






test_list = [5, 4, 8, 6, 3, 1]
# 冒泡排序
def sort_by_mopao(test_list):
for i in range(len(test_list) - 1):
tag = True
for j in range(len(test_list) - 1):
if test_list[j] > test_list[j + 1]:
tag = False
test_list[j], test_list[j + 1] = test_list[j + 1], test_list[j]
if tag:
return
print(test_list)
sort_by_mopao(test_list)
print(test_list)test_list = [5, 4, 8, 6, 3, 1]
# 选择排序
def sort_by_choose(test_list):
for i in range(len(test_list) - 1):
min_index = i
for j in range(i, len(test_list) - 1):
if test_list[min_index] > test_list[j + 1]:
min_index = j + 1
test_list[i], test_list[min_index] = test_list[min_index], test_list[i]
print(test_list)
sort_by_choose(test_list)
print(test_list)test_list = [5, 4, 8, 6, 3, 1]
# 插入排序,从左往右插入
def sort_by_insert(test_list):
for i in range(1, len(test_list)):
index_value = test_list[i]
target_index = i
for index, value in enumerate(test_list[0:i]):
if value > index_value:
target_index = index
break
for move in range(i, target_index, -1):
test_list[move] = test_list[move-1]
test_list[target_index] = index_value
print(test_list)
sort_by_insert(test_list)
print(test_list)
# 插入排序,从右往左插入
def sort_by_insert(test_list):
for i in range(1, len(test_list)):
index_value = test_list[i]
for move in range(i, 0, -1):
if test_list[move-1] > index_value:
test_list[move] = test_list[move-1]
if move == 1:
test_list[0] = index_value
else:
test_list[move] = index_value
break
print(test_list)
sort_by_insert(test_list)
print(test_list)
# 插入排序,从右往左插入(教学视频的演示):
def insert_sort(li):
for i in range(1, len(li)):
tmp = li[i]
j = i - 1
while j >= 0 and tmp < li[j]:
li[j + 1] = li[j]
j -= 1
li[j + 1] = tmp
insert_sort(test_list)
print(test_list)test_list = [5, 4, 8, 6, 3, 1]
# 快速排序
# 其思想,也可以理解为归位排序,就是取要排序的对象的最左侧一个元素,让其归位。
# 归位的原则就是让要排序的对象中所有比其小的元素在其左边,比其大的元素在其右边
# 这样以来,这个元素的位置就一定是排好序后的位置,然后,再将其左侧的所有元素重复此操作
# 将其右侧的元素同样重复此操作,以此位递归,就可以为所有元素排好序了。
# 这里有一个点,在排序的过程中,我们先取要排序的对象的最左侧的一个元素,让其归位,这样以来,
# 这个点的值和位置就已经是备份了,或者换个理解方式,我们就相当于把这个元素取走了,这样的话
# 这个元素所在的这个位置就空缺下来了,然后,从要排序的对象的最右边开始往左开始查看,找到第一个比
# 我们要归位的这个元素小的元素,并记录其位置位right,这个元素小于要归位的元素,所以它一定在要归
# 位元素的左侧,那么就直接将这个元素放到左侧空缺处,这个时候,这个元素原来的位置就成为了新的空缺
# 然后接下来就是在老的空缺处的位置的后一个元素开始到新的空缺位置之间寻找比要归位元素大的元素,
# 记录其位置,再将其放到右侧空缺位置,依次类推,就可以完成让要归位元素归位。
# 这个过程,有点像一个拼图游戏,整个批图板块只有一个空位,每次只能移动一个板块。这里就相当于先
# 挪动左边的板块,然后将右边大于归中元素的板块挪到左边,然后,左边就没有空缺了,但是右边却有了
# 新的空缺,这时在将左边大于归中元素的元素,挪到右边的空位,这个过程寻找的范围是逐步变小的,直到
# left和right的值差1为止,差的这个1,它的位置就是归中元素的位置了。
def sort_by_quick(test_list, left, right):
mid_value = test_list[left] # 定义要归位的居中元素
while right - left > 0:
if test_list[right] < mid_value:
test_list[left] = test_list[right]
while right - left > 0:
if test_list[left] > mid_value:
test_list[right] = test_list[left]
break
else:
left += 1
continue
else:
right -= 1
continue
mid_index = right
test_list[mid_index] = mid_value
return mid_index
def sorted_by_digui(test_list, left, right):
if right > left:
mid_index = sort_by_quick(test_list, left, right)
sorted_by_digui(test_list, left, mid_index - 1)
sorted_by_digui(test_list, mid_index + 1, right)
print(test_list)
sorted_by_digui(test_list, 0, len(test_list)-1)
print(test_list)
# 视频教学中的演示,partion方法 对应我的 sort_by_quick方法:
def partiton(test_list, left, right):
tmp = test_list[left]
while right > left:
while test_list[right] >= tmp and right > left:
right -= 1
test_list[left] = test_list[right]
while test_list[left] <= tmp and right > left:
left += 1
test_list[right] = test_list[left]
test_list[right] = tmp
return right
# 再次复习时,对这个问题,新的看法,个人觉得,这个写法,算是最好理解的
def sorted_by_mid(test_list, left, right):
mid_element_value = test_list[left] # 要归位的居中元素
target_index = left # 定义要归位的中间元素的位置, 且这时候,整个队列出现的第一个坑位就是left位
while left < right:
# 从右往左走,看谁填最左边的坑
if test_list[right] < mid_element_value:
# 将右边第一个小于mid_element_value的元素填充到左边的坑里
test_list[left] = test_list[right]
# 这就是新出现的坑位
target_index = right
else:
# 如果当前这个元素大于等于mid_element_value,那么就接着往前找
right -= 1
continue
# 第一个左边的坑填上了,右边现在有坑出现,现在需要从左往右看,找到大于
# mid_element_value的元素,将其填到右边的坑
# 由于左边left刚被小于mid_element_value的元素给填上,所以当下
# left一定比mid_element_value的元素小,所以从left之后一个元素开始寻找新的
# 比mid_element_value的元素大的元素
left += 1
if test_list[left] > mid_element_value:
test_list[right] = test_list[left]
# 这就是新出现的坑位
target_index = left
else:
left += 1
continue
# 当循环结束后,唯一没有填上的坑位,就是mid_element_value元素的坑位
test_list[target_index] = mid_element_value
return target_indextest_list = [10, 9, 3, 6, 8, 1, 2, 5]
# 堆排序
# 堆排序是一种抽象的思想吧,它是将一个朴实无华的列表,构建成一个满二叉树,或者最起码是一个
# 完全二叉树的数据结构,这样一来,就可以得到一个稳定的二叉树结构,满足最大的那个数在最上方
# 如果按照统治理论来说,那么它就可以统治下面所有的节点,而没有哪个节点能造反。这样以来,就
# 可以得到一个结论,这种稳定的结构,可以筛选最大值,那么只需要将最大值和列表最后那个值替换
# 位置,然后再构建一次稳定二叉树结构就又会产生新的最大值,也就是第二大值,然后将新的最大值和
# 列表倒数第二的位置替换,然后,再完成构建一次稳定二叉树结构就又会产生新的最大值,也就是第三
# 大的值,这样以此类推,最终,就可以得到有序的队列了
# 至于构建稳定二叉树的过程:先假设其他元素都已完成排序,现在只有根节点没有完成排序,然后
# 去实现根节点的二叉树排序,让根节点找到合适的位置,完成整个树结构的有序。
# 然后,从整个列表的最后开始,向前逆推,根据公式查找最近元素的父节点,对其排序,从树结构的
# 树冠开始一步一步往树根逆向排序,最后就完成了整个排序过程。
def do_st(test_list, father_node, end_index):
son_node = 2*father_node + 1 # 获取左孩子下标
tmp = test_list[father_node] # 保存父节点的值
while son_node <= end_index:
