






目录
19.设一个带头结点的循环单链表,结点均为正整数。设计算法,反复找出单链表中结点值最小的结点并输出,然后将该结点从中删除,直到单链表空为止,再删除表头结点
20.每当在链表中进行一次 Locate(L,x)运算时,令元素值为X的结点中 freq 域的值增 1,并使此链表中结点保持按访问频度非增(递减)的顺序排列,同时最近访
21.单链表有环,是指单链表的最后一个结点的指针指向了链表中的某个结点(通常单链表的最后一个结点的指针域是空的)。试编写算法判断单链表是否存在环。
22.请设计一个尽可能高效的算法,查找链表中倒数第 k个位置上的结点 (k为正整数)。若查找成功,算法输出该结点的 data域的值
19.设一个带头结点的循环单链表,结点均为正整数。设计算法,反复找出单链表中结点值最小的结点并输出,然后将该结点从中删除,直到单链表空为止,再删除表头结点
本题代码如下
void min_x(linklist* L)
{
lnode* p, * pre, * minp, * minpre;
int i = 0;//这个只是为了方便看结果
while ((*L)->next != *L)//表不空
{
p = (*L)->next;//p为工作指针
pre = *L;//pre为p的前驱指针
minp = p;//minp指向最小值结点
minpre = pre;
while (p != *L)//循环一趟查找最小结点
{
if (p->data < pre->data)
{
minp = p;//找到更小的结点
minpre = pre;
}
pre = p;//向后遍历
p = p->next;
}
i++;
printf("\n第%d次输出的最小元素为%d ",i,minp->data);//输出最小值结点
minpre->next = minp->next;//最小值结点从链表中断开
free(minp);//释放空间
}
free(*L);//释放头结点
}完整测试代码
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{
int data;
struct lnode* next;
}lnode,*linklist;
int n = 5;
int a[5]={ 3,4,9,1,2};
void buildlinklist(linklist* L)//建立循环单链表
{
(*L)->next = *L;
lnode* r = *L;
int i = 0;
for (i = 0; i < n; i++)
{
lnode* s = (lnode*)malloc(sizeof(lnode));
s->data = a[i];
r->next = s;
r = r->next;
}
r->next = *L;
}
void min_x(linklist* L)
{
lnode* p, * pre, * minp, * minpre;
int i = 0;//这个只是为了方便看结果
while ((*L)->next != *L)//表不空
{
p = (*L)->next;//p为工作指针
pre = *L;//pre为p的前驱指针
minp = p;//minp指向最小值结点
minpre = pre;
while (p != *L)//循环一趟查找最小结点
{
if (p->data < pre->data)
{
minp = p;//找到更小的结点
minpre = pre;
}
pre = p;//向后遍历
p = p->next;
}
i++;
printf("\n第%d次输出的最小元素为%d ",i,minp->data);//输出最小值结点
minpre->next = minp->next;//最小值结点从链表中断开
free(minp);//释放空间
}
free(*L);//释放头结点
}
void print(linklist *L)//输出循环单链表
{
lnode* k = (*L)->next;
while (k != *L)
{
printf("%d ",k->data);
k = k->next;
}
}
int main()
{
linklist L=(lnode*)malloc(sizeof(lnode));
buildlinklist(&L);
printf("原始链表为:");
print(&L);
min_x(&L);
return 0;
}

20.每当在链表中进行一次 Locate(L,x)运算时,令元素值为X的结点中 freq 域的值增 1,并使此链表中结点保持按访问频度非增(递减)的顺序排列,同时最近访

