







目录
二.验证和测试时OOM(CUDA out of memory)
2.3.2no-validate(不起作用,离线测试时依旧OOM)
一.环境
- OS:Ubuntu18.04
- CUDA:11.0
- mmcv-full:1.7.0
- mmdet:2.25.1
- GPU:1080Ti * 4
二.验证和测试时OOM(CUDA out of memory)
2.1问题描述
在使用MMDetection训练MaskRCNN实例分割模型时,训练一切正常,但是在对第一张验证集图片进行验证时,就出现了OOM爆显存的问题。
2.2初步分析
通常遇到OOM问题时的第一反应是将batch_size调小,或者是将模型的输入尺寸设置的小一点,进而减小显存的占用。但是,有时batch_size设置的不合适/过小,会导致无法复现出原本的精度,在不减小batch_size的情况下解决OOM:RuntimeError: CUDA out of memory在不减小batch_size的前提下的解决方案
不过,在验证或测试时,batch_size是为1的,不存在batch_size过大的问题,但是减小网络的输入尺寸或许可以解决这个问题,但是由于数据集中图像原本的尺寸比较大(4000*3000),如果缩小到一个很小的尺寸,可能会造成很大的精度损失,所以保持默认的(1333,800)不动去寻找解决方案。
2.3初步解决
2.3.1gpu->cpu(OK但巨慢)
参考下面这篇的做法:【pytorch】mmdetection 做eval / test时弹出OOM(Out of Memory / CUDA out of memory)的解决过程记录
(1)清显存(不起作用)
伪代码如下:
def test():
torch.cuda.empty_cache()
with torch.no_grad():
model.eval()
xxxxxx(2)改网络超参数(不起作用)
“max_per_img的数量从1000调低到500”:
test_cfg=dict(
rpn=dict(
nms_pre=1000,
max_per_img=500,
nms=dict(type='nms', iou_threshold=0.7),
min_bbox_size=0),
rcnn=dict(
score_thr=0.05,
nms=dict(type='nms', iou_threshold=0.5),
max_per_img=100,
mask_thr_binary=0.5))(3)更换为cpu计算(OK但巨慢)
修改mmdet\models\roi_heads\mask_heads\fcn_mask_head.py中_do_paste_mask函数:
#gx = img_x[:, None, :].expand(N, img_y.size(1), img_x.size(1))
#gy = img_y[:, :, None].expand(N, img_y.size(1), img_x.size(1))
gx = img_x[:, None, :].expand(N, img_y.size(1), img_x.size(1)).cpu()
gy = img_y[:, :, None].expand(N, img_y.size(1), img_x.size(1)).cpu()
grid = torch.stack([gx, gy], dim=3)
#img_masks = F.grid_sample(
# masks.to(dtype=torch.float32), grid, align_corners=False)
img_masks = F.grid_sample(
masks.cpu().to(dtype=torch.float32), grid, align_corners=False)
#if skip_empty:
# return img_masks[:, 0], (slice(y0_int, y1_int), slice(x0_int, x1_int))
#else:
# return img_masks[:, 0], ()
if skip_empty:
return img_masks[:, 0].cuda(), (slice(y0_int, y1_int), slice(x0_int, x1_int))
else:
return img_masks[:, 0].cuda(), ()2.3.2no-validate(不起作用,离线测试时依旧OOM)
想法是,离线测试或许会因为没有训练的数据占用显存而OK。在运行train.py时,指定--no-validate
parser.add_argument(
'--no-validate',
action='store_true',
help='whether not to evaluate the checkpoint during training')2.3.3rescale(OK但mAP=0)
修改mmdet/apis/test.py中的single_gpu_test和multi_gpu_test两个函数中的rescale=False
with torch.no_grad():
result = model(return_loss=False, rescale=False, **data)三.验证和测试时mAP全为0
3.1原因
由于2.3.3中设置了rescale=False,导致模型输出的bbox和segm结果都是相对于网络输入尺寸(1333,800)的,但是测试集的gt都是在原尺寸下的。此外还需要注意RLE编码格式,下面会详细说明。
3.2RLE编码
根据3.1的描述,将det结果和gt标签做一次尺度对齐似乎就可以了,但是事情并没有这么简单。由于在计算mask的iou时是先将Polygon格式的mask标签转化为RLE格式,而这个转化的操作涉及到图像的尺寸,所以需要修改coco_gt中img的尺寸。在pycocotools/cocoeval.py中COCOeval类内的_prepare函数中的_toMask函数说明了这一点:
def _toMask(anns, coco):
# modify ann['segmentation'] by reference
for ann in anns:
rle = coco.annToRLE(ann)
ann['segmentation'] = rleRLE编码。参考Segmentaion标签的三种表示:poly、mask、rle
使用mask图像的编码方式会有很多的信息冗余,大部分像素值都是0,少部分为1。RLE编码是一种压缩存储的思想,例如将mask图像平铺之后的向量[0,1,1,1,0,1,1,0,1,0] 编码之后为1,3,5,2,8,1。其中的奇数位表示像素值1出现的对应的向量中的index,而偶数位表示在向量中从该index开始像素值1重复的个数。
3.3实现效果
对MMDetection框架进行简单修改,使得在设置rescale=False的情况下也可以计算出bbox和segm的mAP.
(1)验证时默认rescale为False,需要设置为True时则修改mmdet/apis/test.py中的single_gpu_test和multi_gpu_test的缺省形参rescale为True(取决于单卡或多卡训练)
(2)离线测试时,设置tools/test.py的rescale的值(True/False),设置--show即可绘制可视化结果
3.4存在问题
- 数据集中各个图片原始尺寸不一致时会有问题
- 可视化结果和网络输出都是依照网络输入尺寸的,并不是原图尺寸
- 验证时应该是需要手动指定mmdet/datasets/coco.py中evaluate函数的scale_factor参数值(待测试)
3.5修改细节
(1)在tools/test.py的parse_args函数中新建一个参数rescale
parser.add_argument('--rescale',default=False,choices=[True,False],help='whether rescale when evaluating')(2)在tools/test.py的main函数中,新加三处代码
if not distributed:
model = build_dp(model, cfg.device, device_ids=cfg.gpu_ids)
outputs = single_gpu_test(model, data_loader, args.show, args.show_dir,
args.show_score_thr,args.rescale)#1.新加args.rescale
else:
model = build_ddp(
model,
cfg.device,
device_ids=[int(os.environ['LOCAL_RANK'])],
broadcast_buffers=False)
outputs = multi_gpu_test(
model, data_loader, args.tmpdir, args.gpu_collect
or cfg.evaluation.get('gpu_collect', False),args.rescale)#2.新加args.rescale
xxx
xxx
xxx
if args.eval:
eval_kwargs = cfg.get('evaluation', {}).copy()
# hard-code way to remove EvalHook args
for key in [
'interval', 'tmpdir', 'start', 'gpu_collect', 'save_best',
'rule', 'dynamic_intervals'
]:
eval_kwargs.pop(key, None)
eval_kwargs.update(dict(metric=args.eval, **kwargs))
#3.新加
eval_kwargs['rescale'] = args.rescale
for i, data in enumerate(data_loader):
eval_kwargs['scale_factor'] = data['img_metas'][0]._data[0][0]['scale_factor']
break(3)修改mmdet/apis/test.py中的single_gpu_test和multi_gpu_test两个函数共五处,第三处是为了保证绘制结果时的尺寸对齐