# 这一步的意义在于,确保存在右孩子,且右孩子的值较大
if son_node + 1 <= end_index and test_list[son_node+1] > test_list[son_node]:
# 这是一个标记,准确的来说上面的son_node,本身就是代表较大的那个孩子的下标,
# 只是说,刚开始在不确定存在右孩子的情况下,我们先默认左孩子就是那个较大的孩子
# 现在确定右孩子比较大,那么,son_node理所应当的表更标记为右孩子的下标
son_node = son_node + 1
if test_list[son_node] > tmp:
test_list[father_node] = test_list[son_node]
father_node = son_node
son_node = 2*father_node + 1
else:
break
test_list[father_node] = tmp
# 构建稳定二叉树的过程
def build_stacked(test_list):
last_father_node = (len(test_list) - 2)//2
for father_node in range(last_father_node, -1, -1):
do_st(test_list, father_node, len(test_list)-1)
# 通过稳定二叉树的最大根节点一定是最大值的特点,对其进行排序
def sorted_by_stacked(test_list):
for i in range(len(test_list)-1, 0, -1):
test_list[0], test_list[i] = test_list[i], test_list[0]
do_st(test_list, 0, i-1)
print(test_list)
build_stacked(test_list)
sorted_by_stacked(test_list)
print(test_list)
# 二次复习再写这个东西,感觉思路是理解了,但是做的确实没有视频中搞的轻松写意了
# 这里一定注意,父节点一定给的是下标,而不是给值
def dui_sorted(test_list, father_node_index, end_node_index):
"""
:param test_list:
:param father_node_index:
:param end_node_index: 终止节点的下标
:return:
"""
father_node_value = test_list[father_node_index]
left_node_index = 2 * father_node_index + 1
while left_node_index <= end_node_index:
left_node_value = test_list[left_node_index]
# 说明有右子节点
if left_node_index + 1 <= end_node_index:
# 如果右子节点大于左子节点,且右子节点的值大于父节点,那么右子节点上位,父节点下来,同时右子节点成为新的父节点
if test_list[left_node_index + 1] > left_node_value \
and test_list[left_node_index + 1] > father_node_value:
test_list[father_node_index] = test_list[left_node_index + 1]
test_list[left_node_index + 1] = father_node_value
father_node_index = left_node_index + 1
# 如果右子节点小于左子节点,且左子节点的值大于父节点,那么左子节点上位,父节点下来,同时左子节点成为新的父节点
elif test_list[left_node_index + 1] < left_node_value \
and left_node_value > father_node_value:
test_list[father_node_index] = left_node_value
test_list[left_node_index] = father_node_value
father_node_index = left_node_index
# 说明,父节点大于2个子节点,父节点已经找到了自己的位置,无需做其他操作
else:
break
# 刷新 left_node_index 的值
left_node_index = 2 * father_node_index + 1
# 说明边界情况时,没有右子节点,只需比较左子节点即可
else:
# 如果左子节点的值大于父节点的值,那么父节点下来,左子节点上去
if left_node_value > father_node_value:
test_list[father_node_index] = left_node_value
test_list[left_node_index] = father_node_value
father_node_index = left_node_index
left_node_index = 2 * father_node_index + 1
else:
breaktest_list = [5, 4, 8, 6, 3, 1]
# 归并排序
# 归并排序等于说将整个队列分成2部分,先对左边排序,完事后对右边排序,当两边都是有序的了以后,再将
# 2个有序的队列合并成一个有序的队列,这个过程,有些像先将一个队列打散成最小元素的状态,然后再进行
# 拼接,所以叫做归并排序。拆的时候,是按照递归去拆,因为最小粒子状态就是一个元素的状态所以,拆到
# 最后就剩下一个有一个的单个元素了,这样以来,就可以对其进行合并了,先是两两合并,就成一堆的2个元# 素组合起来的有序板块了,接下来,就是新板块的合并,新板块每个板块有2个元素,所以又是两两合并,就
# 成了4个元素一个板块了,再次两两合并,就成8个元素一个板块了,依次类推,完成所有元素的合并。这个
# 合并的过程就是排序的过程。假如现在有2个列表现在它们都是有序的,然后将这两个列表合并的过程就是,# 先取2个列表中第一个元素,假设第一个列表的第一个元素小,然后就把它先存到一个新的列表中,接下来
# 看第一个列表中的第二个元素,看它和第二个列表的第一个元素谁大,如果第二个列表的第一个元素小,那
# 么这时就需要把第二个列表里的第一个元素存入新建的列表里,接下来就可以比较第一个列表里的第二个元
# 素和第二个列表里的第二个元素了,依次类推,我们每次拿到的其实都是2个列表里最小的那个元素,整个过
# 程完成后,就完成了排序。
def merge(test_list, mid, left, right):
left_index = left
right_index = mid + 1
tmp_list = []
while left_index <= mid and right_index <= right:
if test_list[left_index] > test_list[right_index]:
tmp_list.append(test_list[right_index])
right_index += 1
else:
tmp_list.append(test_list[left_index])
left_index += 1
while left_index <= mid:
tmp_list.append(test_list[left_index])
left_index += 1
while right_index <= right:
tmp_list.append(test_list[right_index])
right_index += 1
test_list[left: right+1] = tmp_list
def sorted_by_merge(test_list, left, right):
"""
:param test_list:
:param left: 要排序的部分列表的左端下标
:param right: 要排序的部分列表的右端下标
:return:
"""
# 这里一定需要添加这个条件,因为,排序的前提条件就是,至少有2个元素,如果left = right,那就
# 说明,此时列表中只有一个元素,那就无需排序了
if left < right:
mid = (left + right)//2
sorted_by_merge(test_list, left, mid)
sorted_by_merge(test_list, mid+1, right)
merge(test_list, mid, left, right)
print(test_list)
sorted_by_merge(test_list, 0, len(test_list)-1)
print(test_list)
# 二次复习再次编写,从原理开始,按照自己的想法写
def merge(test_list, mid, left, right):
# 分别提取mid两侧的有序列表,注意根据外面的递归写法来看,mid是归到左边的有序列表中了
# 所以这里的mid需要加1
list_1 = test_list[left:mid+1]
list_2 = test_list[mid+1:right+1]
# 制作收集有序元素的列表
collect_tmp = []
left_index_1 = 0
left_index_2 = 0
# 由于2个列表的长度不一定就是一样长的,因此,我们首先保证再不确界的范围内,进行有序元素的收集
while left_index_1 <= len(list_1)-1 and left_index_2 <= len(list_2)-1:
if list_1[left_index_1] > list_2[left_index_2]:
collect_tmp.append(list_2[left_index_2])
left_index_2 += 1
else:
collect_tmp.append(list_1[left_index_1])
left_index_1 += 1
# 由于2个列表的长度不一定相同,保证不越界的情况结束上面的循环后,有可能会存在有哪个列表有空余元素
# 没有被纳入collect_tmp,且,由于2个列表都是有序的,因此,这里直接将剩余有序的元素
# 直接extend到collect_tmp中即可
if left_index_1 <= len(list_1)-1:
collect_tmp.extend(list_1[left_index_1:])
if left_index_2 <= len(list_2)-1:
collect_tmp.extend(list_2[left_index_2:])
# 最终,将test_list中,这2段有序列表合二为一,变成一个新的有序列表,
# 继续参与下一轮2个有序列表的合并动作
test_list[left:right+1] = collect_tmptest_list = [5, 4, 8, 6, 3, 1]
