






 本文详细介绍了语音通信的过程,包括声音的采集、信号处理(降噪、回声消除、自动增益)、音频压缩与网络传输。重点讨论了噪声分类、降噪算法(传统与深度学习)、回声消除原理及挑战、自动增益控制的应用,并提到了网络传输中的抗丢包策略。
本文详细介绍了语音通信的过程,包括声音的采集、信号处理(降噪、回声消除、自动增益)、音频压缩与网络传输。重点讨论了噪声分类、降噪算法(传统与深度学习)、回声消除原理及挑战、自动增益控制的应用,并提到了网络传输中的抗丢包策略。
该文章主要讲述了语音通信过程中声音是如何在通话双方之间进行传输和处理的。
声音从通话的一方发出到被通话的另一方听到主要经过上图1所示流程。包括声音的采集、声音的信号处理、网络传输(压缩编码、抗丢包抖动)、解码、声音播放这几个模块,其中声音的信号处理主要是回声消除、降噪和自动增益,也就是俗称的“3A”处理。
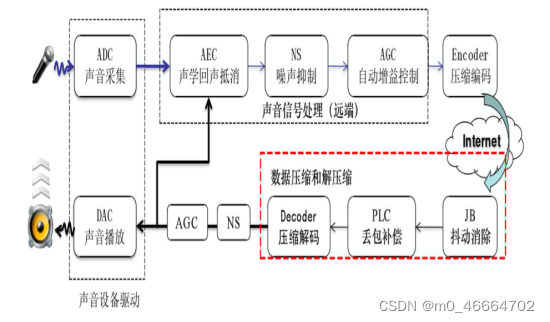
一、声音采集
1.1 声音的产生
声音是由物体振动而产生的,而人声就是由我们的声带振动产生的。
声音的三要素是频率、振幅和波形。频率代表音调的高低,振幅代表响度,波形代表音色。声带的振动频率越大,音调就越大,声音听起来就很尖,响度就是声音的大小或者说是能量,音色则可以理解为声音特色,我们可以分辨不同人的声音,就是因为每个人的声音音色不同。
1.2 声音的采集
我们现在一般用麦克风来实现声音的采集。那如何通过麦克风来采集声音呢?
- 麦克风里面有一层碳膜,非常薄而且十分敏感。声音通过空气传播到这层碳膜,碳膜在受到声音的挤压时也会发出振动,在碳膜的下方就是一个电极,碳膜在振动的时候会接 触电极,接触时间的长短和频率与声波的振动幅度和频率有关,这样就完成了声音信号到电信号(也叫做模拟信号)的转换。
- 从电信号到数字信号就是通过所谓“模数转换器”来完成。“模数转换器”通过 PCM(Pulse Code Modulation)脉冲编码调制对连续变化的模拟信号进行抽样、量化和编码转换成离散的数字信号。其中抽样涉及到采样率,采样率越大代表采样点数越多;量化涉及到采样位深,也就是采用多少bit来表示一个采样点,位数越多就越精准。
二、声音的信号处理
