








对比于之前所学的MySQL和hive以及Spark,SparkSQL存在不可替代的高性能,SparkSQL在很多公司也是进行使用的,所以就是针对于代码进行一个整理的过程,留下一个熟悉代码的过程.Spark内核是真的难以理解,也就写写SQL比较简单.
- 针对于Spark环境的理解(资料的2.6节)
构建之前需要在xml文件之中添加依赖.(注意:这里的依赖的顺序是不可以颠倒的,否则会出现报错的情况,具体原因自己理解)
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>写一段json格式的代码进行案例操作:(名称为user.json),实际的文件会出现标红的问题,并不是出现了错误,这里应当注意.
{"id":1001,"age":20,"name":"qiaofeng"}
{"id":1002,"age":19,"name":"xuzhu"}
{"id":1003,"age":18,"name":"duanyu"}
为什么json格式是上面的样式???
SparkSQL读取文件采用的是Hadoop的方式,按行进行读取,需要的每一行数据都是符合json格式.
测试代码段如下所示:
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkSQL01 {
def main(args: Array[String]): Unit = {
/* 方式一:进行builder构建起进行设计者模式
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("SparkSQL")
.getOrCreate()
*/
//方式二:使用普通模式进行相应的调用过程
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//import sparkSession.implicits._
//TODO: 1.准备json格式的文件
//json文件要求:文件的内容是符合json文件的格式
val dataFrame: DataFrame = sparkSession.read.json("user.json")
//TODO: 2.将DataFrame转换为表进行SQL访问
dataFrame.createOrReplaceTempView("user")
//在程序之中写入sql是不方便的,因此是使用多个引号进行一个操作的过程
sparkSession.sql(
"""
|select
|*
|from
|user
""".stripMargin
).show
sparkSession.stop()
}
}
- DSL&SQL
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkSQL01 {
def main(args: Array[String]): Unit = {
//方式二:使用普通模式进行相应的调用过程
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//import sparkSession.implicits._
//TODO: 1.准备json格式的文件
//json文件要求:文件的内容是符合json文件的格式
val df: DataFrame = spark.read.json("user.json")
//下面进行隐式转换之中spark不是包名,是SparkSession的对象名称
// 使用的scala中的对象导入语法
//这个对象必须是val类型的,var类型是不可以的
import spark.implicits._//这里的引入使得在进行相应的操作的时候不进行标红[这一行的代码必须是在这里的]
//TODO: 2.将DataFrame转换为表进行SQL访问
//TODO 采用另外一种方式进行读取
// df.select("id").show//注意这里必须是存在的一列,讲其中的一列进行读取
df.select($"age"+1).show//上面的隐式转换操作进行注意的地方就是这里
spark.stop()
}
}
- 数据模型之间的转换(这个操作可以在linux端之间进行操作,下面是在IDEA端进行操作的过程)
数据模型的转换表是如下所示:

import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._//不管是以后有没有用到都是要进行一个添加的过程
//RDD => DataFrame
val rdd = spark.sparkContext.makeRDD(List(
(1,"zhangsan",30),
(2,"lisi",40),
(3,"wangwu",50),
))
//将DF转换为DS的时候,设定类型时,类型应该是与该结构的字段想匹配的
//讲DF转换为DS的时候,类型的属性可以比字段数少
val df: DataFrame = rdd.toDF("id","name","age")
//DataFrame => Dataset
val ds: Dataset[User] = df.as[User]
//Dataset => DataFrame
val df1: DataFrame = ds.toDF()//toDF之中是可以传入相应的参数,只是将上面的列名进行一个转换的过程,动态转换
//DataFrame => RDD
val rdd1: RDD[Row] = df1.rdd
//RDD => Dataset
val ds2: Dataset[User] = rdd.map {
case (id, name, age) => {
User(id, name, age)
}
}.toDS()
//Dataset => RDD
val rdd2: RDD[User] = ds2.rdd
spark.stop()
}
case class User(id:Int,name: String,age:Int)//样例类
//这里的样例类的顺序如果要是进行改变的话,实际是不改变的 val df: DataFrame = rdd.toDF("id","name","age")已经定义好了
//如果要是这里的定义跟前面是不一样的,将出现错误
//将里面的定义删除掉一个也是可以出现正确的结果的,只是展示的时候是正确的
}
- DataFrame和DataSet的区别
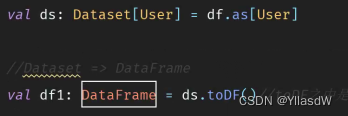
可以见到,DataFrame和DataSet的颜色是不一样的,但是DataFrame的颜色和String是一样的,点进源码之中可以看到![]() DataFrame就是DataSet的一个别名.