# 希尔排序
# 它的原理是,将一个列表分为len(list)//2数量个组,比如:len(list) = 10,那么第一次就是要分成5组
# 然后每组进行排序,排完后在进行分组这次分为 len(list)//2//2 组,然后再次排序,最后,直到
# 只剩1组,然后再次排序得到最后的结果。这样 做的意义在于,每次都会让整个队列变的更加相对有序,
# 直到最终有序。这个过程每次分组排序的时候都是插入排序。
def do_sth(testlist, step_length):
for i in range(step_length, len(testlist)):
tmp = testlist[i]
while i >= step_length:
if testlist[i-step_length] > tmp:
testlist[i] = testlist[i-step_length]
if i == step_length + i % step_length:
testlist[i%step_length] = tmp
i -= step_length
else:
testlist[i] = tmp
break
def sorted_by_xier(testlist):
step_length = len(testlist)//2
while step_length >= 1:
do_sth(testlist, step_length)
step_length //= 2
print(test_list)
sorted_by_xier(test_list)
print(test_list)
# do_sth 另一种实现
def do_sth(testlist, step_length):
for i in range(step_length, len(testlist)):
tmp = testlist[i]
stop_index = step_length + i % step_length
for j in range(i, stop_index-1, -step_length):
if testlist[j-step_length] > tmp:
testlist[j] = testlist[j-step_length]
if j == stop_index:
first_index = i % step_length
testlist[first_index] = tmp
else:
testlist[j] = tmp
break
# do_sth 另一种实现
def do_sth(li, step_length):
for i in range(step_length, len(li)):
tmp = li[i]
j = i - step_length
while j >= 0 and tmp < li[j]:
li[j + step_length] = li[j]
j -= step_length
li[j + step_length] = tmp
# 二次复习时的实现
def do_sth(testlist, step_length):
# 由于是分step_length个组,所以,下标0到下标step_length-1,就是初始化的step_length个组
# 且每个组里都有一个元素,从下标为step_length这个元素开始到最后一个元素结束,都是需要进行
# 插入排序的
for i in range(step_length, len(testlist)):
# 先记录要插入元素的值
need_insert_value = testlist[i]
# 找到要插入元素所在组里前一个元素的下标
front_element_index = i - step_length
while front_element_index >= 0:
# 如果前一个元素的值大于要插入元素的值,那么前一个元素后移一个位置
if testlist[front_element_index] > need_insert_value:
testlist[front_element_index+step_length] = testlist[front_element_index]
front_element_index -= step_length
else:
break
testlist[front_element_index+step_length] = need_insert_value# 计数排序
test_list = [5, 4, 8, 6, 3, 1]
count = max(test_list)
count_list = [0]*(count+1)
for i in test_list:
count_list[i] += 1
test_list = []
for index, value in enumerate(count_list):
if value > 0:
for _ in range(value):
test_list.append(index)
print(test_list)# 桶排序
# 基本套路
test_list = [45, 48, 38, 26, 32, 19, 34, 21, 29, 27]
n = 5 # 桶个数
out_put = [list() for _ in range(n)]
for i in test_list:
if 0 <= i <= 9:
if len(out_put[0]):
for index, value in enumerate(out_put[0]):
if i < value:
out_put[0].insert(index, i)
break
else:
out_put[0].append(i)
elif 10 <= i <= 19:
if len(out_put[1]):
for index, value in enumerate(out_put[1]):
if i < value:
out_put[1].insert(index, i)
break
else:
out_put[1].append(i)
elif 20 <= i <= 29:
if len(out_put[2]):
for index, value in enumerate(out_put[2]):
if i < value:
out_put[2].insert(index, i)
break
else:
out_put[2].append(i)
elif 30 <= i <= 39:
if len(out_put[3]):
for index, value in enumerate(out_put[3]):
if i < value:
out_put[3].insert(index, i)
break
else:
out_put[3].append(i)
else:
if len(out_put[4]):
for index, value in enumerate(out_put[4]):
if i < value:
out_put[4].insert(index, i)
break
else:
out_put[4].append(i)
order_list = []
for i in out_put:
order_list.extend(i)
print(order_list)
# ===============================
# 进阶一下,将重复代码,去重
test_list = [45, 48, 38, 26, 32, 19, 34, 21, 29, 27]
n = 5 # 桶个数
def bucket_sort(li, num, max_value):
"""
:param li: 待排序list
:param num: 桶个数
:param max_value: 桶中最大值
:return:
"""
out_put = [list() for _ in range(n)]
for i in li:
# 计算每个桶的容量, 由于存在余数的问题,要确保余数有处安放,所以需要加1
# 就好比, 9*5 = 45 ,5个桶,可以放9个球,0号球也是球,所以,所有桶放满
# 最多可以放到编号44的球,那么刚好用于整除的45号~49号共5个球都没地方放,
# 5个桶,剩余5个球放不进去,所以只需要给每个桶扩容一个单位就可以了,这就是加1的意义
# 当然,也可以采取另一个方案:which_bucket = min(i//max_value//num, n-1) 这种也行
bucket_volume = max_value//num + 1
# 计算需要将数字放到哪个桶,这里which_bucket刚好是桶容量的倍数,这就决定了数字放
# 到哪个桶
which_bucket = i//bucket_volume
if len(out_put[which_bucket]):
for index, value in enumerate(out_put[which_bucket]):
# 这里是从左往右一个一个看值,所以,需要找到第一个比自己大的值的下标,
# 就是要插入的位置
if i < value:
out_put[which_bucket].insert(index, i)
break
else:
# 如果自己是目前桶里最大数,那么直接放入最后的位置
out_put[which_bucket].append(i)
else:
out_put[which_bucket].append(i)
order_list = []
for i in out_put:
order_list.extend(i)
print(order_list)
bucket_sort(test_list, 5, max(test_list))# 基数排序
# 基础排序的原理是,先按个位数排序,给0~9,共10个桶,先排序一波,就会产生相对位置有序
# 然后,对已经排过依次序的队列,再次排序,这次对十位进行排序,依旧给0~9,共10个桶,依次类推
# 最后给最大数的最大位进行排序,结束后,就可以得到有序序列。
# 这个过程,举个例子,25和29,先对个位排序,9在后,就导致了第一次排序29的相对位置一定在25后,
# 那么再次以十位进行排序的时候,这两个数的十位都是2,那么由于各位排序的原因,25相对于29在前面,
# 所以新的序列25一定先入队,29后入队,所以,这样就导致了它们的有序性。假如是35,和25,那么个位
# 排序的时候,个位按原先的位置入队,但是第二轮排序的时候,2的相对位置在3前面,一样可以让其有序
# 这是以字符串的模式去做的取数字位数,其实也可以使用数学的方式取位数
test_list = [45, 48, 38, 26, 32, 19, 34, 21, 29, 27, 251]
# 找出位数最多的值
max_num = max(test_list)
# 计算位数,这将决定排几次
n = len(str(max_num))
while n >= 1:
# 制作桶
out_put = [[] for _ in range(10)]
for i in test_list:
if len(str(i)) < n:
i = (n - len(str(i)))*'0' + str(i)
out_put[int(i[n - 1])].append(i)
else:
i = str(i)
out_put[int(i[n - 1])].append(i)
new_list = []
for i in out_put:
new_list.extend(i)
test_list.clear()
test_list = new_list
n -= 1
print([int(i) for i in test_list])