本题就是找到使用locate(L,x)的次数最高的x,并将他放到链表的最前面,同时最近访问的结点排在频度相同的结点前面
本题代码如下
linklist locate(linklist* L, int x)
{
lnode* p = (*L)->next, * q = *L;//p为工作指针,q为p的前驱,用于插入位置
while (p && p->data != x)//查找值为x的结点
{
q = p;
p = p->next;
}
if (!p)//不存在值为x的结点
{
printf("没有这个结点\n");
return NULL;
}
else
{
p->freq++;//令元素值为x的结点的freq域加1
if (p->next != NULL)
p->next->pred = p->pred;
p->pred->next = p->next;//将p结点从链表摘下
q = p->pred;
while (q != *L && q->freq <= p->freq)//查找p的插入位置
q = q->pred;
p->next = q->next;
if (q->next != NULL)//将p排在同频率的第一位
q->next->pred = p;
q->next = p;
p->pred = q;
}
return p;//返回值为x的结点
}完整测试代码
#include <stdio.h>
#include <stdlib.h>
typedef struct lnode
{
int data;
struct lnode* next;
struct lnode* pred;
int freq;
} lnode, * linklist;
int n = 5;
int a[5] = { 1,2,3,4,5 };
void buildlinklist(linklist* L)
{
*L = (lnode*)malloc(sizeof(lnode));
(*L)->next = *L;
(*L)->pred = NULL;
lnode* s, * r = *L;
int i = 0;
for (i = 0; i < n; i++)
{
s = (lnode*)malloc(sizeof(lnode));
s->data = a[i];
s->freq = 0;
s->next = r->next;
if (r->next != NULL)
r->next->pred = s;
r->next = s;
s->pred = r;
r = s;
}
r->next = NULL;
}
linklist locate(linklist* L, int x)
{
lnode* p = (*L)->next, * q = *L;//p为工作指针,q为p的前驱,用于插入位置
while (p && p->data != x)//查找值为x的结点
{
q = p;
p = p->next;
}
if (!p)//不存在值为x的结点
{
printf("没有这个结点\n");
return NULL;
}
else
{
p->freq++;//令元素值为x的结点的freq域加1
if (p->next != NULL)
p->next->pred = p->pred;
p->pred->next = p->next;//将p结点从链表摘下
q = p->pred;
while (q != *L && q->freq <= p->freq)//查找p的插入位置
q = q->pred;
p->next = q->next;
if (q->next != NULL)//将p排在同频率的第一位
q->next->pred = p;
q->next = p;
p->pred = q;
}
return p;//返回值为x的结点
}
void print(linklist* L)
{
lnode* k = (*L)->next;
while (k)
{
printf("%d ", k->data);
k = k->next;
}
}
int main()
{
linklist L;
buildlinklist(&L);
printf("原链表为: ");
print(&L);
locate(&L, 5);
locate(&L, 5);
locate(&L, 2);
locate(&L, 2);
printf("\n结果链表为: ");
print(&L);
return 0;
}