DataFrame就是DataSet的一个别名.
DataFrame就是DataSet的一个特例.
- UDF函数(资料的2.7节)
UDF函数的含义:在SQL之中使用自定义的函数,完成逻辑的实现

import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._//不管是以后有没有用到都是要进行一个添加的过程
val df: DataFrame = spark.read.json("user.json")
df.createOrReplaceTempView("user")
//TODO UDF:进行一个逻辑的自定义的过程
spark.udf.register("prefixName",(name:String)=>{
"Name:" + name
})
//注意这里sql之中的想加是进行数字的相加并不是进行一个字符串的加
//mysql => concat(s1,s2,s3)
//oracle => s1 // s2 //s3
spark.sql(
"""
|select
|id,age,prefixName(name)
|from
|user
""".stripMargin
)
spark.stop()
}
case class User(id:Int,name: String,age:Int)//样例类
//这里的样例类的顺序如果要是进行改变的话,实际是不改变的 val df: DataFrame = rdd.toDF("id","name","age")已经定义好了
//如果要是这里的定义跟前面是不一样的,将出现错误
//将里面的定义删除掉一个也是可以出现正确的结果的,只是展示的时候是正确的
}
- UDAF函数
这里的A是代表聚合的含义.
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, IntegerType, StructField, StructType}
import org.apache.spark.sql._
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._//不管是以后有没有用到都是要进行一个添加的过程
val df: DataFrame = spark.read.json("user.json")
df.createOrReplaceTempView("user")
//TODO UDAF:使用一个聚合逻辑进行处理,这里相应的方法见后面的逻辑
spark.udf.register("avgAge",new AvgAgeUDAF)
//注意这里sql之中的想加是进行数字的相加并不是进行一个字符串的加
//mysql => concat(s1,s2,s3)
//oracle => s1 // s2 //s3
spark.sql(
"""
|select
|avgAge(age)
|from
|user
""".stripMargin
)
spark.stop()
}
//TODO 自定义聚合函数
//1.继承类
//2.重写方法
class AvgAgeUDAF extends UserDefinedAggregateFunction{
//TODO 输入的数据结构
override def inputSchema: StructType = {//样例类
StructType(
Array(
StructField("age",IntegerType)
)
)
}
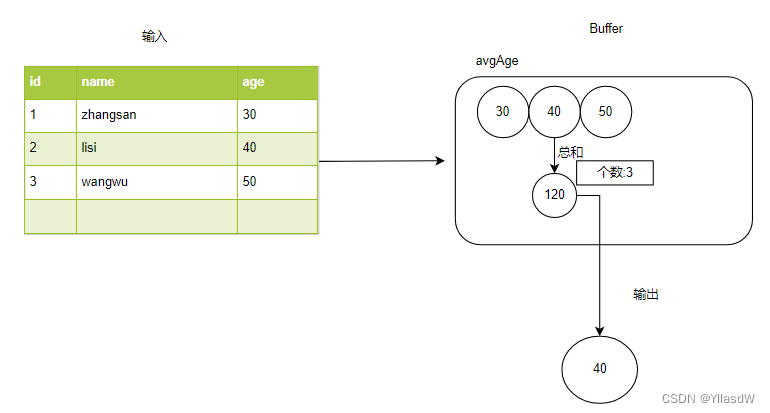
//TODO 在上面的数据之中buffer之中的是缓冲区之中的东西 120 数量3
//TODO 缓冲区之中的数据结构
override def bufferSchema: StructType = {//样例类
StructType(
Array(
StructField("total",IntegerType),
StructField("count",IntegerType)
)
)
}
//TODO 输出的数据结构
override def dataType: DataType = IntegerType
//TODO 稳定性
override def deterministic: Boolean = true
//TODO 缓冲区的初始化
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer.update(0,0)
buffer.update(1,0)
}
//TODO 更新:使用输入的值进行更新缓冲区
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
buffer.update(0,buffer.getInt(0)+input.getInt(0))//旧的值和新的值的共同作用
buffer.update(0,buffer.getInt(1)+1)
}
//TODO 将多个缓冲区的书进行合并
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1.update(0,buffer1.getInt(0) + buffer2.getInt(0))//旧的值和新的值的共同作用
buffer1.update(0,buffer1.getInt(1) + buffer2.getInt(1))
}
//TODO 计算结果
override def evaluate(buffer: Row): Any = {
buffer.getInt(0) / buffer.getInt(1)
}
}
}
- UDAF函数的实现思路
上述代码的RDD实现过程
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, IntegerType, StructField, StructType}
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate() //不管是以后有没有用到都是要进行一个添加的过程
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List(
(1, "张三", 30),
(2, "lisi", 40),
(3, "wangwu", 50)
))
val rdd1: RDD[Int] = rdd.map(_._3)
val avg = rdd1.sum / rdd1.count()
println(avg)
spark.stop()
}
}
为何在实际的使用过程之中,我们不采用上述的代码,因为实际应用的时候,上面的rdd重复执行了,并且sum和count是行动算子,就会有两个job,效率很浪费.