采集到的的声音可能包含噪声和回声,也有可能采集到的声音太小。如果不做处理直接传给接收端,则接收端就会有不好的通话体验。所以要对采集到的声音进行降噪、回声消除和自动增益等处理。
2.1 语音降噪ANS
噪声是一个相对概念,所有你不想要的声音都可以归为噪声。在语音通信过程中,除了人声,其他的声音都可以认为是噪声。
2.1.1 噪声分类
- 从通信系统的角度来说,噪声可以分为加性噪声和乘性噪声。 加性噪声可简单理解为和人声是不相关的,我们常见的自然噪声、人造的噪声如电子元器件发出的热噪声等都是这种。乘性噪声则是噪声和信号是相关联的,比如信号的衰减、房间的混响、多普勒效应等。
- 我们主要处理的是加性噪声。加性噪声种类则成千上万,但从降噪方法的选择角度上来说,我们可以按照噪声是否平稳,把噪声分为两类:稳态噪声和非稳态噪声。稳态噪声就是一直存在且基本上响度、频率分布等声学特性都不随时间变化或者变换缓慢,例如一些设备底噪和风扇声。非稳态噪声这些声学特征就会随着时间变化而变化,例如街道噪声、车站噪声、敲击声和开门声等。
2.1.2 传统降噪算法
- 谱减法:该方法核心思想是先取一段非人声段音频,记录下噪声的频谱能量,然后从所有的音频频谱中减去这个噪声频谱能量。这种方法对稳态噪声比较有效果。但如果是非稳态噪声就会导致有的地方频谱减少了噪声有残留,有的地方频谱减多了人声有损伤。所以谱减法一般用于离线稳态噪声的降噪处理。离线的时候可以人工对音频进行分片处理,在每一个分片中噪声可以控制成稳态的。而在实时音频处理的时候,噪声状态经常是随时间变化的,我们很难让噪声一直保持绝对稳态。
- 基于统计模型的实时降噪算法:这类算法是实时音频降噪时最常用的算法类别。算法的思想就是利用统计的方法估算出音频频谱中每个频点所对应的噪声和语音的分量。基于统计的降噪方法其实都是针对相对平稳的噪声进行去除,且为了方便找出噪声和人声的直观统计区别,一般都需要基于两个假设(假设1:噪声比人声更平稳,假设2:噪声是加性噪声)。所以基于这两个假设,我们就可以解释很多我们平时在使用这些降噪算法时所遇到的现象。比如噪声中的瞬态噪声很难被抑制,比如敲桌子的声音、键盘声之类的。
