






一、urllib的1个类型和6个方法
1. response的类型
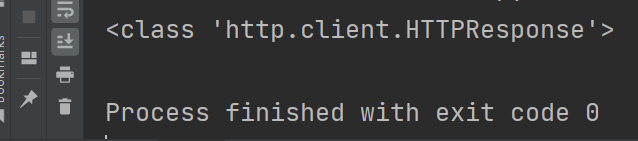
我们打印一下urllib.request方法获取的response是什么类型
import urllib.request
url = "http://www.baidu.com"
response = urllib.request.urlopen(url)
print(type(response))
结果是’HTTPResponse’类型,暂且记住,是为了和之后的requests库区分开。
2. 6个方法
6个方法都是对response而言的:
- response.read() :特点是一字节一字节去读,效率低
content = response.read() # 全部读取
content = response.read(5) # 表示只读前5个字节
- response.readline() :读取(第)一行
content = response.readline()
- response.readlines() :读取所有行,列表储存(类似文件的读取)
content = response.readlines() # 返回的是列表
- response.getcode():获取状态码
print(response.getcode()) # 返回200表示访问成功,逻辑正确
- response.geturl():获取url地址
print(response.geturl()) # 基本没什么用
- response.getheaders():获取状态信息(响应头)
print(response.getheaders()) # 列表类型,元素都是元组形式
二、使用urllib进行下载
用到的函数是urllib.request.urlretrieve(url=?,filename=?)
参数url即我们要下载的资源的url地址,filename即我们要保存到本地的文件名。
下面分别以下载网页、图片和视频为例:
1. 下载网页
url_page = "http://www.baidu.com"
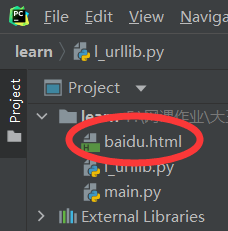
urllib.request.urlretrieve(url_page, 'baidu.html')
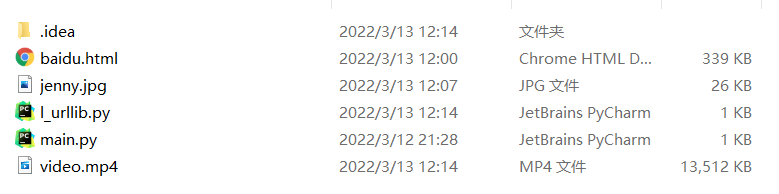
运行上述代码后,在项目目录下发现多了’baidu.html’,下载成功
2. 下载图片
以网络图片为例,如图复制图片url地址

url_img = "https://img2.baidu.com/it/u=3998891405,3474278461&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=500"
urllib.request.urlretrieve(url_img, 'jenny.jpg')
运行上述代码后,在项目目录下发现多了’jenny.jpg’,下载成功

大家可能和我有一样的疑问,手动下载它不香吗?
我总结的原因如下:
- 当需要下载的图片特别多时,例如成千上万,手动下载肯定比不上程序
- 我们往往得不到资源的url,没有办法直接手动下载。爬取后的解析操作为的就是获取有用的信息,例如想要下载图片的url。
3. 下载视频
以网络视频为例,F12获取视频下载的src

url_video = "https://vd4.bdstatic.com/mda-ncabdxs3k2mkjq3g/sc/cae_h264_delogo/1646986556076827915/mda-ncabdxs3k2mkjq3g.mp4?v_from_s=hkapp-haokan-tucheng&auth_key=1647146550-0-0-a2c5e5ba902195ad44640e87df20b352&bcevod_channel=searchbox_feed&pd=1&cd=0&pt=3&logid=0750870118&vid=12970100849765423858&abtest=100815_2-17451_1&klogid=0750870118"
urllib.request.urlretrieve(url_video, 'video.mp4')
运行上述代码后,在项目目录下发现多了’video.mp4’,下载成功, 并且能正常播放。
全部代码:
import urllib.request
# 下载网页
url_page = "http://www.baidu.com"
urllib.request.urlretrieve(url_page, 'baidu.html')
# 下载图片
url_img = "https://img2.baidu.com/it/u=3998891405,3474278461&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=500"
urllib.request.urlretrieve(url_img, 'jenny.jpg')
# 下载视频
url_video = "https://vd4.bdstatic.com/mda-ncabdxs3k2mkjq3g/sc/cae_h264_delogo/1646986556076827915/mda-ncabdxs3k2mkjq3g.mp4?v_from_s=hkapp-haokan-tucheng&auth_key=1647146550-0-0-a2c5e5ba902195ad44640e87df20b352&bcevod_channel=searchbox_feed&pd=1&cd=0&pt=3&logid=0750870118&vid=12970100849765423858&abtest=100815_2-17451_1&klogid=0750870118"
urllib.request.urlretrieve(url_video, 'video.mp4')
总结
- 通过urllib.request.urlopen()获取到的response是HTTPResponse类型,要和后面的requests库区分开。
- urlretrieve的两个参数分别是下载资源的url,和下载资源的命名。
















 736
736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