解决上述的方式:方式一
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, IntegerType, StructField, StructType}
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate() //不管是以后有没有用到都是要进行一个添加的过程
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List(
(1, "张三", 30),
(2, "lisi", 40),
(3, "wangwu", 50)
))
//(30,1)
//(40,2)
//(50,1)
val tuple: (Int, Int) = rdd.map {
case (id, name, age) => {
(age, 1)
}
}.reduce(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val jieguo = tuple._1 / tuple._2
println((Int)(jieguo))
spark.stop()
}
}
方式二:reudceByKey(独有的优势)
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, IntegerType, StructField, StructType}
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate() //不管是以后有没有用到都是要进行一个添加的过程
val rdd: RDD[(Int, String, Int)] = spark.sparkContext.makeRDD(List(
(1, "张三", 30),
(2, "lisi", 40),
(3, "wangwu", 50)
))
//(30,1)
//(40,2)
//(50,1)
val result: RDD[(Int, (Int, Int))] = rdd.map {
case (id, name, age) => {
(1, (age, 1))
}
}.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val avg = result.map{
case(one,(total,count))=> {
total / count
}
}.collect
println(avg)
spark.stop()
}
}
通过上面的代码更好的理解缓冲区的概念.
- UDAF函数-强类型操作
UserDefinedAggregateFunction是弱类型的,
UserDefinedAggregateFunction是强类型的,3.0.0之后的可以使用
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, IntegerType, StructField, StructType}
import org.apache.spark.sql._
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._//不管是以后有没有用到都是要进行一个添加的过程
val df: DataFrame = spark.read.json("user.json")
df.createOrReplaceTempView("user")
//TODO UDAF:注意这个地方的写法就是与之前的写法是不一样的
spark.udf.register("avgAge",functions.udaf(new AvgAgeUDAF))
//注意这里sql之中的想加是进行数字的相加并不是进行一个字符串的加
//mysql => concat(s1,s2,s3)
//oracle => s1 // s2 //s3
spark.sql(
"""
|select
|avgAge(age)
|from
|user
""".stripMargin
)
spark.stop()
}
case class AvgBuffer(var total:Int,var count:Int)
//TODO 自定义聚合函数(强类型)
//1.继承类[-in,buf,out]
//2.定义泛型
//IN
//BUF
//OUT
class AvgAgeUDAF extends Aggregator[Int,AvgBuffer,Int]{//[]之中是相应的类型
//缓冲区的初始化
override def zero: AvgBuffer = {
AvgBuffer(0,0)
}
//将输入的值聚合到缓冲区
override def reduce(b: AvgBuffer, a: Int): AvgBuffer =
{
b.total += a
b.count += 1
b
}
//缓冲区的合并
override def merge(b1: AvgBuffer, b2: AvgBuffer): AvgBuffer = {
b1.total += b2.total
b1.count += b2.count
b1
}
//计算结果
override def finish(b: AvgBuffer): Int = {
b.total/b.count
}
//缓冲区的类型编码,固定写法(自定义的类型)
override def bufferEncoder: Encoder[AvgBuffer] = Encoders.product //当这里的类型是自己定义的时候,固定的写法就是这个样子
override def outputEncoder: Encoder[Int] = Encoders.scalaInt
}
}
强类型与弱类型的比较,其更加直观,顺序更好理解.