- 子空间算法:该算法主要是针对一些已知噪声类型,量身定做一个降噪算法。其思想就是把噪声和人声投影到一个高纬度的空间,让本来不容易分离的信号变成在高纬度占据一个可分的子空间,从而可分的信号。这类算法包括非负矩阵分解和字典法建模等。什么时候会用到这种算法呢?比如你只是要去除风噪这一种噪声,你可以用非负矩阵分解的方式单独为风噪建模,从而模型会自动消除音频中的风噪。这个在去风噪的场景下效果也是不错的。但这类方法缺点也很明显,每一种噪声都得单独建模,在噪声类型不定的情况下就很难穷尽达到好的效果。
2.1.3 深度学习降噪算法
传统算法通过统计的方法对噪声进行估计,并可以对稳态噪声起到比较好的降噪作用,但是在非稳态噪声和瞬态噪声等噪声类型下,传统降噪算法往往不能起到比较好的效果。
最近几年,随着 AI 技术的不断演进,在降噪等音频处理领域,出现了很多基于人工神经网络模型的降噪算法。这些 AI 算法在降噪能力上较传统算法都有很大的提升。但 AI 降噪算法和很多其它AI 算法一样,在部署的时候也会受到诸如设备算力、存储体积等条件的限制。
使用AI模型进行降噪主要是分为三个过程:
- AI 降噪模型的构建:常用的结构包括 DNN、CNN 和 RNN 等。AI 降噪模型在结构设计时,可以选择其中一种,也可以把这些结构组合使用。
- AI 降噪模型的训练:一般采用有监督的训练方式,并以带噪语音作为模型的输入、纯净语音作为训练的目标。利用反向传播结合梯度下降的方法不断提升模型预估和纯净语音的相似程度。这个相似程度我们一般用,例如 MSE 等形式的 Loss 来表示,并且 Loss 越小,模型得到的结果就越接近于纯净语音。
- 使用训练好的模型进行降噪。
一个 AI 降噪模型的设计者要设计的东西:
- 一个 AI 降噪的模型,包括模型的预处理和后处理流程;
- 一个合适的 Loss,用于迭代计算模型的参数;
- 一个合适的语音信号和噪声信号的数据库,用于模型训练。
在实时音频信号系统中,降噪模型需要考虑到模型的因果性。在移动端部署时,由于算力和存储空间受到限制,我们需要通过对模型的输入进行降维、模型参数进行量化等操作来进行设备适配。当然我们也可以通过一些现成的工具来快速实现 AI 降噪模型的部署。
2.2 回声消除AEC
2.2.1 回声的形成
