







上一部分说完了常见的传感器硬件,接下来说传感器的软件方面方面。
本部分主要分为两部分:1.计算机视觉与神经网络;2.感知应用(纯视觉部分)
目录
1.计算机视觉与神经网络
计算机视觉(CV)大家都不陌生,是近来发展迅速的科学之一。其内容包含了对于视觉信息的获取、传输、处理、存储及处理与理解。

边缘常常发生于图像的一阶微分最大值、二阶微分为零,但往往由于噪声影响,我们一般显示去掉高频的噪声,再进行处理。我们常用的离散信号差分滤波卷积核常用到Robert算子、Prewitt算子、Sobel算子、拉普拉斯算子等等。
对于分割任务,有基于阈值的分割、基于区域的分割、基于边缘检测的分割、基于深度模型的分割等等。这里就不再展开。
计算机视觉在自动驾驶领域中有着多种多样的应用,例如双目多目相机的深度获取及驾驶员状态监测、点云的处理、对交通参与者的识别、跟踪与运动估计、信号灯检测、可行驶区域检测、高清地图绘制等等。
本部分主要介绍深度学习中的神经网络方法,自从2012年AlexNet在图像领域的成功,卷积神经网络得到我们的重视。(卷积与互相关区别仅为卷积核是否翻转,所以卷积也有反映相关性的作用,从而提取特征)
本部分涉及
激活函数:常用激活函数(激励函数)理解与总结_tyhj_sf的博客-CSDN博客_激活函数
网络结构:11种主要神经网络结构图解_喜欢打酱油的老鸟的博客-CSDN博客_神经网络结构图
正向逆向传播:神经网络正向与反向传播_小小小~的博客-CSDN博客_神经网络正向传播和反向传播
损失函数:神经网络损失函数汇总_猿代码_xiao的博客-CSDN博客_神经网络常用的损失函数
最经典的几个卷积神经网络:
Vgg16(2014年):创新点在于深度更深,使用3*3卷积核代替5*5甚至7*7卷积核,引入了更强的非线性;

GoogleNet:最出名的就是其中的Inception结构(inception也是盗梦空间电影名字),首次说明了1*1卷积核的作用, 特征抽取,降维(filter对应的channel)还用于修正线性激活(ReLU),使用了特征拼接,并加入了两个辅助分类器帮助克服梯度消失问题,使得网络更深。

