







// 如果待执行的任务为null,直接返回空指针异常。如果任务都没有,下面的步骤都没有执行的必要啦。
if (command == null) throw new NullPointerException();
// 获取 ctl 的值,ctl = (runState + workerCount)
int c = ctl.get();
// 如果 workerCount(工作线程数) < 核心线程数
if (workerCountOf(c) < corePoolSize) {
// 执行 addWorker 方法。addWorker()方法会在下面进行详细分析,这里可以简单理解为添加工作线程处理任务。这里的true表示:在小于核心线程数时添加worker线程,即添加核心线程。
if (addWorker(command, true))
// 添加成功则直接返回
return;
// 添加失败,重新获取 ctl 的值,防止在添加worker时状态改变
c = ctl.get();
}
// 运行到这里表示核心线程数已满,因此下面addWorker中第二个参数为false。判断线程池是否是运行状态,如果是则尝试将任务添加至 任务队列 中
if (isRunning(c) && workQueue.offer(command)) {
// 再次获取 ctl 的值,进行 double-check
int recheck = ctl.get();
// 如果线程池为非运行状态,则尝试从任务队列中移除任务
if (! isRunning(recheck) && remove(command))
// 移除成功后执行拒绝策略
reject(command);
// 如果线程池为运行状态、或移除任务失败
else if (workerCountOf(recheck) == 0)
// 执行 addWorker 方法,此时添加的是非核心线程(空闲线程,有存活时间)
addWorker(null, false);
}
// 如果线程池是非运行状态,或者 任务队列 添加任务失败,再次尝试 addWorker() 方法
else if (!addWorker(command, false))
// addWorker() 失败,执行拒绝策略
reject(command);
}
源码分析直接看注释就行了,每一行都有,灰常灰常的详细了。
从源码中可以看到,execute() 方法主要封装了 ThreadPoolExecutor 创建线程的判断逻辑,核心线程和空闲线程的创建时机,拒绝策略的执行时机都在该方法进行判断。这里通过下面的流程图对上述源码进行总结下。
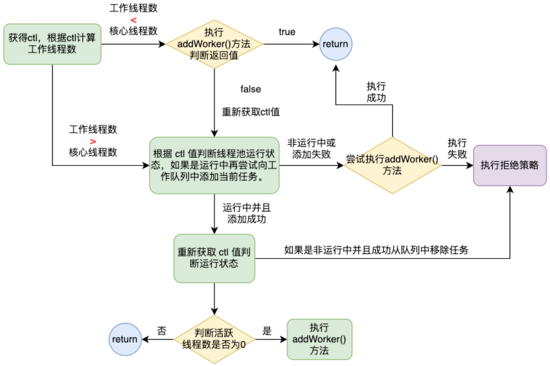
通过创建线程去执行提交的任务逻辑封装在 addWorker() 方法中。下一小节我们将来分析执行提交任务的具体逻辑。execute() 方法中还有几个方法这里说明下。
3.1.1 workerCountOf()
从 ctl 中获取活跃线程数,在第二小节已经介绍过了。
3.1.2 isRunning()
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}
依据 ctl 的值判断 ThreadPoolExecutor 是否运行状态。源码中直接判断 ctl < SHUTDOWN 是否成立,这是因为运行状态下的 ctl 最高位为1,肯定是负数;而其它状态最高位为0,肯定是正数。因此判断 ctl 的大小即可判断是否为运行态。
3.1.3 reject()
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
直接调用初始化时的 RejectedExecutionHandler 接口的 rejectedExecution() 方法。这也是典型的策略模式的使用,真正的拒绝操作被封装在实现了 RejectedExecutionHandler 接口的实现类中。这里就不进行展开。
4.2 addWorker 方法
addWorker()源码分析如下:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
// 死循环执行逻辑。确保多线程环境下在预期条件下退出循环。
for (;;) {
// 获取 ctl 值并从中提取线程池 运行状态
int c = ctl.get();
int rs = runStateOf(c);
// 如果 rs > SHUTDOWN,此时不允许接收新任务,也不允许执行工作队列中的任务,直接返回fasle。
// 如果 rs == SHUTDOWN,任务为null,并且工作队列不为空,此时走下面的 '执行工作队列中任务' 的逻辑。
// 这里设置 firstTask == null 是因为:线程池在SHUTDOWN状态下,不允许添加新任务,只允许执行工作队列中剩余的任务。
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// 获取活跃线程数
int wc = workerCountOf(c);
// 如果活跃线程数 >= 容量,不允许添加新任务
// 如果 core 为 true,表示创建核心线程,如果 活跃线程数 > 核心线程数,则不允许创建线程
// 如果 core 为 false,表示创建空闲线程,如果 活跃线程数 > 最大线程数,则不允许创建线程
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 尝试增加核心线程数,增加成功直接中断最外层死循环,开始创建worker线程
// 增加失败则持续执行循环内逻辑
if (compareAndIncrementWorkerCount(c))
break retry;
// 获取 ctl 值,判断运行状态是否改变
c = ctl.get();
// 如果运行状态已经改变,则从重新执行外层死循环
// 如果运行状态未改变,继续执行内层死循环