这里5跟2都调用了两次,但是最后一次调用的是2。所以最后的结果链表里2排在5的前面

这样的话结果如下,结果链表中5就在2前面了,如下

再看一种情况

这样2被查了三次,在最前面

21.单链表有环,是指单链表的最后一个结点的指针指向了链表中的某个结点(通常单链表的最后一个结点的指针域是空的)。试编写算法判断单链表是否存在环。
本题设置快慢两个指针,快指针每次走两步,慢指针每次走一步,如果有环,他们肯定会相遇,相遇点就是环的入口点
本题代码如下
linklist find(linklist* L)
{
lnode* f = *L, * s = *L;//设置快慢两个指针
while (s != NULL && f->next != NULL)
{
s = s->next;//每次走一步
f = f->next->next;//每次走两步
if (s->data == f->data)//相遇
break;
}
if (s == NULL || f->next == NULL)
return NULL;//没有环,返回NULL
lnode* p = *L, * q = s;//分开指向开始点、相遇点
while (p->data != q->data)
{
p = p->next;
q = q->next;
}
return p;//返回入口
}完整测试代码
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{
int data;
struct lnode* next;
}lnode,*linklist;
int n = 16;
int a[16] = { 1,2,3,4,5,6,7,8,9,3,4,5,6,7,8,9 };
void buildlinklist(linklist *L)
{
lnode* s, * r = *L;
r->data = a[0];
int i = 0;
for (i = 1; i < n; i++)
{
s = (lnode*)malloc(sizeof(lnode));
s->data = a[i];
r->next = s;
r = r->next;
}
r->next = NULL;
}
linklist find(linklist* L)
{
lnode* f = *L, * s = *L;//设置快慢两个指针
while (s != NULL && f->next != NULL)
{
s = s->next;//每次走一步
f = f->next->next;//每次走两步
if (s->data == f->data)//相遇
break;
}
if (s == NULL || f->next == NULL)
return NULL;//没有环,返回NULL
lnode* p = *L, * q = s;//分开指向开始点、相遇点
while (p->data != q->data)
{
p = p->next;
q = q->next;
}
return p;//返回入口
}
void print(linklist* L)
{
lnode* k = *L;
while (k)
{
printf("%d ", k->data);
k=k->next;
}
}
int main()
{
linklist L=(lnode*)malloc(sizeof(lnode));
buildlinklist(&L);
printf("原始单链表");
print(&L);
lnode *ans=find(&L);
printf("\n环口值为:%d",ans->data);
return 0;
}
22.请设计一个尽可能高效的算法,查找链表中倒数第 k个位置上的结点 (k为正整数)。若查找成功,算法输出该结点的 data域的值
定义两个指针变量p 和g,初始时均指向头结点的下一个结点(链表的第一个结点),p 指针沿链表移动:当p 指针移动到第 个结点时, 指针开始与p 指针同步移动:当p指针移动到最后一个结点时,g 指针所指示结点为倒数第 k 个结点。
本题代码如下
void find(linklist* L,int x)//找到倒数第k个的值
{
lnode* p = (*L)->link, * q = (*L)->link;
int count = 0;
while (p != NULL)//遍历链表直到最后一个结点
{
if (count < x)//计数,若count<x只移动p
count++;
else
q = q->link;//之后让p、q同步遍历
p = p->link;
}
if (count < x)
printf("查找失败");
else
printf("%d", q->data);
}完整测试代码如下
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{
int data;
struct lnode* link;
}lnode,*linklist;
int n = 5;
int a[5] = { 1,2,3,4,5 };
void buildlinklist(linklist* L)
{
*L = (lnode*)malloc(sizeof(lnode));
(*L)->link = NULL;
lnode* s, * r = *L;
int i = 0;
for (i = 0; i < n; i++)
{
s = (lnode*)malloc(sizeof(lnode));
s->data = a[i];
s->link = r->link;
r->link = s;
r = s;
}
r->link = NULL;
}
void find(linklist* L,int x)//找到倒数第k个的值
{
lnode* p = (*L)->link, * q = (*L)->link;
int count = 0;
while (p != NULL)//遍历链表直到最后一个结点
{
if (count < x)//计数,若count<x只移动p
count++;
else
q = q->link;//之后让p、q同步遍历
p = p->link;
}
if (count < x)
printf("查找失败");
else
printf("%d", q->data);
}
int main()
{
linklist L;
buildlinklist(&L);
find(&L, 2);
return 0;
}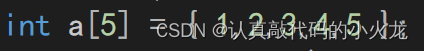

