







1)先下载lzo的jar项目
2)下载后的文件名是一个zip格式的压缩包,先进行解压,然后用maven编译。
3)将编译后的jar包 放入hadoop/share/hadoop/common/目录下。
4)将jar包同步到集群。
5)core-site.xml增加配置支持LZO压缩
6)同步core-site.xml到集群。
二.然后重启hadoop集群,创建一个input目录,上传一个文件到该目录
[@hadoop102hadoop-3.1.3]$ hadoop fs -mkdir /input
[@hadoop102 hadoop-3.1.3]$ hadoop fs -put README.txt
将input下的该文件进行wordcount,希望输出的内容是压缩的,则进行以下操作
[@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount -Dmapreduce.output.fileoutputformat.compress=true -Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec /input /output
解释: -Dmapreduce.output.fileoutputformat.compress=true
该语句是mapreduce最终的输出端配置支持压缩
-Dmapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzopCodec
该语句是压缩文件的形式
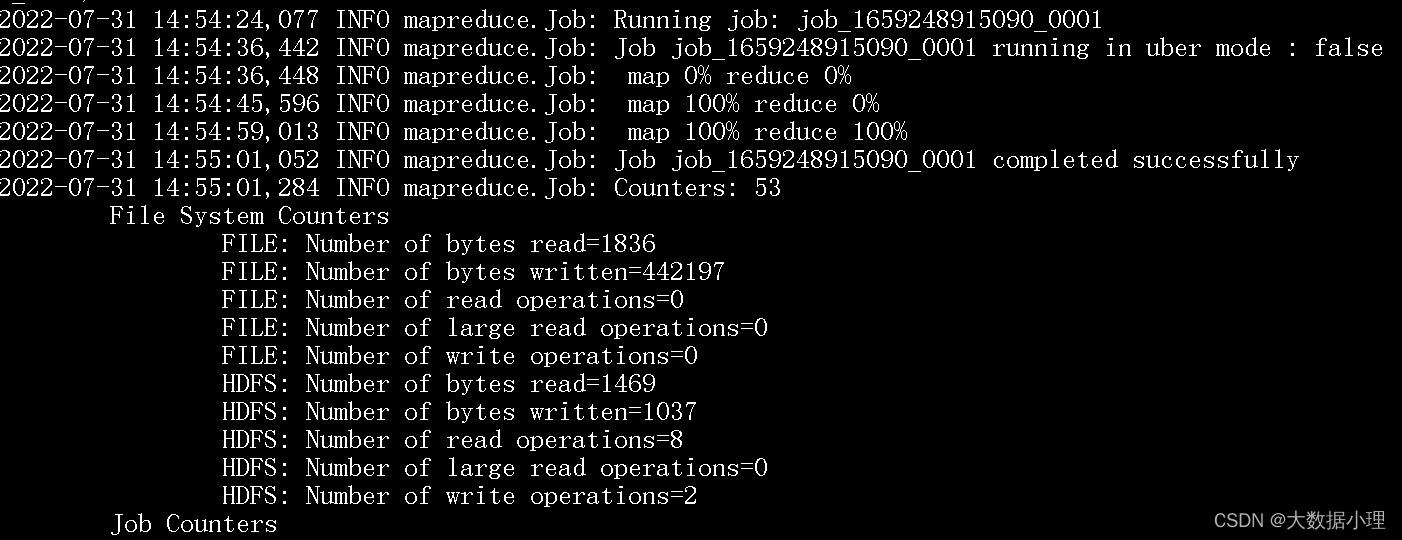
执行成功
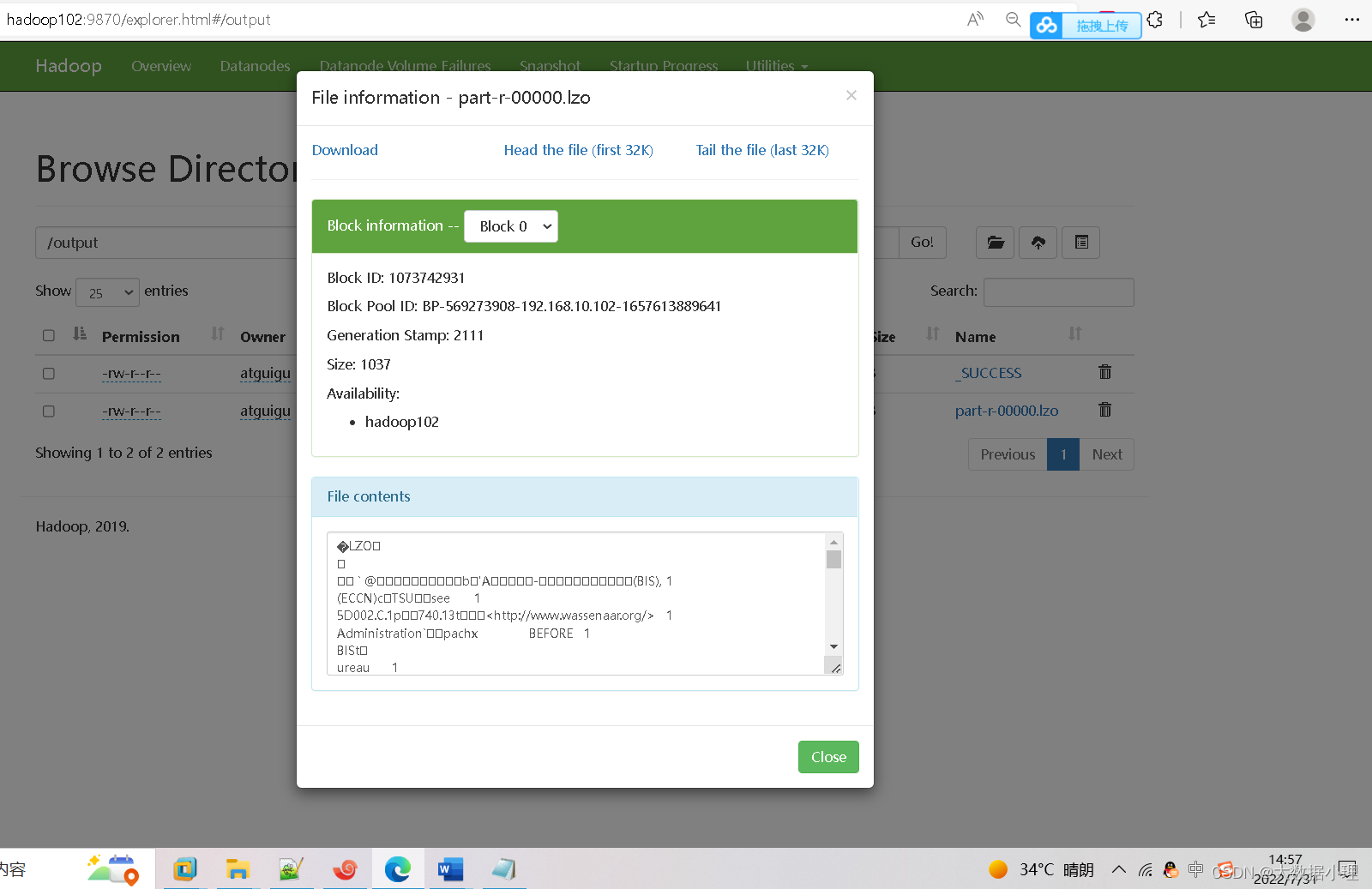
/output中输出压缩的文件


















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