ResNet(2015):意义重大的网络,加入了残差结构的bottleneck,缓解了梯度消失的问题,使得网络可以更深(1000层以上)、不像之前网络中使用DropOut而使用BN来正则化。
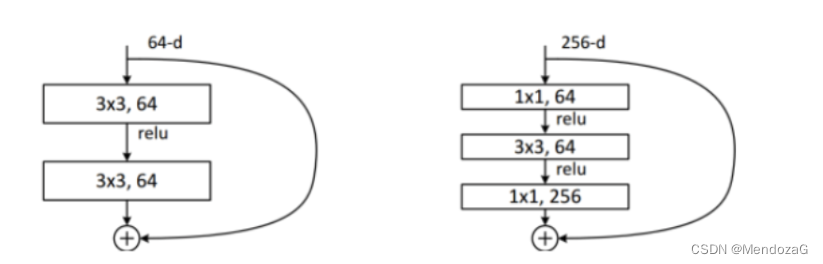
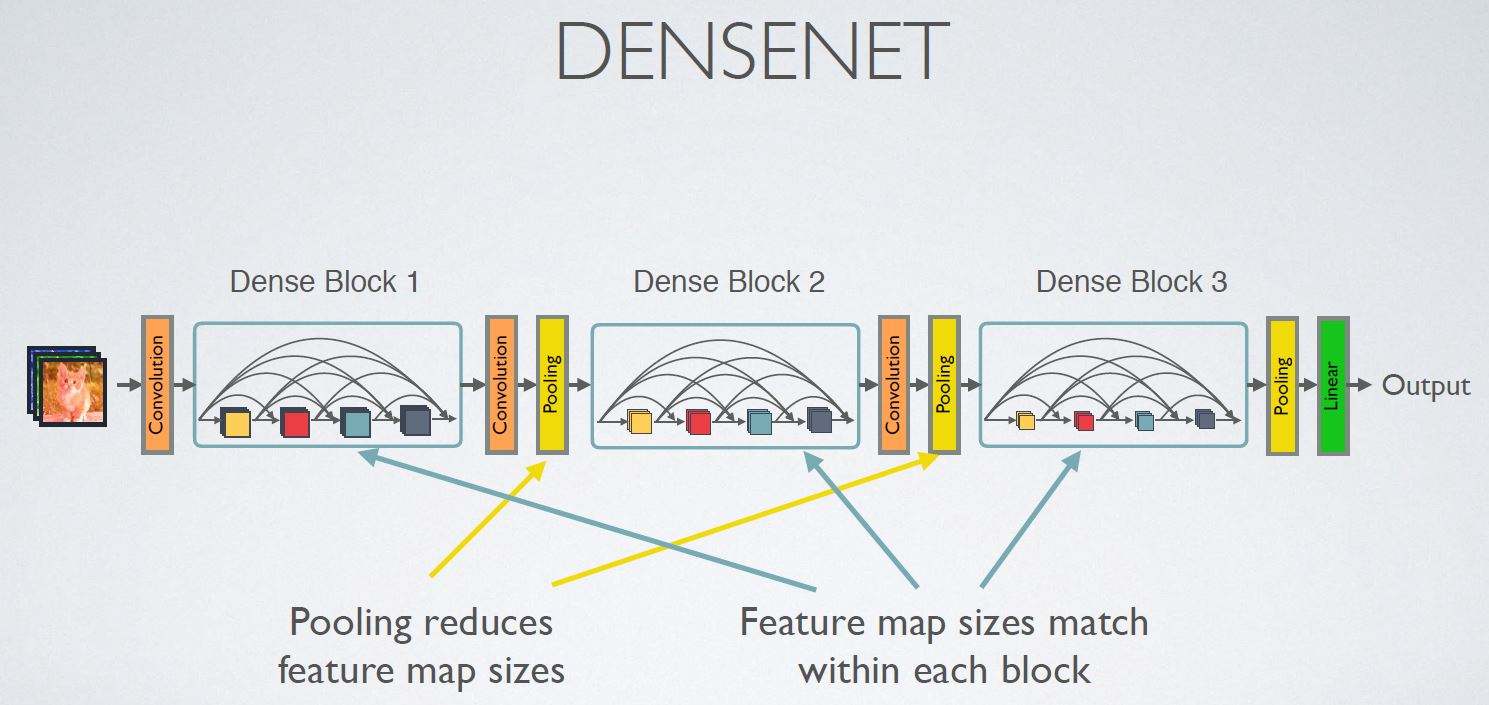
DenseNet(2017):不再是加深网络和加宽网络结构(Inception),而是通过特征密集单元混,每一层输入都是上一层的输出的拼接,效果好但是对于内存要求高很多。
SENet:Squeeze操作压缩为实数(宽度为channel)再通过excitation生成不同的权重,再经过Scale缩放,完成在通道上原始特征的重标定,建立了特征通道之间的联系。

2.感知应用(纯视觉部分)
我们之前提到过,感知应用在目标检测、可行驶区域、车道线、红绿灯检测等等。本部分我们主要使用深度学习工具。
2.1纯视觉方案(YOLO,SSD等)
由于RCNN的提出Region Proposal,提取候选区,再对候选区进行特征提取,使用简单的AlexNet进行fine-tuning特征学习,最后通过SVM输出结果(SVM效果更好,比softmax更好),这是经典的2stage方法。缺点就是速度慢,不能做到实时处理。因为部署原因一般要求我们要能够实时处理,所以这里只分享两种经典的1stage网络。
先来说YOLOv1,发布于2016年,是典型的1stage算法,它分为检测和训练两个部分,其中将目标的detection问题转化为回归问题解决。

将输入的图像先进行resize,划分成s*s的grid cell经过神经网络,得到物体种类的bbox的排列,通过NMS,只显示全概率最大的检测结果。(对于每一个grid cell 只有n个bbox是确定的)

