






 本文探讨了实用推理型Agent,强调了理论推理与实用推理在决策过程中的分工,分别涉及信念影响、慎思(愿望与意图)和手段-目的推理。文章通过实例和实验展示了在不同环境条件下,如静态和动态环境,不同类型承诺策略(如盲目、专一和坦率)对Agent性能的影响。
本文探讨了实用推理型Agent,强调了理论推理与实用推理在决策过程中的分工,分别涉及信念影响、慎思(愿望与意图)和手段-目的推理。文章通过实例和实验展示了在不同环境条件下,如静态和动态环境,不同类型承诺策略(如盲目、专一和坦率)对Agent性能的影响。
4.0 前言
Agent起作用,不仅仅是逻辑推理的一种、一个过程,还有其他过程在起作用。为了建立贴合实际的Agent,我们需要提出一种新的概念的模型。这就是实用推理型Agent。
4.1 推理分两步
这种Agent把推理的过程分为了两步,一步是理论推理,另一步是实用推理。
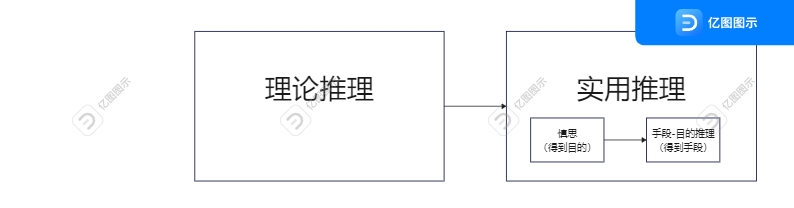
理论推理之影响信念,它不导致行动,比如如果相信所有的人是要死的,并且相信Socrates是人,则一般可以得出结论Socrates是要死的,借用一句早期流行的网络用语,知道了这个,“然并卵”。
实用推理会导致行动,它包括两个过程,前一个决定行动的结果应该是什么样的,用行话讲叫决定想要达到什么状态;后一个过程思考为了达成这个结果,每一步应该怎么做,行话讲叫决定如何实现这些状态。前者称为慎思过程,后者称为手段-目的推理。
举个例子,大学毕业后,毕业生要规划未来。慎思就是决定从事何种职业,是进入学术领域,还是工业领域。比如决定了去到学术领域,下一步手段-目的推理就是决定实现的方法,比如可以首先申请一所合适的大学读PhD,等等。
4.1.1 慎思
慎思具体来说,还分为愿望和意图。大概流程是,信念在上,然后会影响到愿望,愿望就是你潜在希望发生的事情,然后愿望之间相互竞争,如果竞争完了,你确定了,留下的明确想做什么事情就是意图。比如我今天下午想打篮球,这是愿望,你可能还想学习。但一旦你的意图确定是下午打篮球,就不会再从多个方面考虑了,下午直接去球场就行了。
意图的一些特性的总结:
1.意图驱动目标——手段推理如果形成了一个意图,那么会试图实现这个意图,除其他事情以外还包括决定怎么实现这个意图。然而,如果一特定的动作过程没能实现意图,那么一般会实现另外的意图。
2.意图的持续性没有足够的理由一般不会放弃一个意图。一般意图会一直保持,直到相信已经成功地实现了意图、相信不能实现这个意图,或者相信实现这个意图的理由已经不存在为止。
3.意图约束未来的慎思不会接受与当前意图不一致的选择。
4.意图影响作为未来实用推理的信念如果采纳一个意图,那么可以根据要实现这个意图的假设进行规划。因为,如果有意图实现某个状态,同时相信不能实现它,那么我是不理性的。
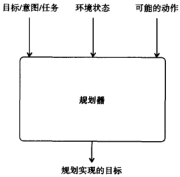
4.2 手段-目的推理
大概可以等同于规划,规划一般要思考三个方面,就是作为过程要考虑3个输入:
1.日标、意图或者(根据第2章的术语)任务。这是Agent希望实现的(实现型任务的情况,参见第2章),或者Agent希望保持或者避免的状态(维护型任务的情况,参见第2章)。
2.当前的环境状态——Agent的信念。
3.Agent可以采取的动作。
输出就是一个规划,一系列动作。
第一个实际的规划器是Fikes在20世纪60年代后期和20世纪70年代早期开发的STRIPS系统(Fikes and Nilsson,1971).STRIPS由两个基本部件——世界模型和动作模式组成。世界模型用一阶逐辑的集合表示()就是之前的慎思或者慎思加理论推理吧),而动作模式就负责规划了。这个STRIPS可老牛逼了,几乎所有已经实现的规划器都采用”STRIPS”的动作或它的变形。不过它效率有点低,“STRIPS规划算法是基于找到世界的当前状态和目标状态的“不同”的原理,并且通过采取行动减少这些差别。遗懿的是,这已被证明是形成规划的低效率的过程,因为STRIPS在低层次的规划细节中有“迷路”的趋势。”
下面简单介绍一下规划的例子。
4.2.1 规划的例子:积木世界
直接贴书上原文图片了,因为都是公式推理:




注意,在这里plan没要求Agent参与规划的产生,许多已经实现的实用推理Agent也一般不是从头构建一个规划,而是预先有一个规划集合。
4.3 实现实用推理Agent
伪代码如下:

Agent的逻辑是:
- 观察世界,更新信念。
- 通过慎思过程决定要实现的意图(慎思过程是通过首先决定提供的选择,然后通过过滤实现的)。
- 使用手段-目的推理找到实现这些意图的规划。
- 执行规划。
然而,由于一些考虑使这一基本的控制循环是复杂的。第一个就是要一起考虑慎思和规划,也即目的和手段,也就是说,咱要来综合考虑目的-手段推理这个过程。
先看个小故事:(原文哦)

前面说过,意图可能不能实现了,或者不信能被实现了。又或者,实现了之后该干啥呢?所以有3种策略:
- 盲目承诺 盲目承诺的Agent将一直维持一个意图,直到它相信这个意图真的已经实现为止。盲目承诺有时也称为狂热的承诺。
- 专一承诺 专一承诺的Agent将一直维持一个意图,直到它相信这个意图已经实现,或者已经不可能实现这个意图为止。
- 坦率承诺 坦率承诺的Agent将维持一个意图,只要它相信这个意图仍可能实现。
Agent用来决定什么时候以及如何放弃意图的机制称为承诺策略。
所以你看4.3是什么策略?Agent将维持对意图的承诺直到(i)它相信意图已经实现;(ii)它相信意图不可能实现;(iii)规划全部执行完毕。这是专一承诺。
不过问题又来了,就是什么时候停下来思考,慎思目的呢?不停下来思考,一直做,就很盲目;做之前总是想来想去,又很纠结。
其实吧,如果你所处的事态变化不大,直接莽,干就完了!如果形式风起云涌,波谲云诡,那自然是需要谨慎再谨慎了。这一点,后面介绍的实验也证明了。
不过,现实情况下,为了在承诺的程度和承诺的重新考虑之间有碰撞,最好有一种折中的方案。图4.3就引入了一个reconsider。
我们再来考虑reconsider的有效性:

注意,有一个重要假设:reconsider的开销远远小于慎思的花费。
然后,就介绍到权衡Agent重新思考的程度的实验了:David Kinny和Michael Georgeff在用BDI Agent系统进行的一系列实验中研究了权衡的性质(Kinny and Georgeff, 1991)。David Kinny和Michael Georgeff研究的目的是:
(1)评价在仿真环境中用实验测量Agent有效性的可行性;(2)研究目标的承诺对有效的Agent行为的贡献如何;(3)比较不同策略对变化做出反应的特点。
(Kinny and Georgeff, 1991, p.82)
有两种策略:鲁莽的Agent和谨慎的Agent。鲁莽就是完全不思考,干就完事了;谨慎差不多是每次都停下来思考,再开始做。这种特性用鲁莽程度来定义,它们确定了在重新考虑它的意图以前,Agent执行的最大规划步数。
还有环境的变化率,如果世界的变化速度为1,那么每次Agent循环一次,环境的改变不会超过一次。如果世界的变化速度为2,则Agent循环一次,环境改变两次,等等。
至于Agent的性能,则是用Agent有的意图与Agent在实现的的意图的比率来测量。如果有效性是1,则Agent实现了所有的意图。如果有效性是0,则Agent没有实现它的任何意图。
这个实验得出的结论如下:
- 如果世界的变化速度低(即环境变化不快),那么,卤葬的Agent比谨慎的Agent做得好。这是因为谨慎的Agent要花费时间重新考虑它们的承诺,而卤葬的Agent则忙于推进它们的工作一一实现它们的意图。
- 如果世界变化的速度高(即环境改变频繁),那么,谨慎的Agent胜过卤莽的Agent。这是因为它们能发现意图什么时候消失,并且当偶然的运气和新的机会出现时,能利用它们。
所以,静态环境,对意图强承诺的Agent会做的更好。但在动态环境,改变意图的反应能力变得更为重要,谨慎承诺的Agent将会比鲁莽的Agent做得更好。
4.4 HOMER:一个规划Agent
简介与结构
下面展示一个由Vere和BIckmore在1990研究出的Agent。它的结构如下图。大家可以自行判断一下它的哪些部分是理论推理,哪些是实用推理。实用推理的结构中,哪些是慎思,哪些是手段-目的推理。