# =================
# 这是数学的方法去取位数....
# 找出位数最多的值
max_num = max(test_list)
n = 0
while 10**n <= max_num:
# 制作桶
buckets = [[] for _ in range(10)]
for i in test_list:
# 选择排序用的位数
index = int((i/10**n)%10)
buckets[index].append(i)
test_list = []
for i in buckets:
test_list.extend(i)
n += 1
print(test_list)class Queue:
"""
构建队列
"""
def __init__(self, size=50):
"""
由于需要区分空队列和满队列,所以,最大存放量为 size-1
:param size: 队列的大小
"""
self.head = 0
self.end = 0
self.size = size
self.queue = [0 for _ in range(size)]
def push(self, element):
"""
添加元素
:param element:
:return:
"""
if not self.is_full():
self.end = (self.end+1) % self.size
self.queue[self.end] = element
else:
raise Exception("当前队列已满,无法添加新元素")
def pop(self):
"""
取元素
:return:
"""
if not self.is_empty():
self.head = (self.head+1) % self.size
return self.queue[self.head]
else:
raise Exception("当前队列为空,无法取值")
def is_empty(self):
"""
判定队列是否为空
:return:
"""
return self.head == self.end
def is_full(self):
"""
判断队列满员
:return:
"""
if (self.end+1) % self.size == self.head:
return True
else:
return False
a = Queue()
for i in range(49):
a.push(i)
print(a.is_full())
print(a.pop())# 迷宫问题(深度优先)
maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
]
dirs = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y + 1),
lambda x, y: (x, y - 1),
]
def maze_path(start_x, start_y, end_x, end_y):
"""
迷宫出路
这东西,就是不断的试错,直到找到一条对的路径出来
:param start_x: 起点横坐标
:param start_y: 起点纵坐标
:param end_x: 终点横坐标
:param end_y: 终点纵坐标
:return:
"""
path_list = list() # 把它当成一个栈
path_list.append((start_x, start_y)) # 把起点先输入进去
maze[start_y][start_x] = 2 # 将起点标记为已经走过了,否则可能会重复起点路线
while path_list: # 当没有任何一个节点在path_list的时候,就说明,无路可走了,就无需在循环试错了
current_node = path_list[-1] # 当前节点一定是栈顶元素
# 如果栈顶元素刚好等于出口元素,就说明,已经走到出口处了
if current_node[0] == end_x and current_node[1] == end_y:
for i in path_list:
print(i)
return True
for next_node in dirs:
x_path = next_node(current_node[0], current_node[1])[0]
y_path = next_node(current_node[0], current_node[1])[1]
if maze[y_path][x_path] == 0: # 说明该点的值是0,是可以走的
path_list.append((x_path, y_path)) # 将这个点放入栈中,开始以这个点进行下一轮路径试错
maze[y_path][x_path] = 2 # 将这个点标记为已经走过了,因为规定不走回头路
break
else:
# 如果上下左右4个点都不能走,那么说明这个节点无路可走,需要回退到上一个节点再次进行路径试错
# 将当下节点标记为已经走过
maze[current_node[1]][current_node[0]] = 2
path_list.pop() # 将当下节点去除,这样栈的元素就等于进行到了之前的点,等于回退的效果
else:
# 如果最终path_list空了,就代表,无路可走,没有路可以到达终点
return False
maze_path(1, 1, 8, 8)maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
]
dirs = [
lambda x, y: (x + 1, y),
lambda x, y: (x - 1, y),
lambda x, y: (x, y + 1),
lambda x, y: (x, y - 1),
]
# 广度优先
# 这里有3个奥义:
# 1、这是类似于探路,将所有可以走的路线全部派人打探,而最先走到出口的路线,就是最短路线
# 2、这个过程是有序的,每一轮都是往前走一步,每一轮结束后会开启下一轮的探路,同期的那一
# 轮是存在先后顺序的,这将导致排在前面的先选择路,若是被选择了,那么后面的人在探路的
# 时候就不可以选择这些已选择的路了。
# 3、列表里存的点,理解起来更像是方向,或者毛线的线头
from collections import deque
def maze_path_quque(start_x, start_y, end_x, end_y):
"""
迷宫出路(广度优先,寻找最短路线)
这东西,往各个可能的方向找出路,直到最快的那个探马找到路线结束,或者压根没有出路,最后直接结束
:param start_x: 起点横坐标
:param start_y: 起点纵坐标
:param end_x: 终点横坐标
:param end_y: 终点纵坐标
:return:
"""
# 制作存储节点的信息对象,因为每个节点,都需要绑定其来自于哪,就是它哪个节点的下一个节点
# 这只需存储其来自的那个节点的下标就可以了,最后,我们将根据出口的节点寻找整个路线的节点
start_node_msg = {
'local_node': (start_x, start_y),
'from_node_index': 'start'
}
direct_queue = deque() # 制作存储可试探方向的队列
direct_queue.append(start_node_msg) # 将起点存入队列
maze[1][1] = 2
pop_list = list() # 制作收集所有已经走过节点的队列
# 只要队列有内容,那么就说明还需要接着探寻路线,但是如果队列空了,那就说明,无路可走,没有出路了
while deque:
current_mode = direct_queue.popleft() # 开始循环,取队列头部元素,对其进行路线探索操作
# 将取出来的头部元素存起来,主要是根据这个头部元素而探索出来的后面元素需要知道这个头部元素的下标,以便最后回溯路径
pop_list.append(current_mode)
# 当从头部取出的待探索元素就是出口元素时,那就说明已经找到了最近路线的出口
if current_mode['local_node'][0] == end_x and current_mode['local_node'][1] == end_y:
index_node = pop_list[-1]
path = list()
# 根据下标寻找路线上的所有元素,并将其保存起来,就成为了完整的路线记录
while index_node['from_node_index'] != 'start':
path.append(index_node['local_node'])
index = index_node['from_node_index']
index_node = pop_list[index]
# 由于是从出口开始往入口找的路线,所以需要逆序排序一下,这样就可以得到从入口到出口的路线了
path.reverse()
for i in path:
print(i)
return True
for get_node in dirs:
node = get_node(current_mode['local_node'][0], current_mode['local_node'][1])
if maze[node[1]][node[0]] == 0:
# 将根据这个头部元素而探索出来的后面元素存到待探索目录,并且将其标记为以探索状态
noda_data = {
'local_node': node,
'from_node_index': len(pop_list) - 1
}