if (runStateOf(c) != rs)
continue retry;
}
}
// 用于记录worker线程的状态
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// new 一个新的worker线程,每一个Worker内持有真正执行任务的线程。
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 加锁,保证workerAdded状态更改的原子性
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 获取线程池状态
int rs = runStateOf(ctl.get());
// 如果为运行状态,则创建worker线程
// 如果为 SHUTDOWN 状态,并且 firstTask == null,此时将创建线程执行 任务队列 中的任务。
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 如果线程在未启动前就已经运行,抛出异常
if (t.isAlive())
throw new IllegalThreadStateException();
// 本地缓存worker线程
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
// worker线程添加成功,更改为 true 状态
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 更改状态成功后启动worker线程
if (workerAdded) {
// 启动worker线程
t.start();
// 更改启动状态
workerStarted = true;
}
}
} finally {
// 如果工作线程状态未改变,则处理失败逻辑
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
addWorker() 通过内外两层死循环判断 ThreadPoolExecutor 运行状态并通过CAS成功更新活跃线程数。这是为了保证线程池中的多个线程在并发环境下都能够按照预期的条件退出循环。
随后方法会 new 一个 Worker 并启动 Worker 内置的工作线程。这里通过workerAdded和workerStarted两个状态判断 Worker 是否被成功缓存与启动。
修改 workerAdded 过程会使用 ThreadPoolExecutor 的 mainlock 上锁保证原子性,防止多线程并发环境下, 向workers中添加数据以及获取workers数量这两个过程出现预期之外的情况。
addWorker() 启动worker线程的步骤是先new一个Worker对象,然后从中获取工作线程,再start,因此真正的线程启动过程还是在Worker对象中。
这里通过一张流程图对addWorker总结下:

addWorker 还有几个方法也在这里分析下:
4.2.1 runStateOf()
从 ctl 中获取 ThreadPoolExecutor 状态,详细分析看第二章。
4.2.2 workerCountOf()
从 ctl 中获取 ThreadPoolExecutor 活跃线程数,详细分析看第二章。
4.2.3 compareAndIncrementWorkerCount()
int c = ctl.get();
if (compareAndIncrementWorkerCount(c)) {...}
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
通过CAS的方式令 ctl 中活跃线程数+1。这里为什么只要让 ctl 的值+1就能更改线程数了呢?因为 ctl 线程数的值存储在后29位中,在不溢出的情况下,+1只会影响后29位的数值,只会令线程数+1。而不影响线程池状态。
4.2.4 addWorkerFailed()
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
// 移除worker
workers.remove(w);
// 活跃线程数-1
decrementWorkerCount();
// 尝试停止线程池
tryTerminate();
} finally {
mainLock.unlock();
}
}
private void decrementWorkerCount() {
do {} while (! compareAndDecrementWorkerCount(ctl.get()));
}
该方法是在工作线程启动失败后执行的方法。什么情况下会出现这种问题呢?在成功增加活跃线程数后并成功new Worker后,线程池状态改变为 > SHUTDOWN,既不可接受新任务,又不能执行任务队列剩余的任务,此时线程池应该直接停止。
该方法就是在这种情况下:
-
1)从workers缓存池中移除新创建的Worker;
-
2)通过死循环+CAS确保活跃线程数减1;
-
3)执行tryTerminate() 方法,尝试停止线程池。
执行完 tryTerminate() 方法后,线程池将会进入到 TERMINATED 状态。
4.2.5 tryTerminate()
final void tryTerminate() {
for (;;) {
int c = ctl.get();
// 如果当前线程池状态为以下之一,无法直接进入 TERMINATED 状态,直接返回false,表示尝试失败
if (isRunning(c) || runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
// 如果活跃线程数不为0,中断所有的worker线程,这个会在下面详细讲解,这里会关系到 Worker 虽然继承了AQS,但是并未使用里面的CLH的原因。
