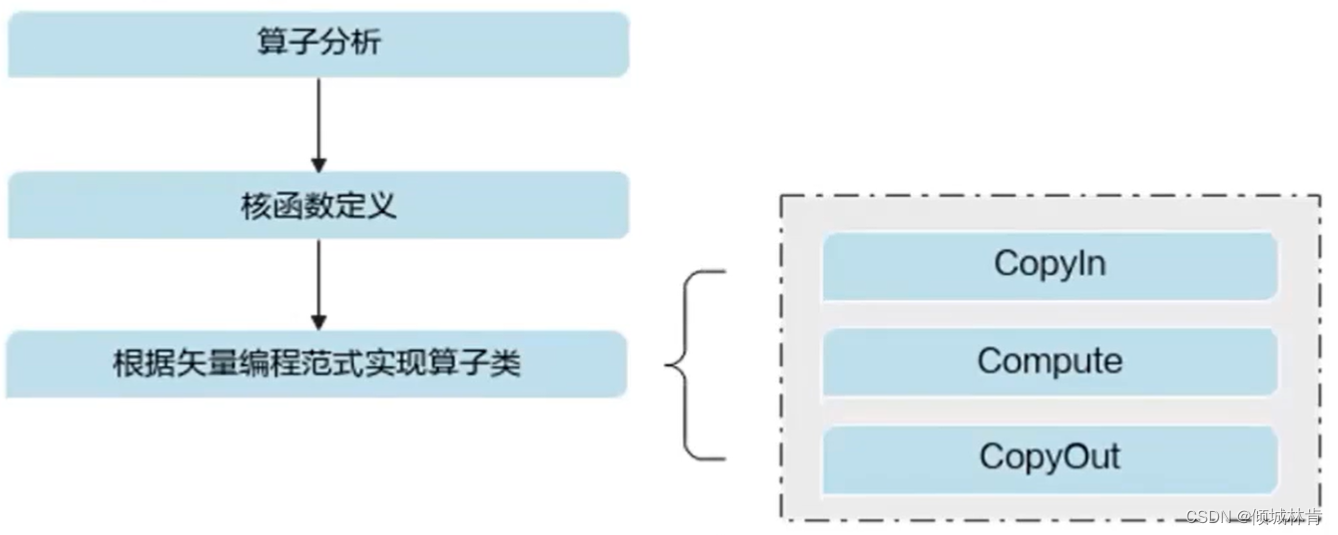
图9 矢量算子开发流程
1. 算子分析
分析算子的数学表达式、输入、输出以及核函数名等(仅对固定输入维度的算子开发进行讲解)。
- 数学表达式:z = x + y(矢量加法运算)
- 输入、输出、核函数名等分析见表1
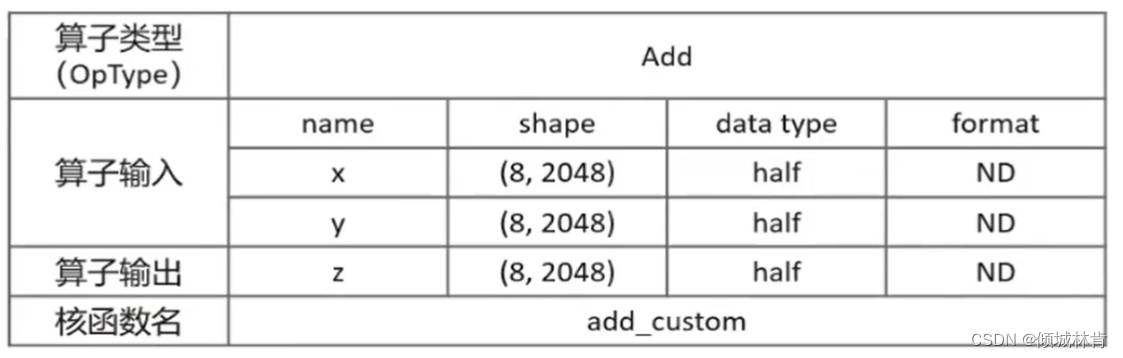
表1 算子分析表格
2. 核函数定义
定义Ascend C算子入口函数,即:
extern "C" __global__ __aicore__ void add_custom()该函数一般都为以下3步:
- 先实例化算子类(需自己定义);
- 调用Init()方法完成内部初始化;
- 调用Process()方法完成核心逻辑。
3. 根据矢量编程范式实现KernelAdd算子类
具体实现方法参考上一点中提到的“3)流水任务实现思路”。主要是将CopyIn,Compute,CopyOut进行实现(具体实现流程图如图10所示)
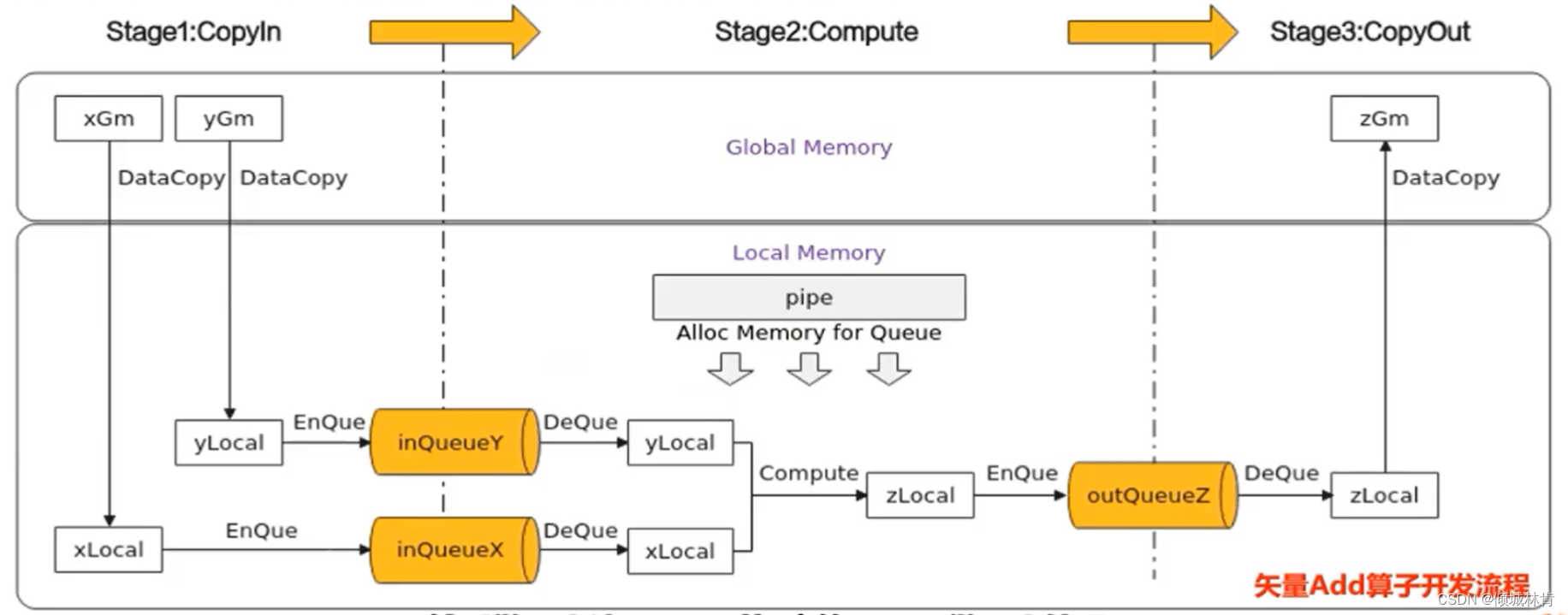
图10 矢量Add算子开发流程
七、代码分析
1.KernelAdd算子类
/*
这是KernelAdd算子类的实现,重要的代码均有注释说明,仔细阅读前文配合注释基本能看懂;
代码中有很多常量,这是根据硬件特性和变量的维度进行设置,无需过分关注。
*/
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 设置x,y,z在Global Memory中的位置
xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
// 为队列初始化内存
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}
__aicore__ inline void Process()
{
int32_t loopCount = TILE_NUM * BUFFER_NUM;
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void CopyIn(int32_t progress)
{
// 在Local Memory上分配内存
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// 搬运数据 Global Memory -> Local Memory
DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH);
DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH);
// 入队列
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
__aicore__ inline void Compute(int32_t progress)
{