direct_queue.append(noda_data)
maze[node[1]][node[0]] = 2
else:
print('没有可以抵达终点的道路')
maze_path_quque(1, 1, 8, 8)# 链表
class Node:
def __init__(self, value):
self.value = value
self.next = None
def insert_head(self, head, node):
"""
头插法
:param head: 链表的链头
:param node: 要插入的节点
:return: 新的链表头节点
"""
node.next = head
return node
def insert_end(self, end, node):
"""
尾插法
:param end: 链表尾部节点
:param node: 要插入的节点
:return: 新的尾部节点
"""
end.next = node
return node
def get_end_node(self, head):
"""
获取尾部节点
:param head:
:return:
"""
current_node = head
while True:
next_node = current_node.next
if next_node is None:
return current_node
current_node = next_node
def show_all_value(self, head):
"""
显示所有节点的值
:param head:
:return:
"""
current_node = head
while True:
print(current_node.value, end=',')
if not current_node.next:
return
current_node = current_node.next
# 创建链表,头插法(方法一)
def create_link_list_head(lists):
head_node = None
for i in lists:
node = Node(i)
node.next = head_node
head_node = node
return head_node
# 创建链表,头插法(方法二)
def create_link_list_head(lists):
head_node = Node(lists[0])
for i in lists[1:]:
node = Node(i)
head_node = head_node.insert_head(head_node, node)
return head_node
# 创建链表,尾查法(方法一)
def create_link_list_end(lists):
head_node = None
end_node = None
for i in lists:
node = Node(i)
# 只有第一次循环的时候需要构建链表的链头需要进入这个if,后面的都不需要
if head_node is None:
head_node = node
end_node = node
continue
end_node.next = node
end_node = node
return head_node
# 创建链表,尾查法(方法二)
def create_link_list_end(lists):
head_node = end_node = Node(lists[0])
for i in lists[1:]:
node = Node(i)
end_node = end_node.insert_end(end_node, node)
return head_node
head_node = create_link_list_head([1, 2, 3, 4, 5])
head_node.show_all_value(head_node)
print('')
print('===============')
head_node = create_link_list_end([1, 2, 3, 4, 5])
head_node.show_all_value(head_node)# 链表进阶之可迭代链表
# 链表类
class LinkTable:
"""
制作可以直接 for 循环的链表类
"""
class LinkListIterator:
"""
制作可迭代对象
"""
def __init__(self, head_node):
self.head_node = head_node
def __iter__(self):
return self
def __next__(self):
if self.head_node:
value = self.head_node.value
self.head_node = self.head_node.next
return value
else:
raise StopIteration
class Node:
"""
制作单向链表节点
"""
def __init__(self, value):
self.value = value
self.next = None
def __init__(self, iterable):
self.head_node = None
self.end_node = None
self.extend(iterable)
def extend(self, iterable):
"""
将可迭代对象添加到链表
:param iterable:
:return:
"""
for i in iterable:
self.append(i)
def append(self, value):
node = self.Node(value)
if self.head_node is None:
self.head_node = self.end_node = node
else:
self.end_node.next = node
self.end_node = node
def __iter__(self):
return self.LinkListIterator(self.head_node)
def __repr__(self):
return '[' + ','.join(map(str, self)) + ']'
def find(self, value):
for i in self:
if i == value:
return True
return False
a = LinkTable([1, 2, 3, 4, 5])
print(a)
print(a.find(3))
print(a.find(8))# 哈希表。
# 这里需要配合上面的链表使用
class HashTable:
def __init__(self, table_lens=51):
"""
:param table_lens: 可存入表的内容是无限的,但是表的长度是有限的,这里就需要设置表的长度了
"""
self.table = [LinkTable([]) for _ in range(table_lens)]
self.size = table_lens
def my_hash(self, key):
"""
hash表的本质就是一个直取表加一个hash函数
:param key: 将关键字通过hash函数转化为直取表下标
:return:
"""
index = key % self.size
return index
def insert(self, key):
"""
现在模拟的是集合的插入
:param key: 要插入的对象
:return:
"""
# 先计算存储到哈希表的位置
index = self.my_hash(key)
# 然后查看该位置是否已经存在和key一样的值,因为集合是没有重复元素的
result = self.table[index].find(key)
if not result:
self.table[index].append(key)
return 'Success'
else:
return '该值已存在,无法插入'
def show_all(self):
for i in self.table:
print(i, end=',')
a = HashTable()
print(a.insert(1))
print(a.insert(2))
print(a.insert(1))
print(a.insert(52))
a.show_all()# 二叉搜索树
class Node:
def __init__(self, value):
"""
制作节点
:param value:
"""
self.value = value
self.left_node = None
self.right_node = None
self.parent_node = None
def __repr__(self):
return str(self.value)
class BST:
"""
制作二叉搜索树
"""
def __init__(self, lists=None):
self.root = None
if lists:
for i in lists:
self.insert_func2(i)
def insert(self, node, value):
"""
递归插入
:param node:
:param value:
:return:
"""
if node is None:
build_node = Node(value)
return build_node
elif node.value > value:
node.left_node = self.insert(node.left_node, value)
