







 本文介绍了图像分类的基础,从特征工程到深度学习的发展,重点讲述了卷积神经网络(如AlexNet、VGG、ResNet)和Transformer在图像识别中的应用。深度学习通过自动学习特征,显著提升了图像分类的准确性。ResNet因其残差学习和多级结构成为CV领域的重要模型。近年来,Transformer在NLP领域的成功也逐渐被引入到计算机视觉中,如Swin Transformer和ConvNeXt,展现出强大的性能。
本文介绍了图像分类的基础,从特征工程到深度学习的发展,重点讲述了卷积神经网络(如AlexNet、VGG、ResNet)和Transformer在图像识别中的应用。深度学习通过自动学习特征,显著提升了图像分类的准确性。ResNet因其残差学习和多级结构成为CV领域的重要模型。近年来,Transformer在NLP领域的成功也逐渐被引入到计算机视觉中,如Swin Transformer和ConvNeXt,展现出强大的性能。
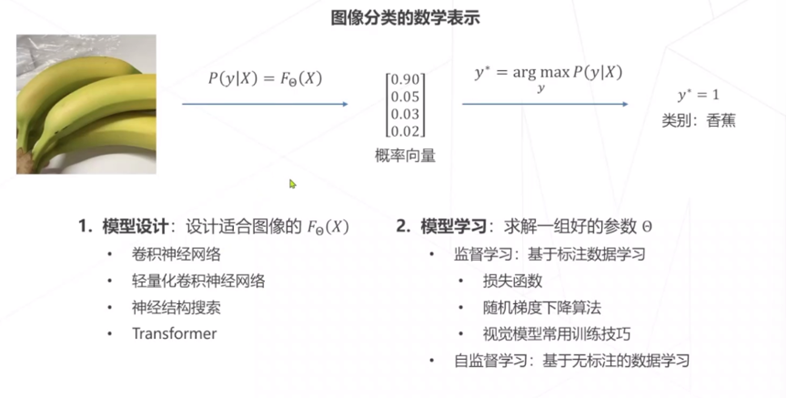
图像是像素构成的数组。
收集数据-定义模型-训练-预测 图像是像素构成的数组。
收集数据-定义模型-训练-预测图片
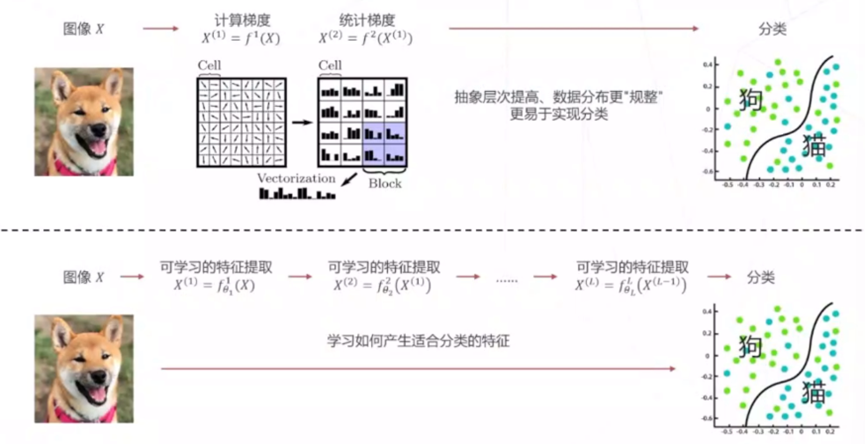
特征工程:设计算法找图像的方向梯度,找到图像的基本特征,保留了一些信息
这种方法在2011年以前是主流的,但是达到了一个瓶颈
深度学习:学习如何产生适合分类的特征
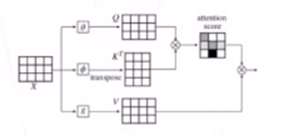
实现一步特征提取:
卷积 卷积神经网络
特征图像和图像一样有二维结构,,后层特征为空间邻域内前层特征的加权求和。
多头注意力 Transformer
2012年的AlexNet首次使用深度学习方法,把图像分类质量提高了一个层次
2014 VGG Google Net 增加网络层数提升精度
VGG把卷积核从5x5->3x3
GN 使用了一个Inception的模块,节省了很多参数
但是增加卷积层不能无限增加,有瓶颈
残差学习
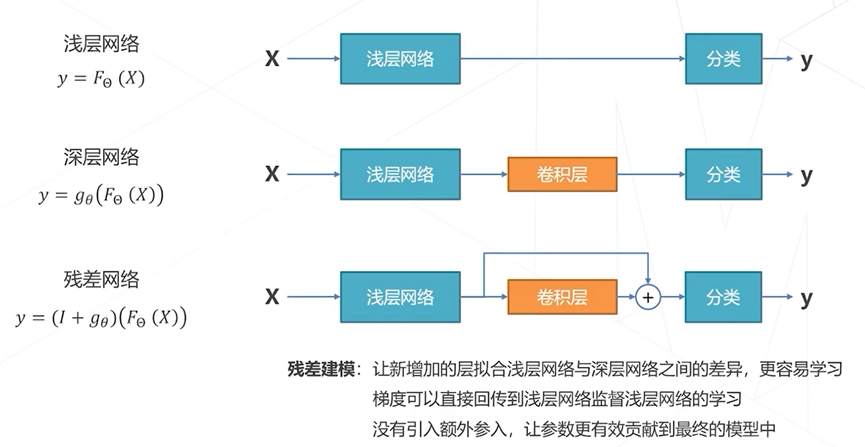
ResNet 以VGG为基础,保持多级结构,增加层数,增加跨层连接
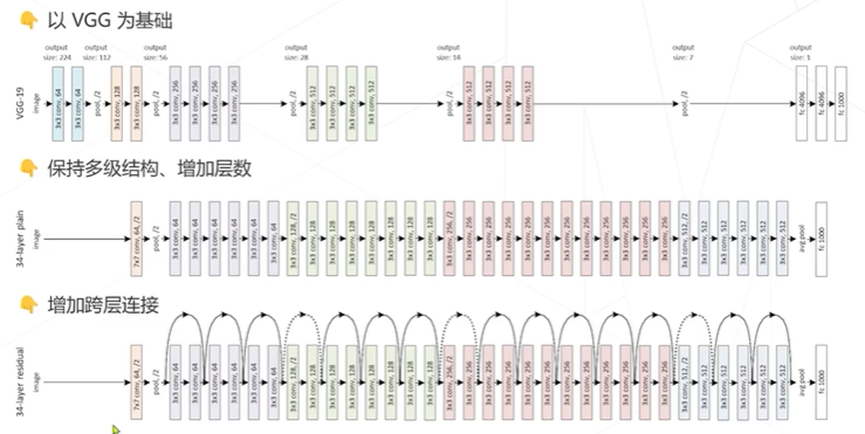
ResNet是CV领域影响力最大,使用最广泛的模型结构,获得CVPR2016最佳论文奖
为什么ResNet这么强?
1. 是深浅模型的集成,残差网络每添加一个块,都会是路径翻倍
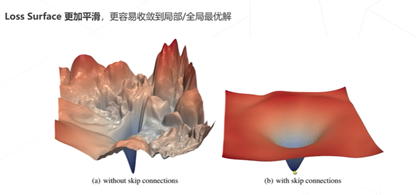
2. 残差链接让损失曲面更平滑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