if (workerCountOf(c) != 0) {
interruptIdleWorkers(ONLY_ONE);
return;
}
// 加上全局锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 首先通过 CAS 将 ctl 改变成 (rs=TIDYING, wc=0),因为经过上面的判断保证了当先线程池能够达到这个状态。
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
// 钩子函数,用户可以通过继承 ThreadPoolExecutor 实现自定义的方法。
terminated();
} finally {
// 将 ctl 改变成 (rs=TERMINATED, wc=0),此时线程池将关闭。
ctl.set(ctlOf(TERMINATED, 0));
// 唤醒其它线程,唤醒其实也没用了,其它线程唤醒后经过判断得知线程池 TERMINATED 后也会退出。
termination.signalAll();
}
return;
}
} finally {
// 释放全局锁
mainLock.unlock();
}
}
}
五、Worker 内置类分析
5.1 Worker对象分析
Worker对象的源码分析:
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
// 工作线程
final Thread thread;
// 提交的待执行任务
Runnable firstTask;
// 已经完成的任务量
volatile long completedTasks;
Worker(Runnable firstTask) {
// 初始化状态
setState(-1);
this.firstTask = firstTask;
// 通过线程工厂创建线程
this.thread = getThreadFactory().newThread(this);
}
// 执行提交任务的方法,具体执行逻辑封装在 runWorker() 中,当addWorker() 中t.start()后,将执行该方法
public void run() {
runWorker(this);
}
// 实现AQS中的一些方法
protected boolean isHeldExclusively() { ... }
protected boolean tryAcquire(int unused) { ... }
protected boolean tryRelease(int unused) { ... }
public void lock() { ... }
public boolean tryLock() { ... }
public void unlock() { ... }
public boolean isLocked() { ... }
// 中断持有的线程
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try { t.interrupt(); }
catch (SecurityException ignore) {}
}
}
}
从上面源码可以看出:Worker实现了Runnable接口,说明Worker是一个任务;Worker又继承了AQS,说明Worker同时具有锁的性质,但Worker并没有像ReentrantLock等锁工具使用了CLH的功能,因为线程池中并不存在多个线程访问同一个Worker的场景,这里只是使用了AQS中状态维护的功能,这个具体会在下面进行详细说明。
每个Worker对象会持有一个工作线程 thread,在Worker初始化时,通过线程工厂创建该工作线程并将自己作为任务传入工作线程当中。因此, 线程池中任务的运行其实并不是直接执行提交任务的run()方法,而是执行Worker中的run()方法,在该方法中再执行提交任务的run()方法。
Worker 中的 run() 方法是委托给 ThreadPoolExecutor 中的 runWorker() 执行具体逻辑。
这里用一张图总结下:
-
Worker本身是一个任务,并且持有用户提交的任务和工作线程。
-
工作线程持有的任务是this本身,因此调用工作线程的start()方法其实是执行this本身的run()方法。
-
this本身的run()委托全局的runWorker()方法执行具体逻辑。
-
runWorker()方法中执行用户提交任务的run()方法,执行用户具体逻辑。
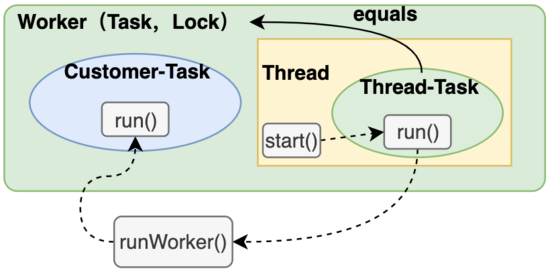
5.2 runWorker 方法
runWorker() 源码如下所示:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
// 拷贝提交的任务,并将 Worker 中的 firstTask 置为 null,便于下一次重新赋值。
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock();
boolean completedAbruptly = true;
try {
// 执行完持有任务后,通过 getTask() 不断从任务队列中获取任务
while (task != null || (task = getTask()) != null) {
w.lock();
try {
// ThreadPoolExecutor 的钩子函数,用户可以实现 ThreadPoolExecutor,并重写 beforeExecute() 方法,从而在任务执行前 完成用户定制的操作逻辑。
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 执行提交任务的 run() 方法
task.run();
} catch (RuntimeException x) {
...