图 2 中 B 端的人在说话,说话的声音会被 B 端的麦克风采集。麦克风采集到的语音信号转为数字信号后经过网络传输到 A 端,在 A 端的扬声器会把收到的语音信号转成声波播放出来,同时 A 端的麦克风又会把扬声器的声音采集回来,通过网络又传回给了 B 端。这时 B 端的人就会听到自己发出去的声音,我们把这个声音就叫做回声。
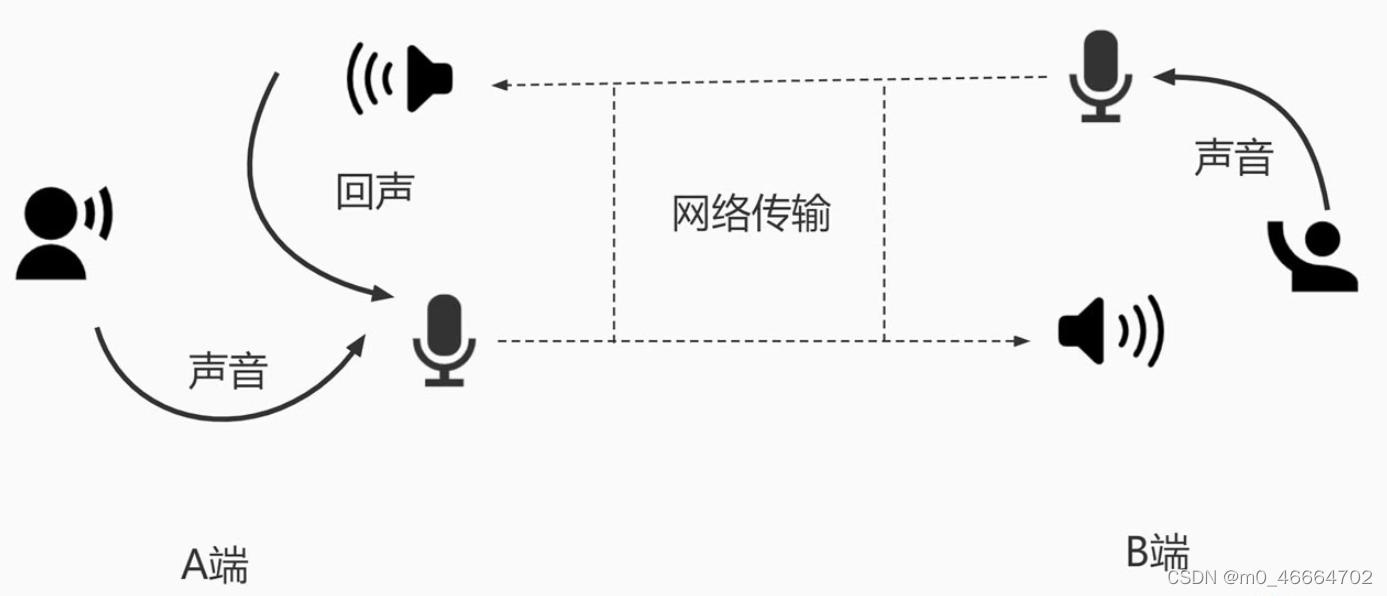
2.2.2 回声消除的基本原理
在近端接收到的远端的声音信号我们把它叫做参考信号 x ( n ) x(n) x(n)在经过扬声器播放、空气传播、房间墙体反射、麦克风采集后,参考信号不可避免地会产生很多变化。我们把这个变化用数学的方式来表达就叫做回声路径的传递函数,一般记作 f f f。也就是参考信号经过 f f f的作用变成了回声。那想去掉回声,就需要估计出这个 f f f。也就是把形成回声的这个环境估计出来。
但是在真实的场景中传递函数的估计是一件比较困难的事情。这是因为回声消除算法需要面对复杂的、时变的声学环境。比如,扬声器和麦克风的播放失真、采集失真会给声学信号带来很多非线性的变化,并且设备、系统调度的不稳定可能造成回声和远端接收信号的延迟抖动。同时诸如房间的混响、设备所处位置的变化,都会带来回声路径的变化。
2.2.3 回声消除的算法
由于回声环境的复杂性和时变性,所以现在业界大部分都是使用以自适应滤波为基础的回声消除方法。自适应滤波的核心思想就是用实时更新的滤波器的系数来模拟真实场景的回声路径,然后结合远端信号来估计出回声信号,再从近端采集的混合信号中减去估计的回声,从而达到消除回声的目的。
2.2.4 回声消除的挑战和解决方法
- 延迟估计,由于滤波器的长度不能设置的过大,所以需要做时延估计。如果在滤波器的长度内参考信号和近端信号不能对齐的话,回声就不能消除。所以准确快速的时延估计在回声消除中尤为重要。
- 双讲检测,第二个问题是双讲。所谓“双讲”,就是远端和近端同时说话或者说两侧都有明显的声音。那在这个时候麦克风采集的信号除了回声还有混入了近端的声音。而回声消除算法(例如NLMS)是依赖于回声信号来进行估计的,而这时如果用麦克风采集的信号作为回声信号,就会导致滤波器无法收敛到正确的位置,从而产生回声泄漏或近端声音被损伤。