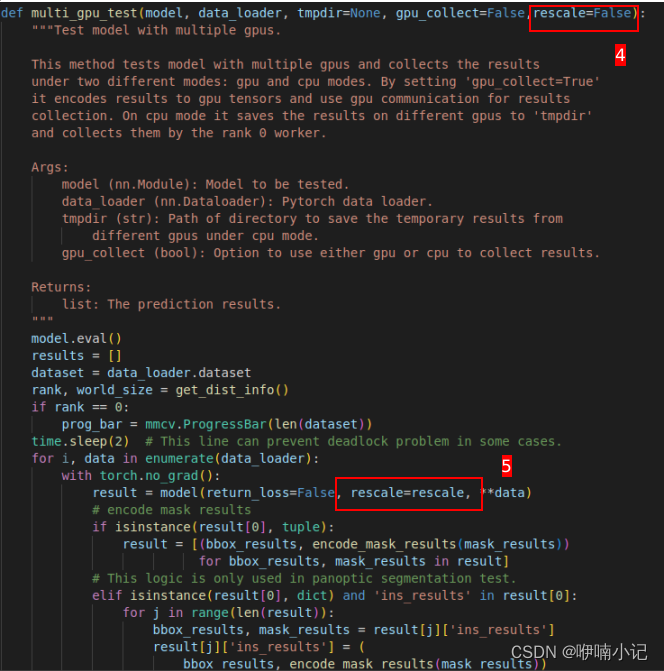
(4) 修改mmdet/datasets/coco.py中evaluate函数两处

(5)修改mmdet/datasets/coco.py中evaluate_det_segm函数形参(添加rescale和scale_factor),以及在cocoEval = COCOeval(coco_gt1, coco_det, iou_type)一行上面添加缩放代码
def evaluate_det_segm(self,
results,
result_files,
coco_gt,
metrics,
logger=None,
classwise=False,
proposal_nums=(100, 300, 1000),
iou_thrs=None,
metric_items=None,
rescale=False,
scale_factor=None):# 以下全为新加
coco_gt1 = COCO(self.ann_file)
if not rescale and scale_factor is not None:
for index in coco_gt1.anns.keys():
now_bbox = coco_gt1.anns[index]['bbox'].copy()
now_segm = coco_gt1.anns[index]['segmentation'][0].copy()
coco_gt1.anns[index]['bbox'] = [int(float(value)*scale_factor[0]) if index%2==0 else int(float(value)*scale_factor[1]) for index,value in enumerate(now_bbox)]
coco_gt1.anns[index]['segmentation'][0] = [int(float(value)*scale_factor[0]) if index%2==0 else int(float(value)*scale_factor[1]) for index,value in enumerate(now_segm)]
tmp_w = 0
tmp_h = 0
for index in coco_gt1.imgs.keys():
coco_gt1.imgs[index]['width'] = np.round(coco_gt1.imgs[index]['width'] * scale_factor[0].item()).astype(np.int32)
coco_gt1.imgs[index]['height'] = np.round(coco_gt1.imgs[index]['height'] * scale_factor[1].item()).astype(np.int32)
tmp_w = coco_gt1.imgs[index]['width']
tmp_h = coco_gt1.imgs[index]['height']
for index in coco_det.imgs.keys():
coco_det.imgs[index]['width'] = tmp_w
coco_det.imgs[index]['height'] = tmp_h
#注意这里换为coco_gt1
cocoEval = COCOeval(coco_gt1, coco_det, iou_type)
# 原有
#cocoEval = COCOeval(coco_gt, coco_det, iou_type)
cocoEval.params.catIds = self.cat_ids
cocoEval.params.imgIds = self.img_ids
cocoEval.params.maxDets = list(proposal_nums)
cocoEval.params.iouThrs = iou_thrs














 5368
5368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