} finally {
// ThreadPoolExecutor 的钩子函数,同 beforeExecute,只不过在任务执行完后执行。
afterExecute(task, thrown);
}
} finally {
// 便于任务回收
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 执行到这里表示任务队列中没了任务,或者线程池关闭了,此时需要将worker从缓存冲清除
processWorkerExit(w, completedAbruptly);
}
}
runWorker() 是真正执行提交任务的方法,但其并没有通过Thread.start()方法执行任务,而是直接执行任务的run()方法。
runWorker() 会从任务队列中不断获取任务并执行。
runWorker() 提供了两个钩子函数,如果 jdk 的 ThreadPoolExecutor 无法满足开发人员的需求,开发人员可以继承 ThreadPoolExecutor并重写beforeExecute()和afterExecute()方法定制任务执行前需要执行的逻辑。比如设置一些监控指标或者打印日志等。
5.2.1 getTask()
private Runnable getTask() {
boolean timedOut = false;
// 死循环保证一定获取到任务
for (;;) {
...
try {
// 从任务队列中获取任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
5.2.2 processWorkerExit()
private void processWorkerExit(Worker w, boolean completedAbruptly) {
...
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
// 从缓存中移除worker
workers.remove(w);
} finally {
mainLock.unlock();
}
// 尝试停止线程池
tryTerminate();
...
}
六、shutdown()执行流程
线程池拥有两个主动关闭的方法;
shutdown():关闭线程池中所有空闲Worker线程,改变线程池状态为SHUTDOWN;
shutdownNow():关闭线程池中所有Worker线程,改变线程池状态为STOP,并返回所有正在等待处理的任务列表。
这里为什么要将Worker线程区分为空闲和非空闲呢?
由上面的 runWorker() 方法,我们知道Worker线程在理想情况下会在while循环中不断从任务队列中获取任务并执行,此时的Worker线程就是非空闲的;没有在执行任务的worker线程则是空闲的。因为线程池的SHUTDOWN状态不允许接收新任务,只允许执行任务队列中剩余的任务,因此需要中断所有空闲的Worker线程,非空闲线程则持续执行任务队列的任务,直至队列为空。而线程池的STOP状态既不允许接受新任务,也不允许执行剩余的任务,因此需要关闭所有Worker线程,包括正在运行的。
6.1 shutdown()
shutdown() 源码如下:
public void shutdown() {
// 上全局锁
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 校验是否有关闭线程池的权限,这里主要通过 SecurityManager 校验当前线程与每个 Worker 线程的 “modifyThread” 权限
checkShutdownAccess();
// 修改线程池状态
advanceRunState(SHUTDOWN);
// 关闭所有空闲线程
interruptIdleWorkers();
// 钩子函数,用户可以继承 ThreadPoolExecutor 并实现自定义钩子,ScheduledThreadPoolExecutor便实现了自己的钩子函数
onShutdown();
} finally {
mainLock.unlock();
}
// 尝试关闭线程池
tryTerminate();
}
shutdown() 将 ThreadPoolExecutor 的关闭步骤封装在几个方法中,并且通过全局锁保证只有一个线程能主动关闭 ThreadPoolExecutor。ThreadPoolExecutor 同样提供了一个钩子函数 onShutdown() 让开发人员定制化关闭过程。比如ScheduledThreadPoolExecutor 就会在关闭时对任务队列进行清理。
下面对其中的方法进行分析。
checkShutdownAccess()
private static final RuntimePermission shutdownPerm = new RuntimePermission("modifyThread");
private void checkShutdownAccess() {
SecurityManager security = System.getSecurityManager();
if (security != null) {
// 校验当前线程的权限,其中 shutdownPerm 就是一个具有 modifyThread 参数的 RuntimePermission 对象。