- 旧版本的强类型的使用
有的公司仍然是使用的旧版的Aggregete,是不支持SQL的,为了解决这个问题,代码是如下所示:(
注意:在读取文件的时候,数字就不再是Int类型,而是相应的Long类型)
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, IntegerType, StructField, StructType}
import org.apache.spark.sql._
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQl")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._//不管是以后有没有用到都是要进行一个添加的过程
val df: DataFrame = spark.read.json("user.json")
df.createOrReplaceTempView("user")
//TODO UDAF:Aggregator类型在早起的版本之中是不能够应用SQL
// 将一行的数据作为整体(对象)进行聚合操作
//SQL是弱类型
//DSL是强类型
val ds: Dataset[User] = df.as[User]
//将强类型的UDAF函数作为查询zaiDSL语句之中进行洗那个赢得执行
val udaf = new AvgAgeUDAF
val column: Any = udaf.toColumn
ds.select().show()
spark.stop()
}
case class AvgBuffer(var total:Long,var count:Long)
case class User(id:Long,name:String,age:Long)
//TODO 自定义聚合函数(强类型)
//1.继承类[-in,buf,out]
//2.定义泛型
//IN:User
//BUF
//OUT
class AvgAgeUDAF extends Aggregator[User,AvgBuffer,Long]{//[]之中是相应的类型
//缓冲区的初始化
override def zero: AvgBuffer = {
AvgBuffer(0,0)
}
//将输入的值聚合到缓冲区
override def reduce(b: AvgBuffer, user: User): AvgBuffer =
{
b.total += user.age
b.count += 1
b
}
//缓冲区的合并
override def merge(b1: AvgBuffer, b2: AvgBuffer): AvgBuffer = {
b1.total += b2.total
b1.count += b2.count
b1
}
//计算结果
override def finish(b: AvgBuffer): Long = {
b.total/b.count
}
//缓冲区的类型编码,固定写法(自定义的类型)
override def bufferEncoder: Encoder[AvgBuffer] = Encoders.product //当这里的类型是自己定义的时候,固定的写法就是这个样子
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
}
数据读取与保存-通用方法
读取
首先是进入相应的spark模式下面

<<spark
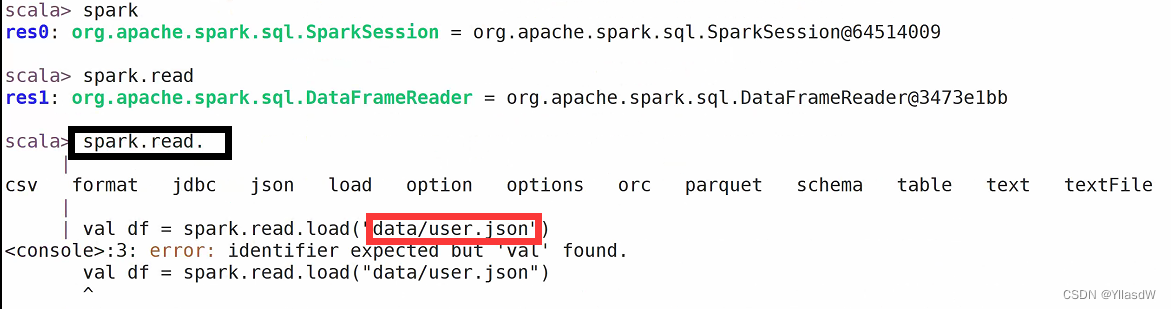 我们上面读取的是.json文件,发现是会出现报错的现象.因为spark默认读取的文件是parquet文件之中.
我们上面读取的是.json文件,发现是会出现报错的现象.因为spark默认读取的文件是parquet文件之中.
读取一个相应的parquet文件,如下所示: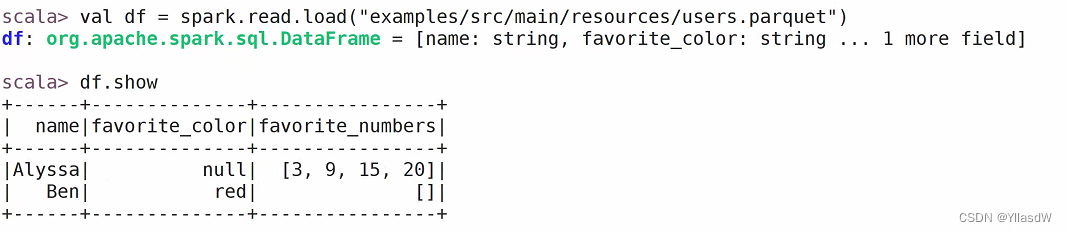
保存数据![]()
如果要是想要读取的文件是json文件的格式,需要加入一个format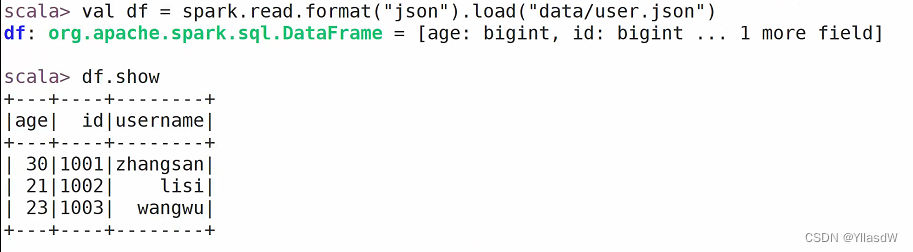
另一种方式
保存
![]()
保存的过程和读取的过程是相同的,
这里的文件保存的路径是/opt/module/spark-local![]()
操作JSON&CSV
读取json格式的文件
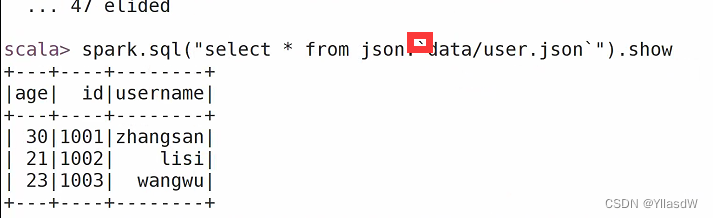
SaveMode模式,就是原始的文件是已经存在的,使用其他的方式进行改进.