- 非线性,第三个问题是我们看到 NLMS 等算法中实际上估计的是一个线性的滤波器。但是我们之前有讲到扬声器、麦克风等都可能会导致一些非线性的变换。那么这时线性滤波器可能就无法处理了。一般来说一些廉价或者说声学特性比较差的设备导致的非线性失真比较多,所以出现回声的概率也更大。针对非线性的问题需要做非线性处理,而这又需要兼顾不同设备、环境,是一件很有挑战的事情。
2.3 自动增益AGC
由于音频采集的差异,一般表现为音量过大导致爆音,采集音量过小对端听起来很吃力。在音视频通话的现实场景中,不同的参会人说话音量各有不同,参会用户需要频繁的调整播放音量来满足听感的需要,戴耳机的用户随时承受着大音量对耳朵的 “暴击”。因此,对发送端音量的均衡在上述场景中显得尤为重要,优秀的自动增益控制算法能够统一音频音量大小,极大地缓解了由设备采集差异、说话人音量大小、距离远近等因素导致的音量的差异。
自动增益算法设计需要注意的点:
- 音频增益后不能因为使用了较大的增益值而失真
- 对噪声不进行增益或者说增益量远远小于对人声的增益
- 在音频音量时大时小的时候,都够快速统一音频音量的大小
自动增益控制是我认为链路最长,最影响音质和主观听感的音频算法模块,一方面是 AGC 必须作用于发送端来应对移动端与 PC 端多样的采集设备,另一方面 AGC 也常被作为压限器作用于接收端,均衡混音信号防止爆音。
三、音频网络传输
3.1 压缩编码
如果直接发送处理后的音频数据,由于采集到的声音都是采用较大的采样率和采样位深导致会消耗很大的带宽来进行数据的传输。而音频数据其实是存在很多冗余信息,因此可以在保证音质不受到较大损伤的情况下,采用较小的采样位深来表示一个采样点,达到数据压缩的目的。
压缩算法包括有损压缩和无损压缩。 无损压缩是指解压后的数据可以完全复原。在常用的压缩格式中,用得较多的是有损压缩,有损压缩是指解压后的数据不能完全复原,会丢失一部分信息,压缩比越小,丢失的信息就越多,信号还原后的失真就会 越大。根据不同的应用场景(包括存储设备、传输网络环境、播放设备 等),可以选用不同的压缩编码算法,如PCM、WAV、AAC、MP3、 Ogg等。比较常用的编码器有opus和silk编码器。
- 会议场景,主要追求的是互动的流畅,所以我们会选择延迟较小的、音质一般的音频编 / 解码器,比如 OPUS。
