







 本文整理自腾讯云容器技术专家胡启明的分享,探讨了Kubernetes云上资源的分析与优化问题,包括资源浪费、弹性伸缩的挑战以及Crane项目在资源推荐和智能弹性方面的解决方案。Crane通过资源分析和优化插件,提供资源推荐和副本/弹性推荐,有效提升了资源利用率并降低了成本。
本文整理自腾讯云容器技术专家胡启明的分享,探讨了Kubernetes云上资源的分析与优化问题,包括资源浪费、弹性伸缩的挑战以及Crane项目在资源推荐和智能弹性方面的解决方案。Crane通过资源分析和优化插件,提供资源推荐和副本/弹性推荐,有效提升了资源利用率并降低了成本。

嘉宾 | 胡启明
出品 | CSDN云原生
2022年6月30日,中国信通院、腾讯云、FinOps产业标准工作组联合发起的《原动力x云原生正发声 降本增效大讲堂》系列直播活动第2讲如期举行,腾讯云容器技术专家胡启明分享了Kubernetes云上资源的分析与优化。
胡启明是开源项目Crane的Founder和负责人,专注Kubernetes云原生领域8年,负责专有云容器产品、云原生应用平台的研发和管理,是Kubernetes、Dapr、KubeEdge等多个开源项目的Contributor。本文整理自胡启明的分享。

Kubernetes云上资源管理
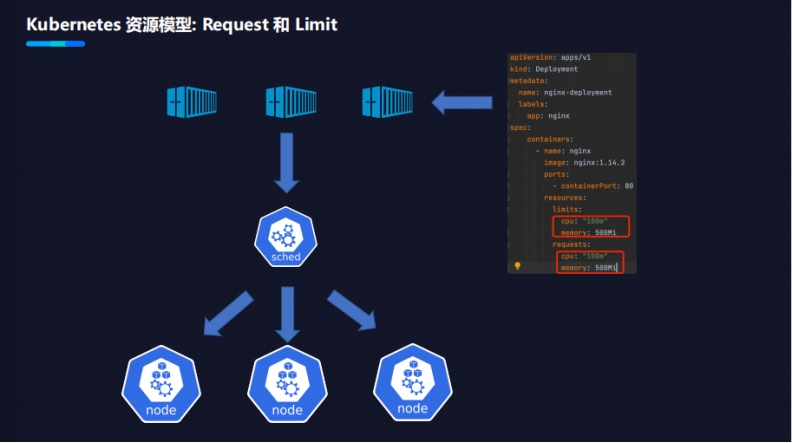
Kubernetes资源模型:Request和Limit
-
Request代表Kubernetes应用声明它希望获得的最小的资源使用量。
-
Limit代表Kubernetes应用声明它希望获得的最大的资源使用量。
Kubernetes的调度器,会根据Request的申请量去调度应用到Kubernetes的节点上。
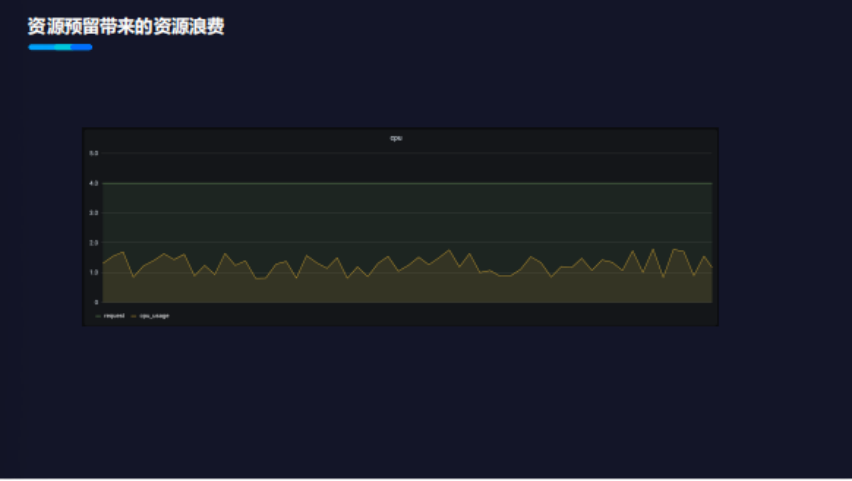
资源预留带来的资源浪费
关于Request的模型,用户设置时存在一个问题:用户的开发者不一定对业务线上运行情况完全感知。例如:不知道业务在线上运行时需要多少CPU和内存,以及业务洪峰的场景下资源使用量会上涨的维度。因此,基于这些问题,在业务开发、运维在配置Request时,开发者会选择保守策略,常把配置设高。
同时,也带来另一个问题:资源浪费比较显著。如下图所示,应用的Request声明了4个核,但实际使用不超过2个核。这都是由于保守、业务运行不了解带来的资源浪费。
资源紧缺带来的资源浪费
CPU是可压缩资源。当CPU紧缺时,实际用量可以超过CPU总量,此时会出现资源的争抢,导致应用处理程序速度变慢。
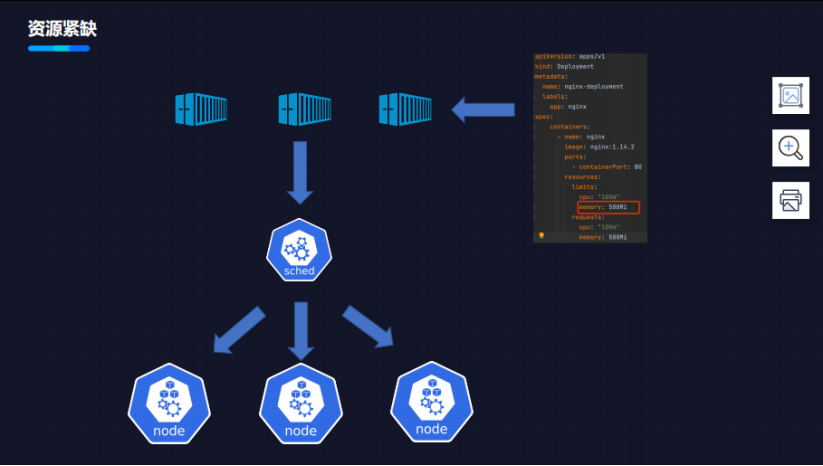
内存是不可压缩资源,如果业务运行中超过了上限,就会呈现下图的情况。

如上图所示,Kubernetes中的节点上部署了两个容器,它们在处理业务都有规律:
-
在晚上,业务的使用量会降低,白天高峰期业务容量就会偏高;
-
昼夜规律比较相似,相似的业务部署在了同一个节点上;
-
业务高峰期,容器的内存用量会达到它的Limit值,但由于调度应用是根据Request完成的,会导致在业务高峰期节点上内存被耗尽。
资源被耗尽时候,会发生什么事?
-
如果节点的内存耗尽,Kubernetes会按顺序驱逐容器,排序规则是容器实际内存使用超出Request的用量。如果去驱逐用量大于Request的东西,业务就会发生损伤,因为它的容器被Kill,并且这时候往往是处在于业务的高峰期,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