// 阻塞取值,确保先完成CopyIn() 再执行Compute()
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
// 在Local Memory上分配内存
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
/* Note:
// 开发不同的算子就是在此处(和对输入输出)进行修改,使用不同的API对Add进行替换即可
// API可从昇腾官网查询:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/80RC2alpha003/apiref/apiguide/apirefguid_07_0001.html
*/
// 实现Add的API
Add(zLocal, xLocal, yLocal, TILE_LENGTH);
// 入队列
outQueueZ.EnQue<half>(zLocal);
// 释放资源,很重要
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
__aicore__ inline void CopyOut(int32_t progress)
{
// 阻塞取值,确保先完成Compute() 再执行CopyOut()
LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
// 搬运数据,Local Memory -> Global Memory
DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH);
// 释放资源,很重要
outQueueZ.FreeTensor(zLocal);
}
private:
// 内存管理变量
TPipe pipe;
// 队列变量
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY;
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ;
// x, y, z在Global Memory上的值
GlobalTensor<half> xGm;
GlobalTensor<half> yGm;
GlobalTensor<half> zGm;
};
2. 核函数实现
// extern "C" __global__ __aicore__ 这是CANN核函数特有标识符,类似于CUDA的核函数
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
KernelAdd op;
op.Init(x, y, z);
op.Process();
}

















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