23.[2012 统考真题]假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时可共享相同的后缀存储空间,例如,“loading”和“being”的存储映像设 strl和str2分别指向两个单词所在单链表的头结点,链表结点结构为datanext请设计一个时间上尽可能高效的算法,找出由 str1和 str2 所指向两个链表共同后缀的起始位置
本题代码如下👇
//我这个在外面已经计算好了两个字符串的长度,所以直接传值进去了
linklist find(linklist *L1,linklist *L2,int sza,int szb)
{
lnode* p, * q;
for (p = *L1; sza > szb; sza--)//若sza>szb,使p指向链表中的第m-n+1个结点
p = p->next;
for (q = *L2; szb > sza; szb--)//若szb>sza,使q指向链表中的第n-m+1个结点
q = q->next;
while (p->next!=NULL&&p->next->data!=q->next->data)//将p与q同步后移
{
p = p->next;
q = q->next;
}
return p->next;//返回公共后缀的起始地址
}可以这样计算链表长度👇
int listlen(linklist *L)
{
int len=0;
while((*L)->next!=NULL)
{
len++;
*L=(*L)->next;
}
return len;
}完整测试代码👇
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{
char data;
struct lnode* next;
}lnode, * linklist;
char a[7] = { "loading" };
char b[5] = { "being" };
int len(char arr[])
{
int i = 0;
int count = 0;
for (i = 0; arr[i] != '\0'; i++)
count++;
return count;
}
void buildlinklist(linklist* L,char arr[],int n)
{
*L = (lnode*)malloc(sizeof(lnode));
(*L)->next = NULL;
lnode* s = *L, * r = *L;
int i = 0;
for (i = 0; i < n; i++)
{
s = (lnode*)malloc(sizeof(lnode));
s->data = arr[i];
s->next = r->next;
r->next = s;
r = s;
}
r->next = NULL;
}
linklist find(linklist *L1,linklist *L2,int sza,int szb)//我这个在外面已经计算好了两个字符串的长度,所以直接传值进去了
{
lnode* p, * q;
for (p = *L1; sza > szb; sza--)
p = p->next;
for (q = *L2; szb > sza; szb--)
q = q->next;
while (p->next!=NULL&&p->next->data!=q->next->data)
{
p = p->next;
q = q->next;
}
return p->next;
}
void print(linklist *L)
{
lnode* k = (*L)->next;
while (k)
{
printf("%c ", k->data);
k = k->next;
}
}
int main()
{
int sza = len(a);
int szb = len(b);
linklist L1,L2;
buildlinklist(&L1,a,sza);
printf("原始的L1单链表为:");
print(&L1);
buildlinklist(&L2, b, szb);
printf("\n原始的L2单链表为:");
print(&L2);
linklist C=find(&L1, &L2, sza, szb);
printf("\n公共首结点为:%c", C->data);
return 0;
}
也可以这样写(差不多的思路)其实也还可以暴力求解(这里就没写啦)
linklist find(linklist* L1, linklist* L2, int sza, int szb)
{
lnode* p=(*L1)->next, * q=(*L2)->next;
if (sza > szb)//如果sza大于szb
{
int dist = sza - szb;
for (int i = 0; i < dist; i++)//让p移动到与q到表尾长度相同的位置
p = p->next;
}
if (sza < szb)//如果sza小于szb
{
int dist = szb - sza;
for (int i = 0; i < dist; i++)//让q移动到与p到表尾长度相同的位置
q = q->next;
}
while (p && q)//一起向后遍历
{
if (p->data == q->data)//遇到了就返回结点的值
return p;
else
{
p = p->next;
q = q->next;
}
}
return 0;
}完整测试代码为
#include<stdio.h>
#include<stdlib.h>
typedef struct lnode
{
char data;
struct lnode* next;
}lnode, * linklist;
char a[7] = { "loading" };
char b[5] = { "being" };
int len(char arr[])
{
int i = 0;
int count = 0;
for (i = 0; arr[i] != '\0'; i++)
count++;
return count;
}
void buildlinklist(linklist* L, char arr[], int n)
{
*L = (lnode*)malloc(sizeof(lnode));
(*L)->next = NULL;
lnode* s = *L, * r = *L;
int i = 0;
for (i = 0; i < n; i++)
{
s = (lnode*)malloc(sizeof(lnode));
s->data = arr[i];
s->next = r->next;
r->next = s;
r = s;
}
r->next = NULL;
}
linklist find(linklist* L1, linklist* L2, int sza, int szb)//我这个在外面已经计算好了两个字符串的长度,所以直接传值进去了
{
lnode* p=(*L1)->next, * q=(*L2)->next;
if (sza > szb)//如果sza大于szb
{
int dist = sza - szb;
for (int i = 0; i < dist; i++)//让p移动到与q到表尾长度相同的位置
p = p->next;
}
if (sza < szb)//如果sza小于szb
{
int dist = szb - sza;
for (int i = 0; i < dist; i++)//让q移动到与p到表尾长度相同的位置
q = q->next;
}
while (p && q)//一起向后遍历
{
if (p->data == q->data)//遇到了就返回结点的值
return p;
else
{
p = p->next;
q = q->next;
}
}
return 0;
}
void print(linklist* L)
{
lnode* k = (*L)->next;
while (k)
{
printf("%c ", k->data);
k = k->next;
}
}
int main()
{
int sza = len(a);
int szb = len(b);
linklist L1, L2;
buildlinklist(&L1, a, sza);
printf("原始的L1单链表为:");
print(&L1);
buildlinklist(&L2, b, szb);
printf("\n原始的L2单链表为:");
print(&L2);
linklist C = find(&L1, &L2, sza, szb);
printf("\n公共首结点为:%c", C->data);
return 0;
}














 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