对于结果的预测一般评价指标是依赖于Pascal VOC(20类)和COCO(80类)的。
其网络设计如下:
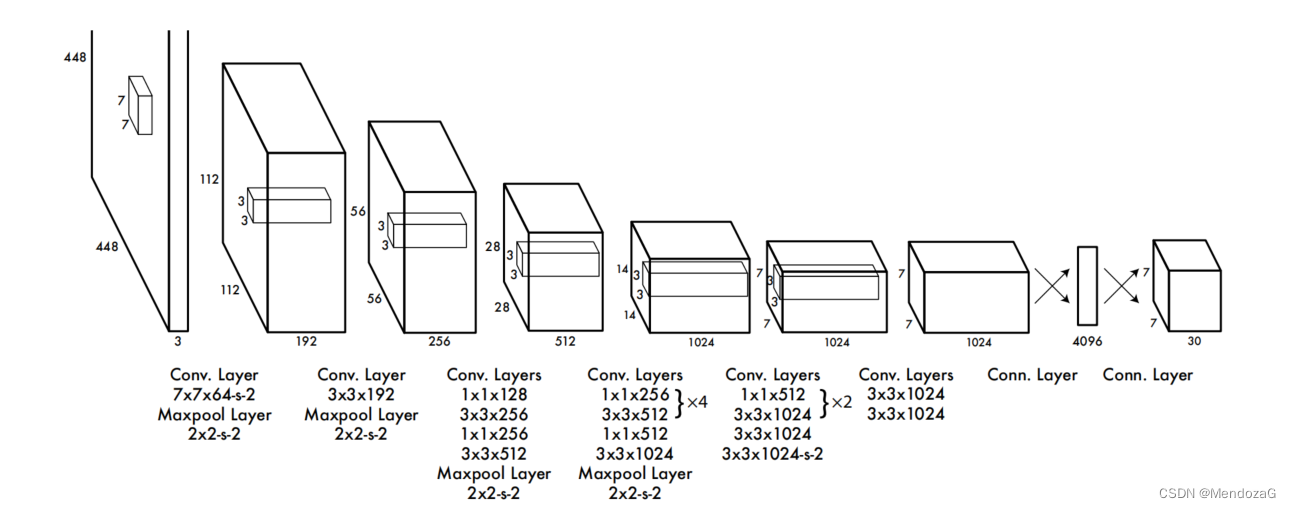
首先就是把图像resize成448*488,包含了24层卷积特征提取层和2层FC层,最终回归得到7*7*30的tensor。
其中7*7就是grid cell对应的大小,30包含的信息为:对于VOC20种分别有confidence、x、y、w、h即bbox的位置和大小共五个。还有二十种目标对应的条件概率。因为这里一个grid cell只产生两个bbox,所以一共是5*2+20=30维度。
所以若如论文中分割为7*7 grid cell的话,会产生7*7*30的输出。而对于每一个7*7中我们采用NMS(从输出的左侧看)提取出每个grid中最可能的结果。
其损失函数定义为:

第一项是负检测bbox中心点(x,y)误差,第二项是检测宽高(w,h)定位误差,其中加根号的原因是为了使得小框也敏感,第三四项代表了回归置信度误差,分为正样本和负样本两项,负责检测物体的bbox和不负责检测物体的bbox;第五项则代表检测物体的grid cell分类误差。

YOLO相比RCNN,最明显的是速度较快,而对比RCNN它遍历了所有图像区域而非提取某感性兴趣区域,所以其迁移能力很好,但由于每个框只能检测一种物体,对于小而密集的物体效果会很差,从上图中也能看出,YOLO对于背景的错误率要比RCNN要好很多,得益于它遍历图像的全部。

YOLO加上Fast —RCNN取得了很好的效果。
YOLO在原作者下又迭代了两个版本,由于不愿意被用于军事监控等用途,不再更新,目前YOLO已迭代到第七个版本(声称),目前公认较为完善的是v5版本,
v6版本是由美团最近发布的,感兴趣可以看看我的这篇文章:
接下来介绍SSD算法(Single SHOT Multibox Detection)

不同于YOLO,SSD将每次卷积得到的特征图都进行检测,最终采用卷积层做检测并且采用了不同尺度比例的候选框。下图是不同尺度的feature maps。猫猫小使用更精细的grid cell,狗狗大采用大的grid cell,有scale关系。(值得注意的是对于VOC一共有21类置信度,是因为加入了背景)

