







最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:

给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
很多文章都是用MNIST数据集作为深度学习届的“Hello World”程序,但是这个数据集有一个很大的特点:它是一个典型的多分类问题(一共有10个分类),在刚开始接触深度学习时,我人为应从最简单的二分类问题着手。
在深度学习框架方面,目前比较流行的是Tensorflow,Keras,PyTorch,Theano等,但是我建议新手入门,可以从Keras入手,然后进阶时转移到Tensorflow上,实际上,Keras的后端是可以支持Tensorflow和Theano,可以说,Keras是在Tensorflow和Theano的基础上进一步封装,更加的简单实用,更容易入门,通常几行简单的代码就可以解决一个小型的项目问题。
1. 准备数据集
最经典的二分类数据集就是Kaggle竞赛中的“猫狗大战”数据集(train set有25K张图片,test set: 12.5K),此处按照原始博文的做法,我从train_set中选取1000张Dog的照片+1000张Cat照片作为我们新的train set,选取400张Dog+400张Cat照片作为新的test set。所以train和test两个文件夹下都有两个子文件夹(cats和dogs子文件夹)。当然,选取是随机的,也是用代码来实现的,准备小数据集的代码如下:
def dataset\_prepare
先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前在阿里
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

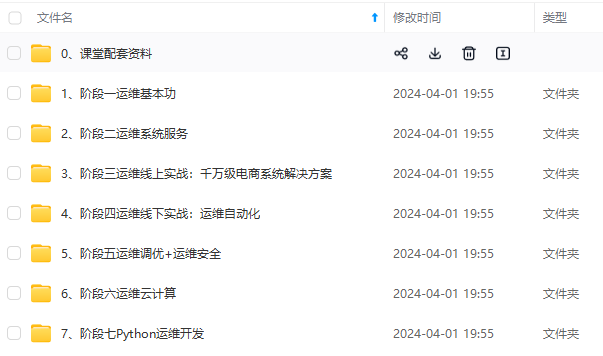
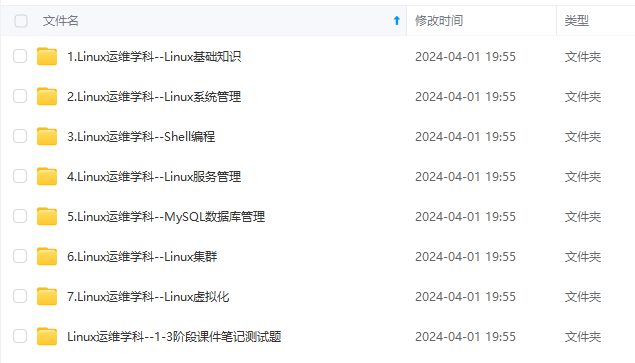
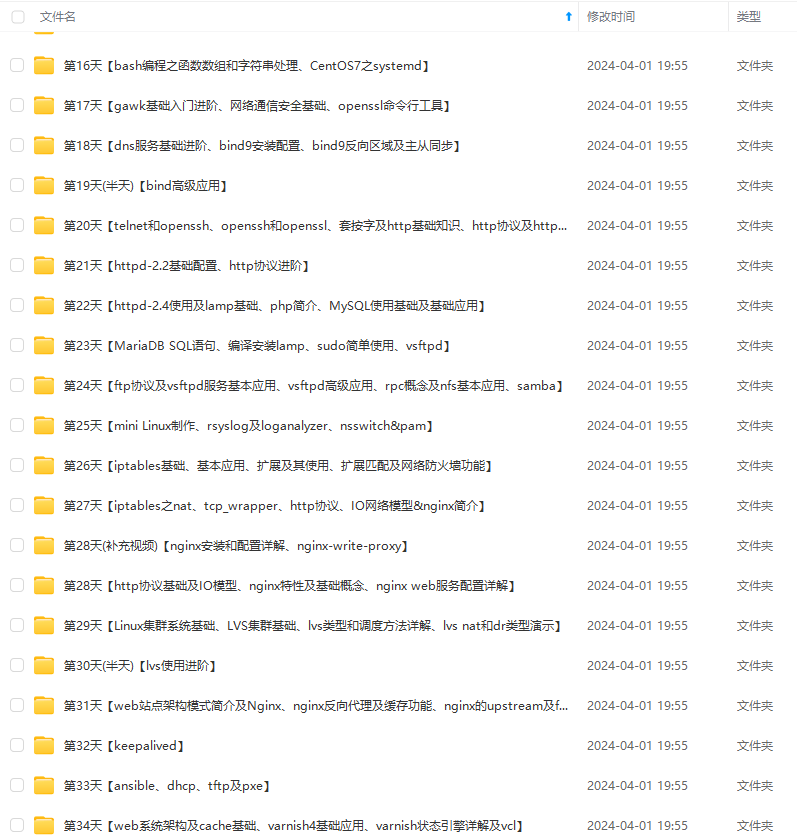
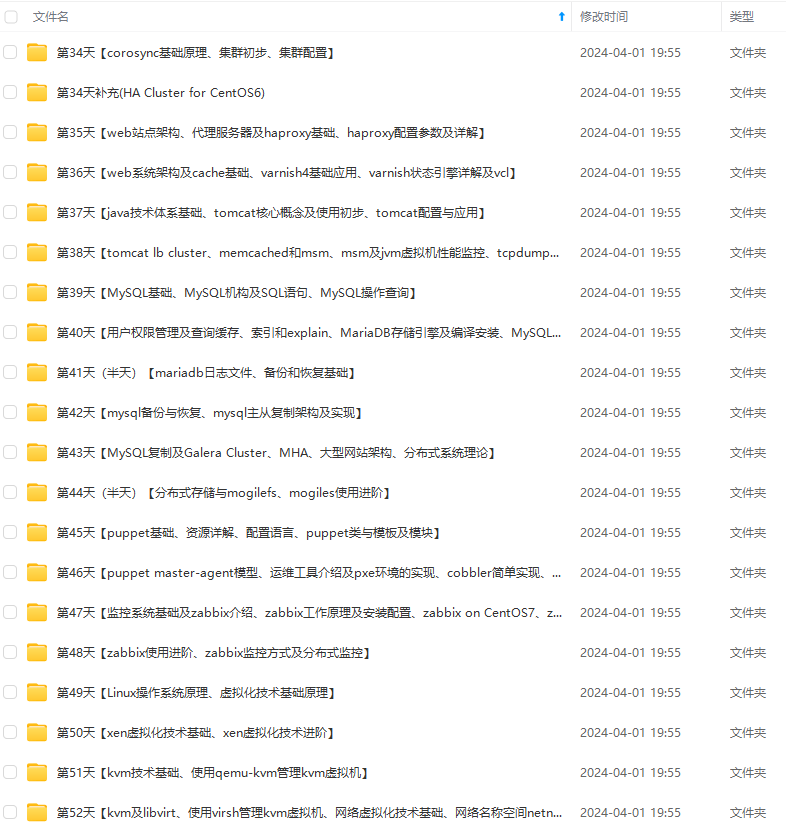
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/topics/618542503)**















 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