CSV文件的读取

SparkSQL与MySQL联合操作
首先配置依赖信息
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>
写出相应的操作sql语句
package com.atguigu.spark.sql
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession, functions}
object SparkSQL04_Read {
def main(args: Array[String]): Unit = {
//创建SparkSession对象
val spark: SparkSession = SparkSession.builder()
.master("local[2]")
.appName("SparkSQL")
.getOrCreate()
import spark.implicits._
//读取数据
val df =
spark.read.
format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user")
.load()
//保存数据
df.write.format("jdbc")
.option("url", "jdbc:mysql://linux1:3306/spark-sql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root")
.option("password", "123123")
.option("dbtable", "user1") .mode (SaveMode.Append)
//释放资源
spark.stop()
spark.close()
}
}
操作内置hive
创建临时视图
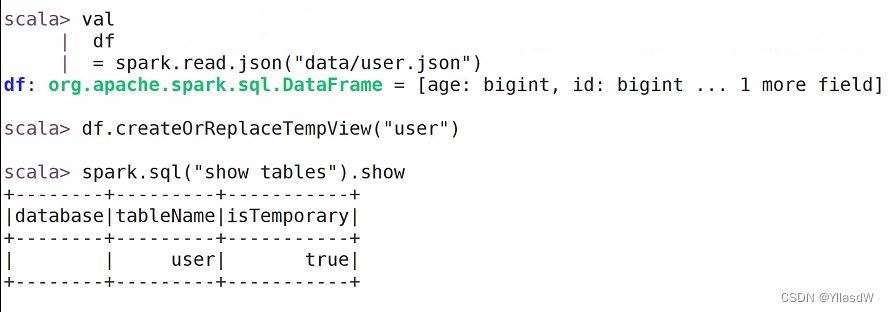
创建长时视图,可以直接访问(首先创建好一个id.txt)
 >spark.sql("select * from atguigu").show
>spark.sql("select * from atguigu").show
操作外置hive
步骤:①首先将hive之中的hive-site.xml文件复制到spark-local之中的conf/文件夹之中;②将MySQL驱动复制到conf之中;③:quit退出,重新启动
代码操作外置Hive
①首先将配置pom环境
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.27</version>
</dependency>②拷贝Hive-site.xml文件到classpath之下
③配置启用hive的支持
④增加依赖关系(MySQL)和第一步一样
package com.atguigu.spark.sql
import org.apache.spark.sql.{DataFrame, SparkSession}
object SparkSQL06_Hive {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder()
.master("local[2]")
.enableHiveSupport()//启用hive的支持
.appName("SparkSQL")
.getOrCreate()
import sparkSession.implicits._
//读取Hive数据
sparkSession.sql("select * from test.city_info")
sparkSession.close()
}
}
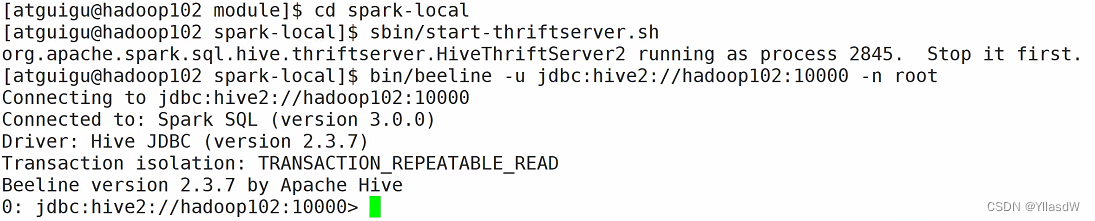
beenline操作hive
就是展示效果是比较好的,操作方式是操不多的.














 2161
2161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