输入需要缩放至300*300,采用修剪的vgg16 backbone。1*1卷积层和3*3卷积层的使用。

下面这种流程会更清晰一些:
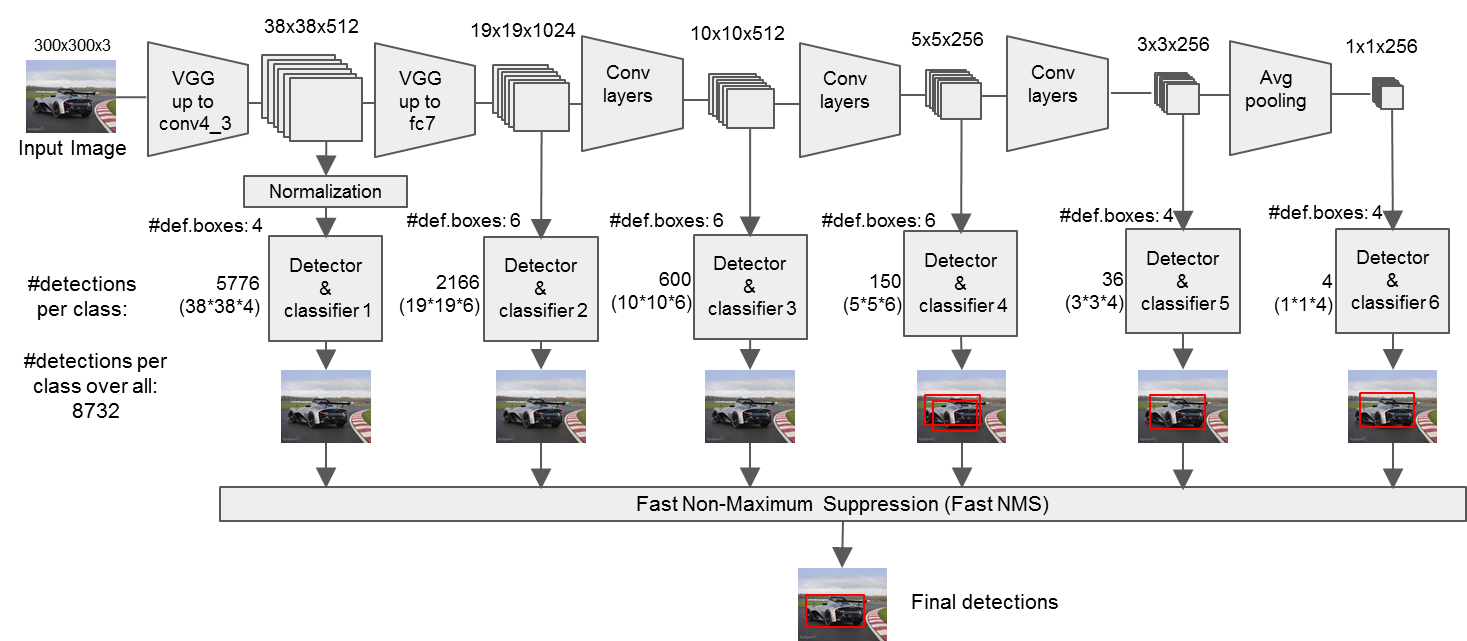
不同特征层default box的scale和aspect:

会生成8732个的default box。
Loss function:

第二项定位损失的loss(与Faster RCNN一样):

第一项的confidence的loss是多类别的softmax loss:

在PASCAL VOC2017测试集的结果:
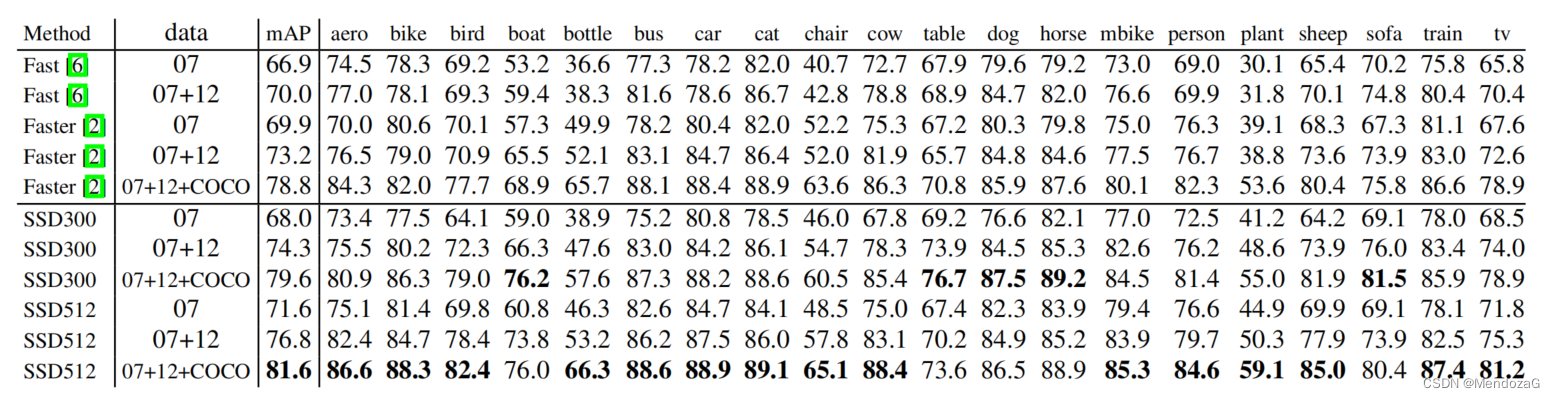
为什么SSD性能更好,作者用控制变量进行测试:

可以看出数据增强是最为关键的影响指标。
速度测试:(batch size 8 using Titan X and cuDNN v4 with Intel Xeon E5-2667v3@3.20GHz.)

















 2468
2468











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