node.left_node.parent_node = node
return
elif node.value < value:
node.right_node = self.insert(node.right_node, value)
node.right_node.parent_node = node
return
def insert_func2(self, value):
"""
非递归插入
:param value:
:return:
"""
current_node = self.root
# 加入这个搜索二叉树不存在,要插入的这个是第一个节点,那么直接为根节点赋值即可
if current_node is None:
self.root = Node(value)
return
# 假如存在搜索二叉树,那么就需要找到最边缘的位置,对其进行插入
while True:
if current_node.value > value:
left_node = current_node.left_node
# 如果当下节点的左子节点是None,那么就新造一个节点,将其插入到这里即可
if left_node is None:
node = Node(value)
current_node.left_node = node
node.parent_node = current_node
return
else:
# 如果当下节点的左子节点存在节点,那么,这个节点就是新的当下节点,接着往下搜索
current_node = current_node.left_node
continue
# 跟上面的左子节点流程一样
elif current_node.value < value:
right_node = current_node.right_node
if right_node is None:
node = Node(value)
current_node.right_node = node
node.parent_node = current_node
return
else:
current_node = current_node.right_node
continue
def find(self, node, value):
if node.value == value:
return node
elif node.value > value:
if node.left_node is None:
return '没有该节点'
return self.find(node.left_node, value)
else:
if node.right_node is None:
return '没有该节点'
return self.find(node.right_node, value)
def delete(self, value):
# 如果是空树,那就别删了,直接返回,没东西删啥啊
if not self.root:
return 'failure'
node = self.find(self.root, value)
# 不存在的节点,也没啥可删的
if node == '没有该节点':
return 'failure'
# 这里有一种特殊情况,就是根节点的情况
# 假如二叉搜索树只有一个根节点,那么删除也就只能是删除根节点了
if node.parent_node is None and node.left_node is None and node.right_node is None:
self.root = None
return 'success'
# 假如二叉搜索树的根节点只有左子节点,没有右子节点,现在要删根节点,这时候是无需判断要删的节点属于
# 父节点的左子节点还是右子节点的,因为根节点就自己一个,这也是和后面普通情况不一样的地方
if node.parent_node is None and node.left_node is not None and node.right_node is None:
self.root = node.left_node
node.left_node.parent_node = None
return 'success'
# 二叉搜索树的根节点只有右子节点,没有左子节点,现在要删根节点,同上
if node.parent_node is None and node.left_node is None and node.right_node is not None:
self.root = node.right_node
node.right_node.parent_node = None
return 'success'
# 二叉搜索树的根节点有右子节点,有左子节点,现在要删根节点
if node.parent_node is None and node.left_node is not None and node.right_node is not None:
min_node = self.find_min_node(node.right_node)
self.delete(min_node.value)
self.root = min_node
min_node.left_node = node.left_node
min_node.right_node = node.right_node
min_node.parent_node = None
if node.left_node:
node.left_node.parent_node = min_node
if node.right_node:
node.right_node.parent_node = min_node
return 'success'
# 接下来就是普通的情况了...其实这样写稍微有点乱,因为一共就是4种情况,可以将4种情况分开写,根节点和普通的情况合到一起
parent = node.parent_node
parent_value = parent.value
if node.left_node is None and node.right_node is None:
# 说明要删除的节点是最边边的叶节点
if parent_value < value:
parent.right_node = None
else:
parent.left_node = None
elif node.left_node is None and node.right_node is not None:
# 说明要删除的节点存在右子节点,不存在左子节点
if parent_value < value:
parent.right_node = node.right_node
else:
parent.left_node = node.right_node
node.right_node.parent_node = parent
elif node.left_node is not None and node.right_node is None:
# 说明要删除的节点存在左子节点,不存在右子节点
if parent_value < value:
parent.right_node = node.left_node
else:
parent.left_node = node.left_node
node.left_node.parent_node = parent
else:
# 说明要删除的节点既有左节点,又有右节点
min_node = self.find_min_node(node.right_node)
# 因为,这种场景是需要将当下节点的右子节点的最小节点给移动到当下节点的位置的
# 所以,就又需要将当下节点的右子节点的最小节点给删了,所以,就有需要执行一遍
# 删除动作,只是,由于当下节点的右子节点的最小节的特殊性(左子节点为None),
# 所以,肯定只会走上面的情况,不会走到最后这种情况,因此也不存在形成递归一说
self.delete(min_node.value)
if parent_value < value:
parent.right_node = min_node
else:
parent.left_node = min_node
min_node.left_node = node.left_node
min_node.right_node = node.right_node
min_node.parent_node = parent
if node.left_node:
node.left_node.parent_node = min_node
if node.right_node:
node.right_node.parent_node = min_node
return 'success'
def find_min_node(self, node):
"""
寻找给定节点下的最小节点
:param node:
:return:
"""
min_node = node
while True:
if min_node.left_node is None:
return min_node
min_node = min_node.left_node
# 前序遍历
def show_all_value_pre(self, node):
if node:
print(node.value, end=',')
self.show_all_value_pre(node.left_node)
self.show_all_value_pre(node.right_node)
# 中序遍历
def show_all_value_mid(self, node):
if node:
self.show_all_value_mid(node.left_node)