- 音乐场景,除了高码率保证音质外,还需要多声道来保证音频的空间感,我们可以使用双声道、甚至多声道的编 / 解码器,例如 AAC 来实现。
下图是不同编码器的性能表现
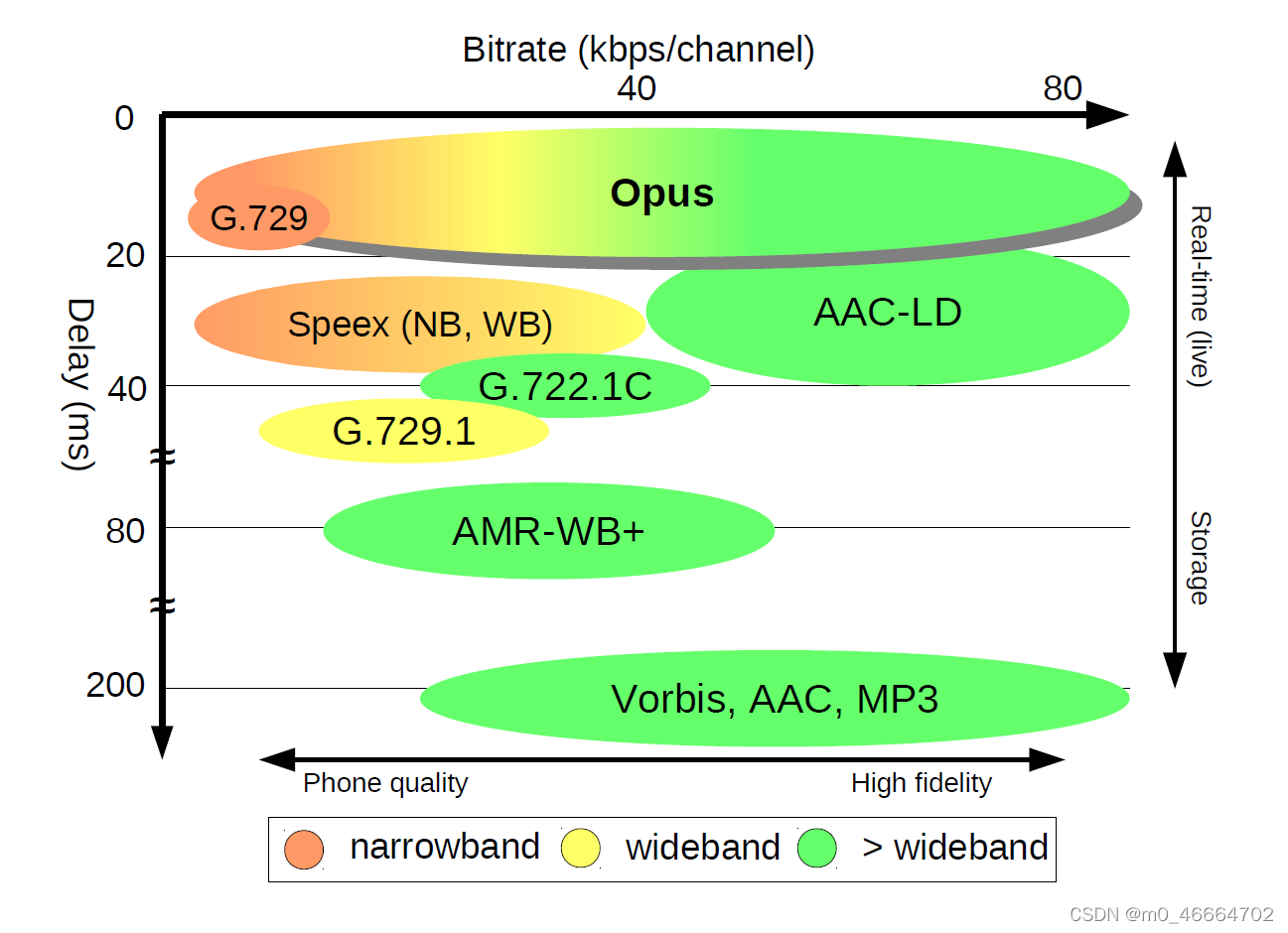
3.2 网络传输
弱网的情况在实时音频领域中是不可避免的一类问题。它主要表现为丢包、延迟和抖动这三个常见现象。音频数据在弱网环境中传输,如何确保解码后音频能流畅播放呢?这时候就需要使用到抗丢包策略、抗延时抖动策略。
3.2.1 抗丢包策略
其实抗丢包背后的逻辑比较简单。简单地说,就是同一个包一次多发几个,只要不是都丢了就能至少收到一个包;又或者丢了包就再重传一个,只要速度够快还能赶上正常的播放时间就可以。这两种思想对应我们通常使用的前向纠错 FEC(Forward Error Correction)和自动重传请求 ARQ(Automatic Repeat-reQuest)这两个纠错算法。
- 自动重传请求ARQ:ARQ 的原理非常简单。它就是采用使用确认信息(Acknowledgements Signal,ack),也就是接收端发回的确认信息,表征已正确接收数据包和超时时间。如果发送方在超时前没有收到确认信息 ack,那么发送端就会重传数据包,直到发送方收到确认信息 ack 或直到超过预先定义的重传次数。
- 前向纠错 FEC:FEC 是发送端通过信道编码和发送冗余信息,而接收端检测丢包,并且在不需要重传的前提下根据冗余信息恢复丢失的大部分数据包。即以更高的信道带宽作为恢复丢包的开销。
可以看到相比 ARQ 的丢包恢复,由于 FEC 是连续发送的,且无需等待接受端回应,所以 FEC 在体验上的延时更小。但由于不管有没有丢包 FEC 都发送了冗余的数据包,所以它对信道带宽消耗较多。而相比 FEC 的丢包恢复,ARQ 因为要等待 ack 或者需要多次重传。因此,ARQ 延时较大,带宽利用率不高。
四、经过网络传输后的处理
经过网络传输后的数据,由于弱网的影响,语音包会乱序,缺失,所以需要进行抖动消除,丢包补偿和解码等处理。