使用案例
下面是一些与HOMER的会话例子:
用户开始问HOMER在它的前面看到了什么。
- USER:你前面有什么?
- HOMER:一个原木。
- USER:你拥有这个原木吗?
- HOMER:不,我没有这个原木。
用户然后告诉HOMER它拥有这个原木,这是一个新的信息,因此HOMER表示惊讶。
- USER:这个原木属于你。
- HOMER:哦。
这时,用户告诉HOMER转身,使它不能再看到原木,并且当原木不在HOMER的视线中时移走原木。当它转回来时,HOMER以为能看到原木,并且表示了惊讶。
- USER:转过身去。
- HOMER:好,我转过去。
- 【移走原木】
- USER:转回来。
- HOMER:好,我正在转。
- HOMER:我的原木没有了!
在下面的对话中,用户给HOMER一个任务去完成:
- USER:下个星期六下午9点把行李放到游艇上。
- HOMER:好。
HOMER然后为这个任务产生一个适当的规划。当问起星期六的规划时,HOMER表示它已经知道走到游艇要花一些时间。
- USER:下个星期六你要去游艇吗?
- HOMER:是。
- USER:什么时间?
- HOMER:下午8:56
4.5 过程推理系统
简介
过程推理系统(PRS)最初是由Michael Georgeff和Amy Lansky在Stanford Research研究所开发的,它可能是第一个显式地嵌人信念-愿望-意图模式的Agent结构。截止书成之日,它已经开发了很久,有了很多应用,包括称为OASS的航空运输控制系统(当前正在悉尼机场进行现场实验)、澳大利亚皇家空军的称为SWARMM的仿真系统,以及称为SPOC(Single Point of Contact)的商业过程管理系统(当前正在被Agentis Solution公司推向市场,Georgeff and Rao,1996)。
结构
PRS结构如图。它也常被称为信念-愿望-意图(BDI)结构。

PRS也是用的规划库,而不是第一性原理。它的规划包含以下元素:
- 目标——规划的后件。
- 上下文——规划的前件(前提条件)。
- 内容——规划的“方法”部分,即要执行的动作序列。
流程
流程是这样的:
首先,PRS有一个规划集、初始的信念。信念用Prolog事实的形式表示,基本上是一阶逻辑的原子,就像演绎Agent中看到的形式一样。一般还有一个顶层目标,顶层目标和Java、C中的main函数一样。
开启Agent后,目标被推入一个堆栈叫意图堆栈,里面包含所有没有实现的目标。找以栈顶目标为后件的规划,在这些规划中再找满足信念的。注意结合前面所学,找的其实是两种条件的:(i)可以实现这个目标,(ii)满足前提条件,这样就选好了。(参考前面给的option函数)
前面可以看到PRS的慎思过程,不过,PRS有几种竞争的慎思模式。最初设计的是用元级规划,字面上的意思是关于规划的规划,它可以在执行时修改Agent的意图结构。还有一种方法,就是用到效用(也参考前面我的文章《多Agent系统引论》第2章 智能Agent 小结②)。
然后,规划的内容方面也有所不同,动作的组织格式有特点。除了动作,还可以包含目标——就是说,在特定的时刻包含一个目标时,这个目标在其他规划执行前会实现。同时,PRS还可以有目标的析取(实现a或者实现b,实现c并且实现d),以及循环(一直实现x直到出现y),等等。
回到步骤,按次序依次执行选择的规划,包括把下一步的目标推入意图堆栈,对于这些目标又要依次找出规划,单个动作直接做时,过程结束。但规划失败了,还可以找另外的规划。
例子
给出Jam系统的片段(Huber,1999)。Jam是PRS的第二代系统,用Java实现的。与