print(node.value, end=',')
self.show_all_value_mid(node.right_node)
# 后序遍历
def show_all_value_end(self, node):
if node:
self.show_all_value_end(node.left_node)
self.show_all_value_end(node.right_node)
print(node.value, end=',')
a = BST([5, 1, 3, 4, 2])
a.show_all_value_mid(a.root)
print()
print(a.find(a.root, 3))
a.delete(3)
a.show_all_value_mid(a.root)
print()
a.delete(2)
a.show_all_value_mid(a.root)# 背包问题
goods = [(60, 10), (100, 20), (120, 30)] # (价格, 重量)
goods.sort(key=lambda x: x[0]/x[1], reverse=True)
def get_max_value(goods, wight_package):
all_price = 0
num = [0 for _ in range(len(goods))]
for index, (price, wight) in enumerate(goods):
num[index] = 1 if wight_package >= wight else wight_package/wight
all_price += price*num[index]
wight_package -= wight
if wight_package == 0:
break
return num, all_price
print(get_max_value(goods, 50))# 钢条切割问题
# price是钢条的价格,而列表price的下标则代表钢条的长度,如,下标为1的就是一米钢条价格1块
# 下标为2的就是2米钢条价格5块,依此类推
# 现在要求,将长度为n的钢条切割,求切割后可以卖到的最高价钱
price = [0, 1, 5, 8, 9, 10, 17, 17, 20, 21, 23, 24, 26, 27, 27, 28, 30, 33, 36, 39, 40]
# 这里有两种思路,一种是从做事的角度的来理解这个问题,一种是从数学的角度分析这个问题
# 首先先分析下整个过程,一个长度为n的钢条它可以切多少刀,这个很好理解,最多可以切n-2刀,
# 也可以是n-1刀,这主要看对n的理解了,比如画一个x轴,从0开始算,0到3,经历了0,1,2,3,可以切
# 的点就是1,2,这就是n-1刀了,但是如果是找一个绳子,最左端算1,最右端算3,那么就是n-2刀,
# 所以,这里的 n-1, 还是n-2取决于起始值是0还是1,这个就比较主观了,都可以,我这里按照起始为0算,也就是可以切n-1刀,
# 接下来,每个可以切的点,都是有2个选择,那就是切,或者不切,所以一共就有2^(n-1)次方种切法
# 关于这点,完全没问题,没有任何争议
# 接下来,先看第一种思路
# 从可切的节点入手,对于每一节点,我们依次选择每一个节点,将整个钢条分成2段,然后分别对左边一段和
# 右边一段求它们的最优解,然后,将2边最多可以卖的钱数加起来得到的就是这种切法,最多可以卖的价钱
# 理论上是如此,但是这种,重复的计算比较多,效率就比较低下了
def cut_and_get_max_value_1(price, n):
"""
从做事的角度的来解这个问题
:param price: 价格列表
:param n: 钢条长度
:return:
"""
# 先记录不切的时候的价格,姑且当它就是可以卖的最大价钱
max_value = price[n]
# 开始切每一个节点,这里注意,最后一个节点的位置是n-1,当完成所有节点对应的最大值的比较后,就得到了最终的最大值
for node in range(1, n):
# 获取每一种节点切法的最大值,举个例子,比如长度为5的钢条切第2个节点,那么拿到的就是长度为2和长度为3的2个钢条
# 长度为2的钢条的最优解 + 长度为3的钢条的最优解,就是这种切法下,长度为5的钢条可以卖的最高的价钱
max_value = max(max_value,
cut_and_get_max_value_1(price, node) + cut_and_get_max_value_1(price, n - node))
return max_value
print(cut_and_get_max_value_1(price, 10))
# 第二种,是按照数学分析的办法来解
# 举个例子
# 假设有5个节点 0 。 。 。 。 。 6 长度为6的钢条,这样就可以切5次
# 然后还是老样子,所有的情况是 2^(n-1)次方种
# 接下来,一个一个分析节点
# 假如第一个节点切: 0 。 。 。 。 。 6 得到的结果是 1,和后面所有组合的最大值之和,就是整体最大值
# 假如第一个节点不切 0 . 。 。 。 。 6 这个时候就意味着前两个板子已经连接起来了,需要看第二个节点的情况了
# 假如第二个节点切 0 . 。 。 。 。 6 得到的结果就是2,和后面所有组合的最大值之和,就是整体最大值
# 假如第二个节点不切 0 . . 。 。 。 6 这个时候就意味着前三个板子已经连接起来了,需要看第三个节点的情况了
# 依次类推,就可以发现,整个的过程就是,第一个板子 + 后面所有组合的价格; 第二个板子 + 后面所有组合的价格;
# 一直到整个板子,和后面,0个板子的所有组合的价钱,这就是所有的可能性了
def cut_and_get_max_value_2(price, n):
"""
按照数学分析的办法来解这个问题
:param price: 价格列表
:param n: 钢条长度
:return:
"""
max_value = 0 # 这个值随便给,无所谓
# 这次是需要讨论最终结果,所有板子和后面0个板子的切割方案,所以要保证node可以取到n
for node in range(1, n+1):
# 从节点算,节点的左边,就是一个整体,直接查其价格即可,节点的右边就是需要求最优解了,两者之和就是整个钢条
# 当下情况下的售价最优解
max_value = max(max_value, price[node] + cut_and_get_max_value_2(price, n-node))
return max_value
print(cut_and_get_max_value_2(price, 10))
# 以上2种解法,都是基于从上向下式的解法,拿到一个值,使劲递归,最后触底反弹回归,这样会有大量的重复运算
# 而从下往上进行计算,将每一个节点切法的最优解记录下来,那么,这种解法效率就很高了
def cut_and_get_max_value_3(price, n):
"""
按照数学分析的办法来解这个问题
:param price: 价格列表
:param n: 钢条长度
:return:
"""
max_value_list = [0] # 当钢条长度为0的时候,最优解,就是0,没卖东西当然没有收益了
# 要求n的最优解,需要将n之前的所有最优解都求出来,并存起来,比如长10的钢条最优解是27,将它存起来
# 然后剩下的思路跟上面数学分析的思路就一样了
for i in range(1, n+1):
# i 代表钢板总长度
max_value = price[i] # 完全不切割情况下的售价
# 求每个节点的最优解
for node in range(1, i):
max_value = max(max_value, price[node] + max_value_list[i - node])
# 将求得的最优解存起来
max_value_list.append(max_value)
# 这样以来,max_value_list里最后一个就是长度为n的钢条的最优解了
return max_value_list[n]
print(cut_and_get_max_value_3(price, 10))
# 上面的方案只能得到最优方案的钱数,但是无法得到最优方案的操作,看下面的解决方案
def cut_and_get_max_value_4(price, n):
"""
按照数学分析的办法来解这个问题
:param price: 价格列表
:param n: 钢条长度
:return:
"""
max_value_list = [0] # 当钢条长度为0的时候,最优解,就是0,没卖东西当然没有收益了
cutting_programme = [0] # 记录切割方案,这样既能得到最优解,又能得到具体得到最优解的方式
# 要求n的最优解,需要将n之前的所有最优解都求出来,并存起来,比如长10的钢条最优解是27,将它存起来
# 然后剩下的思路跟上面数学分析的思路就一样了
for i in range(1, n+1):
# i 代表钢板总长度
max_value = price[i] # 完全不切割情况下的售价
left_length = 0
# 求每个节点的最优解
for node in range(1, i):
old_max_value = max_value
max_value = max(max_value, price[node] + max_value_list[i - node])
# 只有新的max_value产生的时候,就意味着新的最优切割左边定长产生
if max_value > old_max_value:
left_length = node