从第三节的介绍可以看到看到,前向纠错 FEC和自动重传请求ARQ两种算法都增加了网络所需要传输的带宽。那么如果网络带宽本就不够而导致丢包,这时 FEC 和 ARQ 不但没能起到抗丢包的作用,而且还可能导致网络堵塞导致丢包更严重。这时候就应该对经过网络传输后的音频数据使用别的抗丢包方法来解决弱网下导致的抖动和丢包问题。这里介绍webrtc框架中的NetEQ模块,该模块包含了抖动消除,丢包补偿和解码等操作。
- NetEQ:
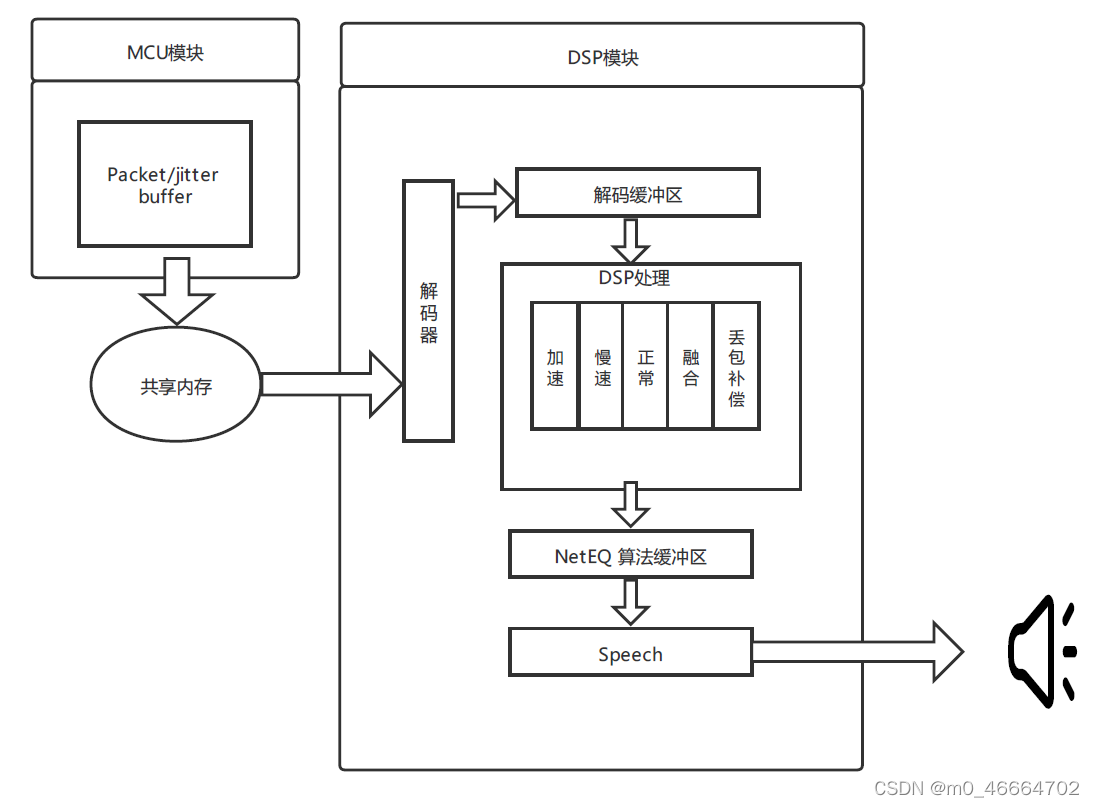
图4.webrtc的NetEQ模块图
从图4看出,jitter buffer(也就是packet buffer,后面表述成packet buffer,用于去除网络抖动)模块在MCU单元内,解码器和PCM信号处理模块在DSP单元内。MCU单元主要负责把从网络侧收到的语音包经过RTP解析后往packet buffer里插入(insert),以及从packet buffer 里提取(extract)语音包给DSP单元做解码、信号处理等,同时也算网络延时(optBufLevel)和抖动缓冲延时,根据网络延时和抖动缓冲延时以及其他因素(上一帧的处理方式等)决定给DSP单元发什么信号处理命令。主要的信号处理命令有5种,一是正常播放,即不需要做信号处理。二是加速播放,用于通话延时较大的情况,通过加速算法使语音信息不丢而减少语音时长,从而减少延时。三是减速播放,用于语音断续情况,通过减速算法使语音信息不丢而增加语音时长,从而减少语音断续。四是丢包补偿,用于丢包情况,通过丢包补偿算法把丢掉的语音补偿回来。五是融合(merge),用于前一帧丢包而当前包正常收到的情况,由于前一包丢失用丢包补偿算法补回了语音,与当前包之间需要做融合处理来平滑上一补偿的包和当前正常收到的语音包。以上几种信号处理提高了在恶劣网络环境下的语音质量,增强了用户体验。可以说是在目前公开的处理语音的网络丢包、延时和抖动的方案中是最佳的了。
总的来说,NetEQ 是通过一些音频处理方法,比如快慢放、PLC(丢包补偿) 等方法来解决抖动和丢包的问题。
经过NetEQ模块处理后的数据就可以送到播放器进行播放,有的软件也会在播放前再进行一次降噪和自动增益处理,目的同样是为了提高用户的体验质量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