security.checkPermission(shutdownPerm);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers)
// 校验所有worker线程是否具有 modifyThread 权限
security.checkAccess(w.thread);
} finally {
mainLock.unlock();
}
}
}
advanceRunState()
// targetState = SHUTDOWN
private void advanceRunState(int targetState) {
for (;;) {
int c = ctl.get();
// 判断当前线程池状态 >= SHUTDOWN是否成立,如果不成立的话,通过CAS进行修改
if (runStateAtLeast(c, targetState) ||
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))
break;
}
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
该方法中判断线当前程池状态 >= SHUTDOWN 是否成立其实也是用到了之前线程池状态定义的技巧。对于非运行状态的其它状态都为正数,且高三位都不同,TERMINATED(011) > TIDYING(010) > STOP(001) > SHUTDOWN(000)而高三位的大小取决了整个数的大小。因此对于不同状态,无论活跃线程数是多少,线程池的状态始终决定着 ctl 值的大小。即TERMINATED 状态下的 ctl 值 > TIDYING 状态下的 ctl 值恒成立。
interruptIdleWorkers()
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
// 判断worker线程是否已经被标记中断了,如果没有,则尝试获取worker线程的锁
if (!t.isInterrupted() && w.tryLock()) {
try {
// 中断线程
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
// 如果 onlyOne 为true的话最多中断一个线程
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
刚方法会尝试获取Worker的锁,只有获取成功的情况下才会中断线程。这里也与前面说的Worker虽然继承了AQS但却没使用CLH有关,后面会进行分析。
tryTerminate() 方法已经在前面分析过了,这里不过多叙述。
6.2 shutdownNow()
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)

最后
面试前一定少不了刷题,为了方便大家复习,我分享一波个人整理的面试大全宝典
- Java核心知识整理

Java核心知识
- Spring全家桶(实战系列)

- 其他电子书资料

Step3:刷题
既然是要面试,那么就少不了刷题,实际上春节回家后,哪儿也去不了,我自己是刷了不少面试题的,所以在面试过程中才能够做到心中有数,基本上会清楚面试过程中会问到哪些知识点,高频题又有哪些,所以刷题是面试前期准备过程中非常重要的一点。
以下是我私藏的面试题库:

小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-4zIpv7i3-1711699885737)]
[外链图片转存中…(img-w5kHrjnH-1711699885738)]
[外链图片转存中…(img-ULqRWs1w-1711699885738)]
[外链图片转存中…(img-8WvZQ7Yv-1711699885739)]
[外链图片转存中…(img-Qv5zyFnY-1711699885739)]
[外链图片转存中…(img-vmhWg1h1-1711699885740)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-CxDyrDuZ-1711699885740)]
最后
面试前一定少不了刷题,为了方便大家复习,我分享一波个人整理的面试大全宝典
- Java核心知识整理
[外链图片转存中…(img-HZG5hjch-1711699885740)]
Java核心知识
- Spring全家桶(实战系列)
[外链图片转存中…(img-SjgFS0tG-1711699885741)]
- 其他电子书资料
[外链图片转存中…(img-TXMvQgDr-1711699885741)]
Step3:刷题
既然是要面试,那么就少不了刷题,实际上春节回家后,哪儿也去不了,我自己是刷了不少面试题的,所以在面试过程中才能够做到心中有数,基本上会清楚面试过程中会问到哪些知识点,高频题又有哪些,所以刷题是面试前期准备过程中非常重要的一点。
以下是我私藏的面试题库:
[外链图片转存中…(img-8Yya61CE-1711699885741)]















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