# 将求得的最优解存起来
max_value_list.append(max_value)
# 将求得的最优切割的左侧定长板子收集起来
cutting_programme.append(left_length)
# 这样以来,max_value_list里最后一个就是长度为n的钢条的最优解了
# 同时通过下面的函数,可以获得最优解切割方案
return max_value_list[n], get_cutting_programme(cutting_programme, n)
# 获取最优解
def get_cutting_programme(cutting_programme_list, n):
"""
获取最优解
:param cutting_programme_list: 最优解切割表, 比如,长度为4的板子,最优解时,左边切到节点2,其剩余
长度就为2,2的最优解切割节点是0,就是不切的意思,那么,长度为4的板子
最有切割解就是从节点2切一刀
:param n: 钢条长度
:return:
"""
cutting_programme = []
# 剩余长度的钢条,最开始就是整个钢条,每次切掉最优解时的左边完整部分,剩余的再找最优解左边的完整位置
remain_length = n
while True:
# 获得第一刀的位置,也就是第一刀后得到的最左边完整板子的长度
left_cut_length = cutting_programme_list[remain_length]
cutting_programme.append(left_cut_length)
# 获得剩余板子的长度,接下来就是切割剩余板子了,同时获得剩余板子第一刀的位置
remain_length -= left_cut_length
# 当剩余板子不需要切割的时候,就说明,切割结束了
if cutting_programme_list[remain_length] == 0:
cutting_programme.append(remain_length)
break
return cutting_programme
print(cut_and_get_max_value_4(price, 10))
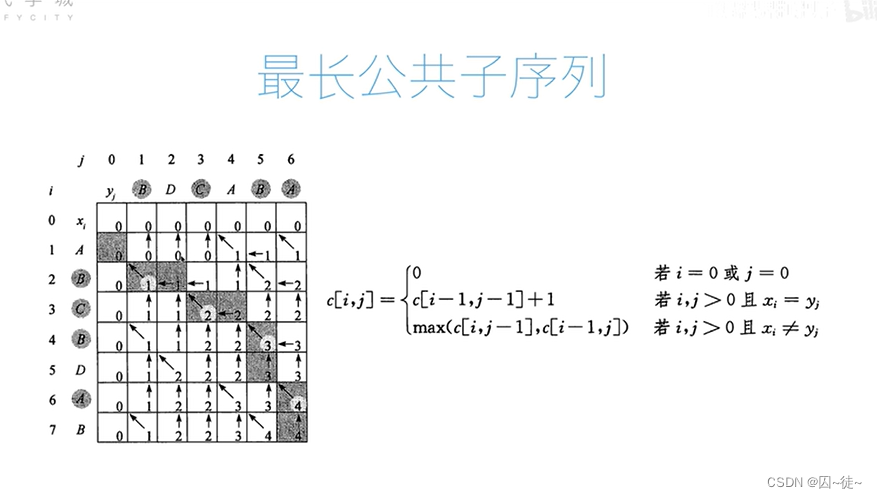
# 最长公共子序列
# 问题分析:关于这个问题,其实一共就3种情况
# 第一种:空字符串,它和任何字符串都不会有公共子序列
# 第二种:2个字符串,最后一个字符是一样的,那么这个字符肯定就是公共子序列中的最后一个字符,
# 那么,最长公共子序列的长度就一定等于2个字符串都去掉最后这个字符的最长公共序列的长度 + 1(1就是2个字符串最后一样的那个字符)
# 第三种:2个字符串,最后一个字符是不一样的,那么我们可以先假定第一个字符串的最后一个字符是公共子序列的最后一个字符
# 由于第二个字符串最后一个字符是跟第一个字符串最后一个字符是不一样的,换言之,第二个字符串的最后一个字符不是公共序列
# 的字符,也就是说,公共序列的最后一个字符一定是出现在第二个字符串最后一个字符之前,也就是说这两个字符串的公共序列的
# 最长值,可以由第一个字符串和第二个字符串的前n-1个字符求得。同理我们假定最长公共序列的最后一个字符是第二个字符串的
# 最后一个字符,那么同理可得,这两个字符串的公共序列的最长值,可以由第二个字符串和第一个字符串的前n-1个字符求得。然后
# 我们对这两种结果,取最大值就可以了。
# 这样以来整个过程就可以图解为一个x轴,y轴的二维表,而相关联的只有3个值,lcs_list[x-1][y-1], lcs_list[x][y-1], lcs_list[x-1][y]
# 所有情况,都由这3个值演化而出,所以搞成二维阵列后,就可以从最初的值开始算起,就成了填空空了,填完所有空,就得到了所有答案,
# 需要哪个就直接取值就可以了
# 0 a b c d e a
# - - - - - - -
# 0 |
# s |
# c |
# d |
# [0, 0, 0, 0, 0, 0, 0]
# [0, 0, 0, 0, 1, 1, 1]
# [0, 1, 1, 1, 1, 2, 2]
# [0, 1, 1, 2, 2, 2, 2]
# [0, 1, 1, 2, 2, 3, 3]
# [0, 1, 2, 2, 2, 3, 3]
# [0, 1, 2, 2, 3, 3, 4]
# [0, 1, 2, 2, 3, 4, 4]
def lcs_length_1(a, b):
"""
最长公共子序列的求解, 之求最长公共子序列的长度
:param a: 字符串 a
:param b: 字符串 b
:return:
"""
# 构建二维表,这里注意,构建的时候,由于存在空字符串的情况,横纵轴的第一个值都为0,这个0就代表空字符串的情况
lcs_list = [[0 for _ in range(len(a)+1)] for _ in range(len(b)+1)]
# 由于第一列和第一行都分别对应x,y轴的空字符串,所以它们的值都为0,所以,就不用填写它们的值了
# 直接从第二行开始填,对应的也从第二列开始填
for y in range(1, len(b)+1):
# 具体开始填空了,一行一行的填
for x in range(1, len(a)+1):
# 这里注意,因为x,y都是从1开始执行的,就等于一定将第一种情况都跳过了,直接用二维表中默认的0就可以了
# 所有直接讨论第二,第三种情况即可
# 另外,我们这里的x,y都是指字符串的长度,要取字符串的下标,肯定是要减1的
if a[x-1] != b[y-1]:
lcs_list[y][x] = max(lcs_list[y-1][x], lcs_list[y][x-1])
else:
# 这一步,就等于是说去掉2个字符串相同的尾巴,求其之前的最大公共序列然后补上最后一个相同的字符即可
lcs_list[y][x] = lcs_list[y-1][x-1] + 1
return lcs_list
lcs_list = lcs_length_1('BDCABA', 'ABCBDAB')
for i in lcs_list:
print(i)
print(lcs_list[len('ABCBDAB')][len('BDCABA')])
def lcs_length_2(a, b):
"""
最长公共子序列的求解,之求最长公共子序列的内容
:param a: 字符串 a
:param b: 字符串 b
:return:
"""
# 构建二维表,这里注意,构建的时候,由于存在空字符串的情况,横纵轴的第一个值都为0,这个0就代表空字符串的情况
lcs_list = [[0 for _ in range(len(a)+1)] for _ in range(len(b)+1)]
# 构建一个收集最长公共序列的路径表格,这将决定按照终点找起点,收集所有的公共序列的组成元素
# 定义left就是当下节点的值来自左边,up就是当下节点的值来自上边,lean就是来自于斜上方
come_from_list = [[0 for _ in range(len(a)+1)] for _ in range(len(b)+1)]
comment_list = []
# 由于第一列和第一行都分别对应x,y轴的空字符串,所以它们的值都为0,所以,就不用填写它们的值了
# 直接从第二行开始填,对应的也从第二列开始填
for y in range(1, len(b)+1):
# 具体开始填空了,一行一行的填
for x in range(1, len(a)+1):
# 这里注意,因为x,y都是从1开始执行的,就等于一定将第一种情况都跳过了,直接用二维表中默认的0就可以了
# 所有直接讨论第二,第三种情况即可
# 另外,我们这里的x,y都是指字符串的长度,要取字符串的下标,肯定是要减1的
if a[x-1] != b[y-1]:
lcs_list[y][x] = max(lcs_list[y-1][x], lcs_list[y][x-1])
if lcs_list[y-1][x] >= lcs_list[y][x-1]:
come_from_list[y][x] = 'up'
else:
come_from_list[y][x] = 'left'
else:
# 这一步,就等于是说去掉2个字符串相同的尾巴,求其之前的最大公共序列然后补上最后一个相同的字符即可
lcs_list[y][x] = lcs_list[y-1][x-1] + 1
come_from_list[y][x] = 'lean'
x = len('BDCABA')
y = len('ABCBDAB')
while True:
from_node = come_from_list[y][x]
if from_node == 'left':
x -= 1
elif from_node == 'up':
y -= 1
elif from_node == 'lean':
# 只有在这种情况下,就意味着当下节点是当下长度的字符串的最大公共序列的最后一个元素
# 注意是,最后一个公共元素,所以保存的时候,新的就不断往前插入,确保第一个进队的元素最后处于最后面的位置
comment_list.insert(0, a[x-1])
x -= 1
y -= 1
else:
# 最后一种情况,就是from_node==0了,也就走到尽头了,这点可以看打印的结果,只有边界是不被赋值的
break
return comment_list, lcs_list
print(lcs_length_2('BDCABA', 'ABCBDAB')[0])
















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