积木世界的例子一样,现在有一个顶层目标,实现blocks_stacked。初始信念在FACTS中,如果没错,那就是说环境就是这样,Block5在Block4上面,Block4在Block3上面……
按流程来:
把blocks_stacked推入意图堆栈中。然后为这个目标规划(“顶层规划”)。这个规划上下文为空,即说这个为真,可以直接执行。
然后把下面的目标推入意图堆栈了:
![]()
这就是一个FACT,所以立马实现了。于是推第二个:
![]()
这个就要“堆积空积木”,执行,又得产生子规划:首先他们俩上面得为空的,所以又要“清空积木”,清block2和block3 。
4.6 注释和进一步阅读
关于BDI(信念-愿望-意图)模型
建立的过程
Georgeff(1999)可以看到最初的BDI模型的一些见解。
20世纪80年代中期,在Stanford Research研究所,Michael Bratman, Phil Cohen, Michael Georgeff, David Israel, Kurt Konolige和Martha Pollack等做了理性Agent课题的工作。
Bratman(1987),这位哲学家提出了实用推理理论,是BDI的原型,这一理论集中讨论了意图在实用推理中的作用问题。
Bratman(1988)给出了BDI模型的概念框架,文中同时描述了一个称为IRMA的具体的BDI Agent结构。
与本书的出入
本章关于BDI模型的描述取自Bratman等(1988),以及Rao和Georgeff(1992),但是并不完全与这两个文献的描述一样。最显著的差别是这里没有包括Bratman等(1988)中描述的“过滤覆盖”机制的概念,还假设规划是动作的线性序列(这是关于规划的非常“传统的”观点),而不是PRS中使用的目标的层次结构的集合。
关于PRS系统
开发
Georgeff and Lansky(1987), Georgeff and Ingrand(1989)开发出来PRS。
80年代中期以来的多次重现
d'Inverno etc.(1997)澳大利亚人工智能研究所的DMARS系统
Huber(1999)Michigan大学用C++实现的UM-PRS,以及一个称为Jam的Java版本。
Busetta etc.(2000)Jack是可用的商业化的程序设计语言,在Java语言之上扩展了一些BDI特性。
关于规划
Pollack(1992)是关于BDI模型的一个出色的讨论,还得了计算机与思维奖。
Pollack(1990)集中讨论了“作为方法的规划”和“作为思维状态的规划”。
除了规划其他的方案
软件结构
Wooldridge and Jennings(1995)
Brooks(1999)
其他实用推理风格
Fischer etc.(1996)
Jung(1999)
Mora(1990)
Busetta etc.(2000)
BDI形式化
Rao and Georgeff(1991a), Rao etc.(1992), Rao and Georgeff(1991b), Rao and Georgeff(1992), Rao and Georgeff(1993), Rao(1996b)Anand Rao和Michael Georgeff提出了一系列BDI逻辑,他们基于BDI的实用推理Agent的性质进行公理化。
Haddadi(1996)推广了上述,使之可以处理Agent之间的通信。
4.6.1 课堂阅读:Bratman等(1998)
这是一篇有意思的深刻的文章,没有太多的技术内容。它引人了实用推理Agnt的RMA结构,对后来的系统设计有很大的影响。
习题
1.[1级]
想像一个移动机器人,可以在办公环境中移动。最终,这个机器人必须根据“启动电机”等非常低层的指令控制。开发STRIPS操作符表示这些特性容易吗?
2.[2级]
回忆前面章节中讨论的真空吸尘器的例子,使用STRIPS的符号形式化表示这个Agent可提供的操作。
3.[2级]
考虑一个必须从一个地点移动到另一个地点的Agent,这个Agent从一个地点收集并移动物品。这个Aget可以被出租车、公共汽车、自行车或者卡车装运。
用STRIPS符号形式化对这个Aget的可能的操作(用出租车、卡车等搬运)(提示:前提条件是有钱或者有能量)。
4.[3级]
阅读Kinny和Georgeff的文章(1991),并且用你自己选择的程序设计语言实现这些实验(这并没有想像的那样困难:最多需要一两天的时间应该可以完成)。现在,进行Kinny和Georgeff的文章(I991)中描述的实验,看看你是不是能得到相同的结果。
5.[3级]
基于前一个问题的基础,研究下面的问题:
减少对Agent性能的感知能力的效果 思路是减少Agent可以看到的环境,直到这个Agent只能看到它自己所在的方格为止。“自由”规划能对这种不能看得很远有所补偿吗?
非确定性动作的效果如果允许动作是非确定性的(因此,如果试图从一个方格移动到另一个方格,这个Aget事实上移动到完全不同的方格中去是有一个确定的概率),这对Agent的有效性有什么影响?















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









